Technology enthusiast. The present future will be governed by innovative technologies. Bullish on AI, Quantum Computing, Blockchain and clean energy 💪💪
Japan invented nearly every tool central banks now reach for.
Zero rates → 1999
QE → 2001
Yield curve control → 2016
Its debt is now ~240% of GDP. Double the US.
Japan's reckoning is unfolding right now — and America is walking the same path, a decade behind. Here's my take 👇
Piyasalar neden düştü? Herkes Amerika'yı konuşuyor. Asıl cevap Japonya'da.
Dün Amerika'dan güçlü bir istihdam verisi geldi. Beklenenin neredeyse iki katı.
Herkes düşüşü buna bağladı.
Borsa aşağı, altın aşağı, Bitcoin aşağı. Sebep buymuş gibi göründü.
Ama bu sadece kıvılcımdı. Asıl barut çoktan dökülmüştü.
Hem de çok daha uzakta.
Çünkü o gün yalnızca teknoloji hisseleri düşmedi. Altın da düştü, gümüş de, Bitcoin de.
Tek bir veri bunu yapamaz.
Bunu ancak hepsini birbirine bağlayan görünmez bir zincir yapabilir.
O zincirin ucu Tokyo'da.
Dikkatli okuyun.
Zincirin ilk halkası, Hürmüz Boğazı'nda.
Son aylarda İran kaynaklı gerginlik bu boğazı kilitledi. Geçişler zorlaştı. Petrol fiyatı kısa sürede 100 doların üzerine çıktı, bazı günlerde çok daha yükseğe.
Sadece o boğazdaki gerginlik, dünyanın enerji faturasını birden kabarttı.
Şimdi bu kabarmanın nereye dokunduğuna bakın. İlk bakışta petrolle hiç ilgisi yokmuş gibi duran bir yere. Yapay zekaya.
Son yılların en gözde yatırımı yapay zekaydı. Dünyanın en büyük şirketleri buraya akın etti.
Yapay zeka veri merkezlerinde büyük makineler çalışıyor. Bunlar hem çalışmak hem soğumak için durmadan elektrik tüketiyor.
Yani yapay zekanın yakıtı enerji.
Enerji pahalanınca, bu işin maliyeti de doğrudan arttı, beklenen kâr azaldı.
Bu yatırımların büyük kısmı şirketlerin kendi parasıyla değil, ödünç parayla yapıldı.
Hem de dünyanın en ucuz parasıyla. Japonya'dan gelen parayla.
Burada durup şunu anlamak gerekiyor. Çünkü bütün hikâyenin temeli bu.
Japonya'da faiz yıllarca neredeyse sıfırdı.
Akıllı oyuncular Japonya'dan bedavaya yakın yen borçlandı, o parayı bozdurup dünyanın dört bir yanında getirisi yüksek varlıklara yatırdı.
Amerikan teknoloji hisselerine, yapay zekaya, altına, Bitcoin'e.
Mantık basit.
Ucuza borçlan, yüksek getiriye yatır, aradaki farkı cebine at.
Buna carry trade deniyor.
Yani bugün ekranda gördüğünüz birçok varlığın fiyatının altında, görünmeyen bir yen borcu duruyor.
Kâr böyle daralınca, bu borç dağında ilk çatlak oluştu. Yüksek borçla bu işe girenler, çıkış kapısına bakmaya başladı.
İkinci halka, yen'in kendisinde.
Yen aylardır değer kaybediyor. Sebebini anlamak için şuraya bakmak yeterli.
Faiz farkına.
Amerika'da faiz %3.5'in üzerinde. Japonya'da ise %0.75. Arada neredeyse üç puanlık bir uçurum var.
Para suya benzer, hep daha çok kazandığı yere akar. Düşük faizli yen'i bırakır, yüksek faizli dolara koşar. Bu akış sürdükçe yen zayıflar.
Japonya bu değer kaybını durdurmak için geçtiğimiz aylarda elindeki dolarları satıp karşılığında yen topladı.
