we're launching a small number (3) of templates for common cognitive architectures
these are configurable (choose LLM/vector store of your choice)
Starting with:
- ReAct agent
- RAG chatbot
- data enrichment (research) agent
What should we add next?
# scheduling workloads to run on humans
Some computational workloads in human organizations are best "run on a CPU": take one single, highly competent person and assign them a task to complete in a single-threaded fashion, without synchronization. Usually the best fit when starting something new. Comparable to "building the skeleton" of a thing.
Other workloads are best run on a GPU: take a larger number of (possibly more junior) people and assign tasks in parallel: massively multi-threaded, requiring synchronization overhead. Usually a good fit for later stages of a project, or parts that naturally afford parallelism, comparable to "fleshing out" a thing when the skeleton is there.
There's some middle ground here - sometimes you can imagine a multi-threaded CPU execution of a small team collaborating.
A good manager will understand the computational geometry of the project at hand and know when to delegate parts of it on the CPU or on the GPU. One notable place where the analogy breaks down a bit is that the worst thing that can happen when you misallocate computer resources is that your program will run slower. But in human organizations it can be much worse - not just slower, but the result can be of lower quality overall, more brittle, more disorganized, less consistent, uglier.
The most common stumbling point here is trying to parallelize something that was supposed to run on the CPU. In the common tongue, this comes from the misunderstanding that something can go faster if you put more people on it, usually leading to outcomes where something is "designed by a committee" - not only is the thing actually slower, but the philosophy is inconsistent, the entropy is high, and the long-term outcomes much worse.
The opposite problem is more rare and usually looks like someone doing something repetitive, uninteresting or tedious, where they could really benefit from more help.
I think this is one accidental advantage of startups - they lack resources of large companies and run compute on powerful CPUs, winning in cases where that is the right thing to do. Larger companies, especially in cases where something is deemed of high strategic importance, will almost always reach for too much parallelism.
TLDR: Think about your project, its computational geometry, its inherent parallelism, and which parts are a best fit for a CPU or a GPU.
@squeebo_nft@mattshumer_ If you do work on this ping me, have been working on LLM to build knowledge graphs... OpenAI functions are impressive at pulling structured data from documents Here is graph example of triples(Sub, Pred, Obj) : https://t.co/QkqdGvyVWw
@langchain@fpingham Nice presentations today!
Regarding the discussion on quick way to extract proper nouns in prompt @francisco Maybe check out https://t.co/K7plrpM2ur
Parse time for this prompt 7ms
@hwchase17 This should help my RAG on old Spanish text (Don Quixote,…). Will use summary function (or SeamlessM4T) to create English translation embeddings to index the Spanish chunks. This pattern opens a ton of fun options! Nice work! @hwchase17 & @langchain team
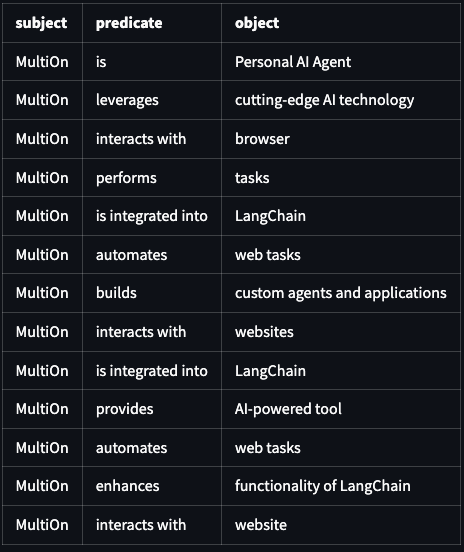
An underrated aspect of LLMs is using them for structured data extraction
Extracting knowledge triplets is a great use case!
I gave it our most recent blog post about @MultiON_AI (https://t.co/GjRyICGAkE) and it came up with the below - how did it do @DivGarg9 ??
These are 9 observations over the course of 10 months at @redbuttegarden. I love exploring seasonal change, phenology, with children, PSTs, and Ts. What do you notice and wonder about the images? #NGSS#SciEd#UTSEEd
The @SpaceX@Inspiration4x launch, endlessly flowing from the pad all the way to orbit.
Composite of multiple tracking telescopes using new techniques to bring out the faintest colors and finest details--in 10K resolution.
#EndlessInspiration