New blog post: on the million-x sample efficiency gap between AIs and humans, and whether it matters:
"The reason it is relatively easy for open source and previous laggards to catch up to within months of the frontier is that data is the real driver of progress.
And data can be easily distilled from public APIs, whereas hyper-parameters and training tricks and architectural micro-optimizations cannot - if the latter were driving most of progress, then catching up would be harder than we are observing it to be.
It is easy to forget how much data these models are trained on, and how much more it is than what we humans see in our lifetimes.
We see these AIs as a galaxy glittering with capabilities, but at their center, invisible to the naked eye, holding all the constellations together, is an unimaginably massive black hole of data."
Post in link below
this is actually insane
> be tech guy in australia
> adopt cancer riddled rescue dog, months to live
> not_going_to_give_you_up.mp4
> pay $3,000 to sequence her tumor DNA
> feed it to ChatGPT and AlphaFold
> zero background in biology
> identify mutated proteins, match them to drug targets
> design a custom mRNA cancer vaccine from scratch
> genomics professor is “gobsmacked” that some puppy lover did this on his own
> need ethics approval to administer it
> red tape takes longer than designing the vaccine
> 3 months, finally approved
> drive 10 hours to get rosie her first injection
> tumor halves
> coat gets glossy again
> dog is alive and happy
> professor: “if we can do this for a dog, why aren’t we rolling this out to humans?”
one man with a chatbot, and $3,000 just outperformed the entire pharmaceutical discovery pipeline.
we are going to cure so many diseases.
I dont think people realize how good things are going to get
It's over. Karpathy just open-sourced an autonomous AI researcher that runs 100 experiments while you sleep.
You don't write the training code anymore.
You write a prompt that tells an AI agent how to think about research.
The agent edits the code, trains a small language model for exactly five minutes, checks the score, keeps or discards the result, and loops. All night. No human in the loop.
That fixed five-minute clock is the quiet genius. No matter what the agent changes, the network size, the learning rate, the entire architecture, every run gets compared on equal footing. This turns open-ended research into a game with a clear score:
- 12 experiments per hour, ~100 overnight
- Validation loss measures how well the model predicts unseen text
- Lower score wins, everything else is fair game
The agent touches one Python file containing the full training recipe. You never open it. Instead, you program a markdown file that shapes the agent's research strategy.