Amaç yen'in fiyatını yukarı itmekti. Nisan sonunda bir günde yaklaşık 35 milyar dolar harcadı, sonra bir kez daha denedi.
Ama o müdahaleler tutmadı. Bu kadar büyük para bile yen'i ancak birkaç gün ayakta tutabildi. Sonra düşüş kaldığı yerden devam etti. Üstelik bu yöntemin bir de sınırı var.
Japonya sonsuza kadar elindeki doları satamaz.
Sonra dün, o güçlü Amerikan istihdam verisi geldi ve işi büsbütün kilitledi.
Bu veri de tek başına bir şey yıkmaz. Asıl etkiyi insanların kafasında yarattı.
Herkes şöyle düşündü. Amerika bu güçlü ekonomiyle faizi yakında indirmez. Yani iki ülke arasındaki o faiz uçurumu yakın sürede kapanmayacak.
Yatırımcılar bu beklentiye göre pozisyon aldı. Dolara talep arttı, dolar güçlendi, yen üstündeki baskı bir kat daha büyüdü.
Müdahale tutmuyor, faiz farkı kapanmıyor. Geriye Japonya için tek bir çıkış kalıyor.
Faiz artırmak.
İşte bu yüzden tahmin piyasalarında Japonya'nın 16 Haziran'da faiz artırma ihtimali yüzde 97'ye çıktı.
İşte en kritik kısma geldik.
Japonya faiz artırınca dünya piyasaları sarsılır. Bunu piyasayı izleyen herkes bilir. Ama çoğu kişinin gözden kaçırdığı bir incelik var.
Bu sarsıntı, faiz artışından sonra değil, daha önce başlar.
Sebebi basit.
Büyük oyuncu haberi beklemez. Artışın geleceğini günler öncesinden görür ve usulca kapıya yönelir. Haber çıktığında o çoktan çıkmıştır.
Tarih bunu defalarca kanıtladı.
Japonya son iki yılda dört kez faiz artırdı, her seferinde Bitcoin sert düştü.
Mart 2024'te artırdı, yaklaşık yüzde 23.
Temmuz 2024'te artırdı, yüzde 26.
Ocak 2025'te artırdı, yüzde 31.
Aralık 2025'te artırdı, yine yaklaşık yüzde 30.
Dört artış, dört düşüş. Tesadüf diyemeyecek kadar düzenli.
En öğreticisi sonuncusuydu.
Japonya faizi 19 Aralık'ta artırdı. Ama riskli varlıklar daha Ekim başında düşmeye başlamıştı.
Bitcoin 6 Ekim'de 126 bin doları gördü.
Aralık'taki o beklenen artış geldiğinde, Bitcoin zirvesinden yüzde 30 aşağıdaydı. Artış günü Japon borsası düşmedi, hafifçe yükseldi. Çünkü satacak olan zaten çoktan satmıştı.
Gelelim bugüne. Aynı senaryo, sahne sahne tekrar oynuyor.
Faiz artışı kesinleşmeye başlayınca ilk satılan, en kırılgan varlıklar oldu. Teknoloji hisseleri ve Bitcoin önden düştü.
Ama hikâye burada bitmiyor. Asıl merak edilen soru şu. Madem mesele Japonya ve riskli varlıklar, altın neden düştü? Altın güvenli liman değil miydi?
Cevap, bu varlıkları kimin tuttuğunda gizli.
Bu varlıkların büyük kısmı aynı fonların elinde. Hedge fonları. Bu fonlar tek tek varlıklara değil, koca bir portföye bakar.
Portföyün bir köşesinde büyük zarar başlayınca, bir kuralları devreye girer.
Toplam riski hızla azaltmaları gerekir. Bunu yapmanın yolu da, zarardaki varlığı değil, kârdaki varlığı satmaktır. Çünkü nakit oradadır.
Peki son yılların en çok kazandıran, en kolay paraya çevrilen varlığı neydi?
Altın ve gümüş.
