Your entire life will change when you realize that anything above zero compounds. That showing up consistently matters more than showing up perfectly. That small things become big things. Never allow optimal to get in the way of beneficial.
Some tips to help agents understand your codebase:
1. The source code either needs to be the source of truth, or have something legible as a path to the source. For example, if marketing site content is actually stored in a CMS, you need to either delete the CMS and move that content into code, or make the CMS legible through and MCP, CLI, or skill: https://t.co/zhObygzELv
2. Agents need to be able to verify their work. This includes but is not limited to: using a typed language, having high-quality and fast tests, having a well-configured linter: https://t.co/AL3eY6TBXr
3. You need to have a concise and effective AGENTS.md file, which is included in every message to your agent. Models are quite good now, so some things you can omit as the models know them. You don’t need to say the tests live inside /tests for example. It’s worth asking the models to find things in your codebase and making sure they’re named what the models might expect, otherwise consider refactoring: https://t.co/2FlVQr84nO
4. Set up automations which give you suggestions for refactoring code, catching security issues which may have slipped through code review, and optionally continuous documentation of the codebase. You can effectively create a self-driving codebase which gets better while you sleep: https://t.co/UuYL3KNTZc
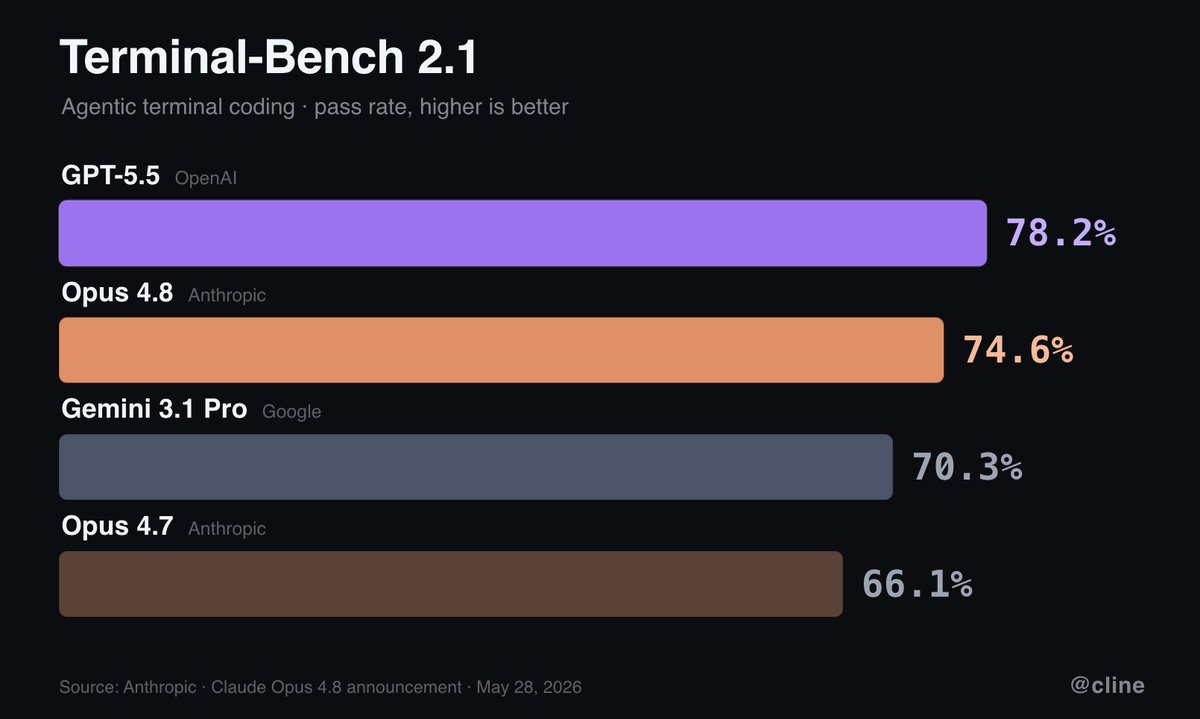
Anthropic's new Opus 4.8 scores 3.6% lower than GPT 5.5 on Terminal-Bench 2.1. Available to compare side-by-side in Cline now.
(They also announced a plan to release new models with higher intelligence than Opus after adding stronger cyber safeguards in the coming weeks.)
Struggling to pick what agent, model, and effort levels to use? Miss the "slot machine" feel of Claude Code when using other tools?
`npx slotslop "[prompt]"`
Claude Opus 4.8 is out today. It's our strongest coding model yet: up on SWE-bench Pro (from 64.3 to 69.2) and noticeably more honest about its own work. It tells you when it's unsure and catches its own bugs instead of declaring victory early. Same price as 4.7.