Your job becomes programming the programmer, and this unlocks a strange new loop:
1. Agents run real experiments without supervision
2. Prompt quality becomes the bottleneck, not researcher hours
3. Results auto-optimize for your specific hardware
4. Anyone with one GPU can run a research lab overnight
The best AI labs won't just have the most compute.
They'll have the best instructions for agents who never sleep, never forget a failed experiment, and never stop iterating.
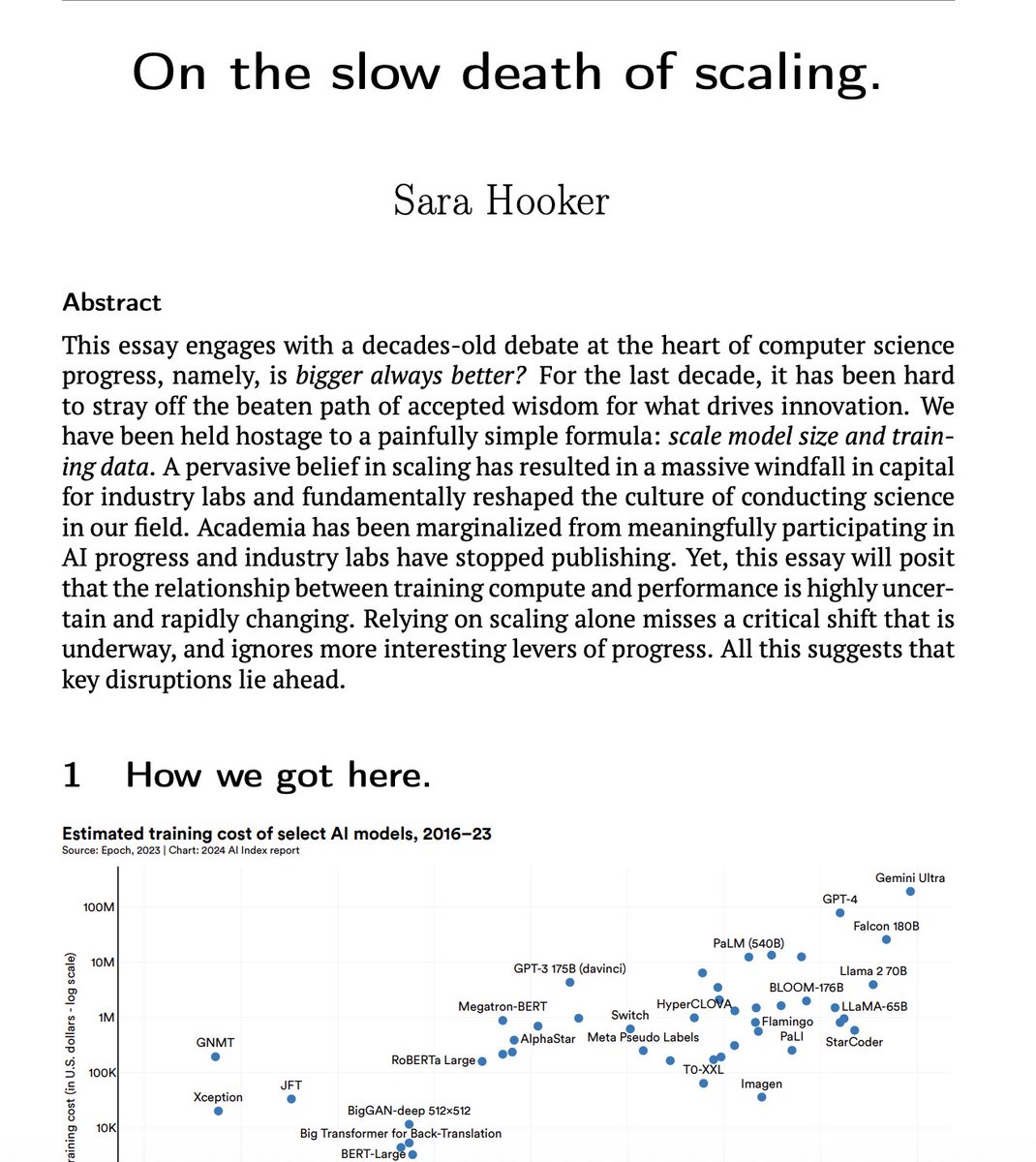
For the last decade, it has been hard to stray off the beaten path of accepted wisdom that scaling training parameters drives innovation.
However, the relationship between training compute + performance is uncertain + rapidly changing.
🥳 "Logically Consistent Language Models via Neuro-Symbolic Integration" just accepted at #ICLR2025!
We focus on instilling logical rules in LLMs with an efficient loss, leading to higher factuality & (self) consistency. How? 🧵
This is a catastrophe.
Valencia and its southern surroundings have been completely destroyed.
40-50cm of red clay, water multiple meters deep, +200 people dead.
There was more rain in 12 hours than what falls in ONE year.
🧵
# on shortification of "learning"
There are a lot of videos on YouTube/TikTok etc. that give the appearance of education, but if you look closely they are really just entertainment. This is very convenient for everyone involved : the people watching enjoy thinking they are learning (but actually they are just having fun). The people creating this content also enjoy it because fun has a much larger audience, fame and revenue. But as far as learning goes, this is a trap. This content is an epsilon away from watching the Bachelorette. It's like snacking on those "Garden Veggie Straws", which feel like you're eating healthy vegetables until you look at the ingredients.
Learning is not supposed to be fun. It doesn't have to be actively not fun either, but the primary feeling should be that of effort. It should look a lot less like that "10 minute full body" workout from your local digital media creator and a lot more like a serious session at the gym. You want the mental equivalent of sweating. It's not that the quickie doesn't do anything, it's just that it is wildly suboptimal if you actually care to learn.
I find it helpful to explicitly declare your intent up front as a sharp, binary variable in your mind. If you are consuming content: are you trying to be entertained or are you trying to learn? And if you are creating content: are you trying to entertain or are you trying to teach? You'll go down a different path in each case. Attempts to seek the stuff in between actually clamp to zero.