İşte bu yüzden altın ve gümüş de satıldı. Kötü oldukları için değil. Tam tersine, en iyileri oldukları için. Zarar başka yerdeydi, ama faturayı en sağlam varlık ödedi.
Şimdi bütün parçaları aynı masaya koyun.
Hürmüz'de tırmanan enerji. Kârı sorgulanan yapay zeka yatırımları. Durmadan değer kaybeden yen. Tutmayan müdahaleler. Kesinleşen bir faiz artışı. Bir de bunların üstüne, fonların mecburi satışı.
Bunların hiçbiri yalnız başına bütün piyasayı yıkmaz. Ama hepsi aynı haftada gerçekleşti.
İşte böyle anlarda güvenli liman diye bir şey kalmaz. Kimse satmak istediğini satmaz. Satabildiğini satar.
Herkesin gözü dün Amerika'daydı. Ama asıl düğme, yıllardır Tokyo'daydı.
Bana göre piyasa şu an Japonya'nın faiz artışını fiyatlıyor.
Yıllar sonra dönüp bu düşüşe baktığımızda, ismini koyacağız. Japonya'nın faiz artırımı.
Bu benim şahsi analizim.
Gelişmeleri takip ediyorum, sizi bilgilendireceğim.
I just completed three Microsoft AI Agent modules:
• Memory, State, and Evaluation
• Multi-Agent Systems and Orchestration
• Governance, Guardrails, and Operations
One thing stood out.
We've spent years talking about prompts.
The real challenge is systems.
🧵
SpaceX could be just the beginning.
ARK's new analysis covers the initial public offering (IPO) wave we believe is building behind the headlines. The ARK Venture Fund holds positions in six companies with active IPO timelines. Each of them reached public market scale while still private.
The questions we are hearing from investors:
• Is this a one-time event or the start of a broader wave?
• Which companies are next?
• What does pre-IPO access actually mean for returns?
• How is the ARK Venture Fund positioned across the pipeline?
As of Q1 2026, OpenAI crossed $25 billion in annualized revenue. Anthropic just confidentially filed. Databricks is preparing for its own listing.
Access to the ARK Venture Fund starts at $500 via SoFi or Titan.
🚨 EVERYTHING THAT COULD GO WRONG FOR MARKETS WENT WRONG TODAY.
S&P 500 down -1.65%, wiping out $1.14 trillion.
Nasdaq down -2.60%, wiping out $1.11 trillion.
Gold down -3.38%, wiping out $1 trillion.
Silver down -6.9%, wiping out $280 billion.
Bitcoin down -6.31%, wiping out $80 billion.
In total $2.5 TRILLION wiped out in a single session. These were not isolated moves. Everything started breaking at the same time.
It started with the jobs report this morning.
The US economy added 172,000 jobs in May. Wall Street expected 88,000. That is almost double.
On any normal day, strong jobs is good news. But inflation is already at 3.8% and oil is sitting at $90. A labor market this strong tells the Fed it cannot cut interest rates and may actually need to raise them.
The probability of a rate hike this year went from 40% to 57% in a single day. That spooked every investor holding tech and growth stocks because higher rates mean those stocks are worth less today.
Then the AI trade started cracking.
Yesterday Broadcom reported record earnings: revenue up 48%, AI chip sales up 143% and the stock still crashed 12.6%. The reason was simple.
Broadcom did not raise its AI revenue targets for the year. Investors had expected it to. That single miss made people ask a question they had been avoiding for months: are we paying too much for AI stocks?
That question got louder today when a research firm called SemiAnalysis revealed that Nvidia's next-generation AI chips will need significantly less memory than everyone assumed, roughly half of what the market was pricing in.
Memory chips are what companies like SK Hynix and Samsung make. SK Hynix fell nearly 10% today. Samsung fell over 6%.
South Korea's entire stock market crashed 5.5% in a single session. Japan's semiconductor stocks did the same.
And then Anthropic added fuel to the fire by publishing a report warning that AI is getting close to the point where it can improve itself without human help and calling for a global pause in AI development.
