Couldn't agree more: we still don't have good solutions for scalable abstraction/concept learning from "raw" data (be it language, vision, or other sensory data). Solving this would likely unlock important new capabilities.
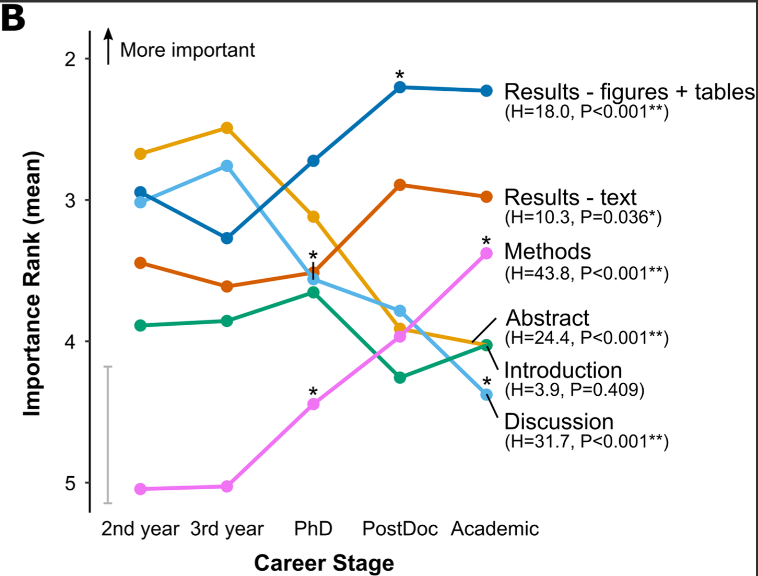
The longer people are in academia, the more they realize that when reading papers it's best to ignore Intro, Discussion etc. and just look at Methods and Results
https://t.co/EzQL7WI71Q
We often discuss if the brain does something like gradient descent. Here is me discussing the issue for @OpenNeuroMorph. I focus on exposing the weaknesses of the hypothesis as well. Should be particularly useful for newly interested people. https://t.co/pCaBdmQLKI
@gdb 💯 reminds me of MAML meta-learning (https://t.co/H9CIfVdxHd) where the objective is to find weights of a network such that any new task finetunes fast. In Software 1.0 land, equivalent is writing code such that any new desired functionality is simple and doesn't need a refactor.
@AlexanderDerve@GaryMarcus@MetaAI@ylecun Seems like people were expecting to handle a nail with a screwdriver. Let alone the ability to run your work through the model to include missing references seems valuable.