So for those who actually want to learn. Unless you are trying to learn something narrow and specific, close those tabs with quick blog posts. Close those tabs of "Learn XYZ in 10 minutes". Consider the opportunity cost of snacking and seek the meal - the textbooks, docs, papers, manuals, longform. Allocate a 4 hour window. Don't just read, take notes, re-read, re-phrase, process, manipulate, learn.
And for those actually trying to educate, please consider writing/recording longform, designed for someone to get "sweaty", especially in today's era of quantity over quality. Give someone a real workout. This is what I aspire to in my own educational work too. My audience will decrease. The ones that remain might not even like it. But at least we'll learn something.
What happened in the open-source AI world in August? August is traditionally a slow month...but not for AI it seems! 👇Here is a recap!
Code goes wild💻🦙
- Just 6 months after LLaMA, @MetaAI releases Code Llama, a family of LLMs for code https://t.co/1aTA37XJGd. You can now find online demos, IDE extensions, fine-tuning scripts, and much more!
- @WizardLM_AI releases WizardCoder 34B https://t.co/kQgsNtXt2x
- OctoPack: instruction tuning code LLMs https://t.co/b5yJSS52cq
- StabilityAI releases StableCode https://t.co/LTMrEf2fNQ
- DeciCoder https://t.co/JgLqudQZSt
LLMs 🧠
- Microsoft releases lida, a UI for LLMs data visualization https://t.co/USuJJ8yYEg
- Platypus family of fine-tuned models https://t.co/fpzgAA1JRt
- Qwen-7B series of pretrained and chat models for Chinese, English, and code data https://t.co/S1CRRFd0q7
- Swift Transformers - run on-device LLMs https://t.co/hKbofkD6Bo
- DSPy: framework for solving advanced tasks with LLMs https://t.co/KhlrKH6eLP
- YaRN scaling allows Llama 2 with 128 context https://t.co/4ekHagJoDM
Audio 🎷
- @MetaAI releases SeamlessM4T, which can perform speech to text, speech to speech translation, text to speech, and ASR! https://t.co/L2iITSYJag
- LLaSM: A Large Language and Speech Model https://t.co/aNZVkUjkOu
- Bark (text-to-speech) gets much faster and optimized https://t.co/km1AYvU0Wa
Diffusion World 🖌️
- LoRA the explorer for playing with cool diffusion models https://t.co/eTnnKuF63A
- AudioLDM2: text to audio/music/speech generation, and now going as fast as generating 10 seconds of audio in 1 second! https://t.co/1AoFEgt57D
- Lots of exciting ControlNet models by @diffuserslib https://t.co/fHIjGcN6RM
Computer Vision 👀
- IDEFICS: visual language model at the 80B scale https://t.co/dQ8wuN5RPz
- Qwen-VL, chat and pretrained large vision model https://t.co/xO4DdJY48Q
- Apple releases FastViT https://t.co/oLhyRr1zrA
- NASA and IBM open source a foundation geospatial model https://t.co/7KosTfRusB
- Object Detection leaderboard is launched https://t.co/MmAQ6aHYr6
And more!
- Stanford Smallvile is open sourced https://t.co/bQJ0HkJew1
- @huggingface joins the @PyTorch Foundation and achieves over 1M repositories (+$235M series D)
- Candle, minimalistic ML framework in Rust https://t.co/osif3ak0CN
- New best embedding model, BGE by BAAI https://t.co/x3Dz9pMcYu
🔴 ¡EL FUTURO DE OPENAI...!
En un nuevo post la compañía anuncia que van a centrar un 20% de sus recursos de computación en un nuevo departamento dedicado al SUPERALIGNMENT 🤖🚨
¿Qué es esto? Te lo cuento y además alguna que otro detalle curioso que he visto.
1/The call for a 6 month moratorium on making AI progress beyond GPT-4 is a terrible idea.
I'm seeing many new applications in education, healthcare, food, ... that'll help many people. Improving GPT-4 will help. Lets balance the huge value AI is creating vs. realistic risks.