Coming on the same day as the memory demand news and Broadcom's miss, it fed a single growing fear across the market: what if the AI boom is moving faster than the business models can keep up with?
Underneath all of this, there is a liquidity problem nobody is talking about.
SpaceX goes public next week at a $1.75 trillion valuation. Anthropic just filed to go public. OpenAI is next.
These three companies together are worth $4 to $5 trillion. Fund managers need cash to buy into these listings.
But cash levels are already at their lowest since early 2024. The only way to raise cash is to sell what they already own. That selling is happening right now.
The new Fed Chair Kevin Warsh will also hold his very first policy meeting in 11 days. He was appointed by Trump with the expectation of cutting rates.
He is now walking into a situation where inflation is high, oil is high, and the job market is running hot. Investors do not know what he will do.
When nobody knows what the most powerful central banker in the world will decide in less than two weeks, the safest move is to reduce risk today.
Everything that could go wrong, went wrong at the same time. A hot jobs report, a collapsing ceasefire, a crack in the AI trade, a trillion dollar liquidity drain, and a Fed meeting with no clear outcome.
BREAKING.: Biggest privacy token $ZEC crashed over -50% in the last 24 hours and wiped out $5 Billion from its market cap.
The flaw was hidden inside Zcash's Orchard privacy pool since May 2022 and remained undetected for nearly 4 years despite multiple security audits.
Security researcher Taylor Hornby reportedly used Claude Opus 4.8 AI model to build a working proof-of-concept that successfully generated counterfeit ZEC in local testing on May 29.
Although the bug has now been patched on June 2, The issue is that Zcash's privacy design makes it impossible to know if any fake ZEC was minted before the fix. Unlike Bitcoin, where anyone can verify the supply, Zcash's privacy design makes it impossible to audit whether fake coins were secretly minted before the fix.
The team denies any fake ZEC was minted, but traders are selling on the fear alone. Imagine someone secretly adding extra chips to a casino, but because of the way the system works, neither the casino nor the players could tell which chips were real and which were fake.
Shielded Labs is exploring a proposed Network Upgrade to allow anyone to verify the integrity of Zcash supply.
🚨 As always, the MIT AI Risk Initiative leaves NO STONE unturned!
Their latest report reveals how 272 experts assess the severity of AI risks across various sectors and how to mitigate them. [Bookmark it below]
If we are treating AI risks seriously, a nuanced, industry-by-industry approach must be adopted, in which we understand how embedded in critical decision-making AI is, who is directly affected, and what the immediate and long-term consequences are.
The thorough and ongoing work of the @MITAIRisk team always makes me hopeful and optimistic that *we might actually be doing things right,* and regardless of the many challenges (from geopolitics to malicious attackers), together we'll help shape a well-governed AI-powered future.
Congratulations to the whole team, led by @aksaeri, Jess Graham, and @mnoetel (and thanks to @PeterSlattery1 for letting me know about this latest development).
-
👉 Download the full report below.
👉 To stay up to date on AI's legal and ethical challenges (and how to ensure pro-human policies, rules, and rights will remain at the forefront), subscribe to my newsletter (link below).
The era of agentic AI is here, reshaping how enterprises operate and collaborate.
Join us to learn how CIOs can partner across the organization, anchor governance, and champion AI agents that deliver lasting results: https://t.co/B6NGxZe71b
The global stock market has officially crossed $150 trillion in value for the first time ever.
The U.S. now accounts for 52% of global market cap, its highest share in 35 years, driven largely by the Magnificent 7 and the ongoing AI boom.
From $1T in 1975 to $150T in 2026. The scale of wealth creation over the last five decades has been extraordinary.
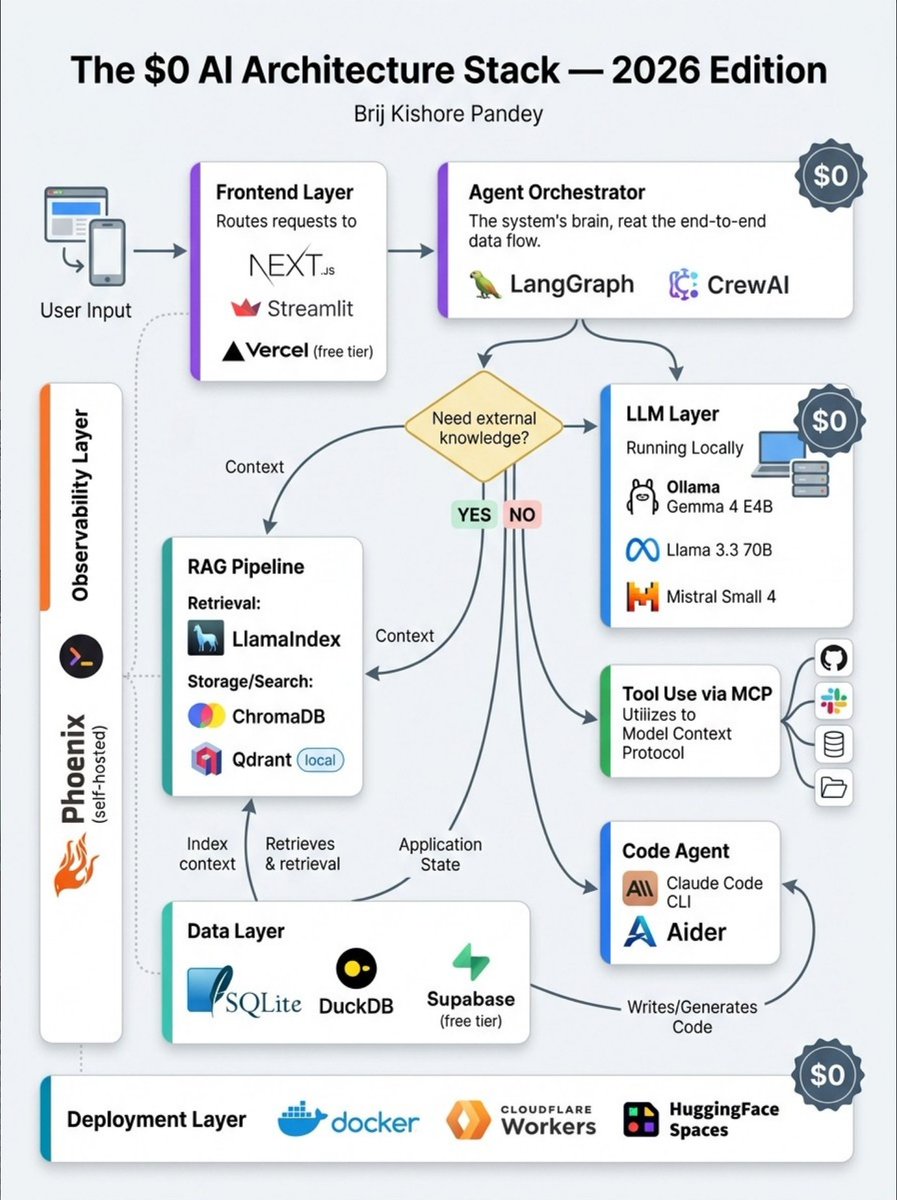
You don't need to spend a single dollar to build a production AI system in 2026.
Here's the full stack:
→ LLM: Ollama + Gemma 4 / Llama 3.3 / Mistral Small 4 (local, free)
→ Orchestration: LangGraph / CrewAI (open source)
→ RAG: LlamaIndex + ChromaDB / Qdrant (local)
→ Tool Layer: MCP — the open protocol connecting agents to everything
→ Code Agent: Claude Code CLI / Aider
→ Frontend: Next.js + Vercel free tier / Streamlit
→ Data: SQLite / DuckDB / Supabase free tier
→ Observability: Langfuse / Phoenix (self-hosted)
→ Deploy: Docker / Cloudflare Workers / HuggingFace Spaces
Total cost → $0.
The tools are free.
The architecture knowledge is what's valuable.
Save this for your next build 🔖
Credit: codewithbrij
#AIArchitecture #AgenticAI #LLM #Ollama #Gemma4 #LangGraph
As AI transforms how we work, access to skills is becoming a key driver of economic opportunity.
Our Sustainable & Inclusive Growth Impact Report explores how closing skill gaps can help people thrive while building resilient, future-ready workforces. https://t.co/ytSHztcHdx
Fundamentals of a 𝗩𝗲𝗰𝘁𝗼𝗿 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲.
With the rise of GenAI, Vector Databases skyrocketed in popularity. The truth - Vector Databases are also useful outside of a Large Language Model context.
When it comes to Machine Learning, we often deal with Vector Embeddings. Vector Databases were created to perform specifically well when working with them:
➡️ Storing.
➡️ Updating.
➡️ Retrieving.
When we talk about retrieval, we refer to retrieving set of vectors that are most similar to a query in a form of a vector that is embedded in the same Latent space. This retrieval procedure is called Approximate Nearest Neighbour (ANN) search.
A query here could be in a form of an object like an image for which we would like to find similar images. Or it could be a question for which we want to retrieve relevant context that could later be transformed into an answer via a LLM.
Let’s look into how one would interact with a Vector Database:
𝗪𝗿𝗶𝘁𝗶𝗻𝗴/𝗨𝗽𝗱𝗮𝘁𝗶𝗻𝗴 𝗗𝗮𝘁𝗮.
1. Choose a ML model to be used to generate Vector Embeddings.
2. Embed any type of information: text, images, audio, tabular. Choice of ML model used for embedding will depend on the type of data.
3. Get a Vector representation of your data by running it through the Embedding Model.
4. Store additional metadata together with the Vector Embedding. This data would later be used to pre-filter or post-filter ANN search results.
5. Vector DB indexes Vector Embedding and metadata separately. There are multiple methods that can be used for creating vector indexes, some of them: Random Projection, Product Quantization, Locality-sensitive Hashing.
6. Vector data is stored together with indexes for Vector Embeddings and metadata connected to the Embedded objects.
Learn all you need to know about vector databases in my End-to-End AI Engineering Bootcamp.
Just this week 25% off: https://t.co/2LY420tzJK
𝗥𝗲𝗮𝗱𝗶𝗻𝗴 𝗗𝗮𝘁𝗮.
7. A query to be executed against a Vector Database will usually consist of two parts:
➡️ Data that will be used for ANN search. e.g. an image for which you want to find similar ones.
➡️ Metadata query to exclude Vectors that hold specific qualities known beforehand. E.g. given that you are looking for similar images of apartments - exclude apartments in a specific location.
8. You execute Metadata Query against the metadata index. It could be done before or after the ANN search procedure.
9. You embed the data into the Latent space with the same model that was used for writing the data to the Vector DB.
10. ANN search procedure is applied and a set of Vector embeddings are retrieved. Popular similarity measures for ANN search include: Cosine Similarity, Euclidean Distance, Dot Product.
How are you using Vector DBs? Let me know in the comment section!
🌊 Every new wave of AI innovation brings fresh threats alongside powerful tools that can transform your defense strategy.
This webinar uncovers how security teams are leveraging AI responsibly, staying vigilant against adversaries, and charting a path toward secure, scalable adoption: https://t.co/ukkO5Ogkwi
RAG is no longer just "vector search + LLM."
In 2026, the real question isn't:
❌ Which vector database should we use?
It's:
✅ Which retrieval architecture does this use case need?
5 RAG architectures every AI builder should know 👇
1. Hybrid RAG
→ Vector search + keyword search
Best when semantics alone aren't enough.
2. GraphRAG
→ Uses entities and relationships
Best for reasoning across connected information.
3. Agentic RAG
→ Retrieval becomes a planning process
Agents decide when, where, and how to search.
4. Corrective RAG (CRAG)
→ Validates retrieved results before using them
Can rewrite queries or retry retrieval when confidence is low.
5. Multimodal RAG
→ Retrieves from text, images, charts, and tables
Essential for enterprise documents and visual data.
The biggest misconception:
RAG isn't a single architecture.
It's a design space.
Different problems require different retrieval strategies.
Support bots, legal research, finance assistants, healthcare systems, and enterprise search all need different approaches.
The future of RAG isn't just better embeddings.
It's better retrieval design.
Which RAG architecture do you think will dominate in 2026? 👇
#AI #RAG #LLM #AIAgents #MachineLearning
Unlock the power of autonomous workflows with Startup School: Agentic AI.
Join @GoogleCloud experts to discover how to build, deploy, and scale sophisticated #AIagents that drive real business impact. Ready to innovate? Register here ➡️ https://t.co/QzUDNTjYzt
“I will build a RAG system for my company in one week” - that is what I often hear nowadays from recently turned AI experts.
Unfortunately, building a 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗴𝗿𝗮𝗱𝗲 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗔𝘂𝗴𝗺𝗲𝗻𝘁𝗲𝗱 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 (𝗥𝗔𝗚) 𝗯𝗮𝘀𝗲𝗱 𝗔𝗜 𝘀𝘆𝘀𝘁𝗲𝗺 is a challenging task.
Here are some of the moving parts in the RAG based systems that you will need to take care of and continuously tune in order to achieve desired results:
𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹:
𝘍 ) Chunking - how do you chunk the data that you will use for external context.
- Small, Large chunks.
- Sliding or tumbling window for chunking.
- Retrieve parent or linked chunks when searching or just use originally retrieved data.
𝘊 ) Choosing the embedding model to embed and query and external context to/from the latent space. Considering Contextual embeddings.
𝘋 ) Vector Database.
- Which Database to choose.
- Where to host.
- What metadata to store together with embeddings.
- Indexing strategy.
𝘌 ) Vector Search
- Choice of similarity measure.
- Choosing the query path - metadata first vs. ANN first.
- Hybrid search.
𝘎 ) Heuristics - business rules applied to your retrieval procedure.
- Time importance.
- Reranking.
- Duplicate context (diversity ranking).
- Source retrieval.
- Conditional document preprocessing.
𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻:
𝘈 ) LLM - Choosing the right Large Language Model to power your application.
✅ It is becoming less of a headache the further we are into the LLM craze. The performance of available LLMs are converging, both open source and proprietary. The main choice nowadays is around using a proprietary model or self-hosting.
𝘉 ) Prompt Engineering - having context available for usage in your prompts does not free you from the hard work of engineering the prompts. You will still need to align the system to produce outputs that you desire and prevent jailbreak scenarios.
And let’s not forget the less popular part:
𝘏) Observing, Evaluating, Monitoring and Securing your application in production!
What other pieces of the system am I missing? Let me know in the comments 👇































![LuizaJarovsky's tweet photo. 🚨 As always, the MIT AI Risk Initiative leaves NO STONE unturned!
Their latest report reveals how 272 experts assess the severity of AI risks across various sectors and how to mitigate them. [Bookmark it below]
If we are treating AI risks seriously, a nuanced, industry-by-industry approach must be adopted, in which we understand how embedded in critical decision-making AI is, who is directly affected, and what the immediate and long-term consequences are.
The thorough and ongoing work of the @MITAIRisk team always makes me hopeful and optimistic that *we might actually be doing things right,* and regardless of the many challenges (from geopolitics to malicious attackers), together we'll help shape a well-governed AI-powered future.
Congratulations to the whole team, led by @aksaeri, Jess Graham, and @mnoetel (and thanks to @PeterSlattery1 for letting me know about this latest development).
-
👉 Download the full report below.
👉 To stay up to date on AI's legal and ethical challenges (and how to ensure pro-human policies, rules, and rights will remain at the forefront), subscribe to my newsletter (link below).](https://pbs.twimg.com/media/HJ95DdoXkAAydXZ.jpg)