How can AI predict event sequences over time?
A new survey by researchers from Renmin University, Guangdong University of Technology, and Southeast University reviews Temporal Point Processes using Bayesian, neural, and LLM approaches.
They find that neural and LLM models outperform traditional statistical methods in flexibility and accuracy across finance, health, and social media.
Advances in Temporal Point Processes: Bayesian, Neural, and LLM Approaches
Paper: https://t.co/uOQ5m8sfrk
Our report: https://t.co/Qa7EKrOom9
📬 #PapersAccepted by Jiqizhixin
$CBRS
Reports say OpenAI is running its 5.6 Sol Frontier model on Cerebras hardware, hitting throughput speeds near 750 tokens per second. That level of output is absolutely staggering.
BioMatrix is the first biological foundation model to natively read and generate sequences, structures, and language
A single decoder-only architecture maps molecules and proteins into one shared token space. Trained on 304B tokens, it achieves SOTA on 77 of 80 tasks.
A crazy blog.
Chinese developers are buying Claude access through gray-market API transfer stations that can sell tokens at 5% to 10% of official prices while hiding the real user from Anthropic.
A transfer station is a middle server that takes a user’s prompt, sends it to Claude through overseas accounts, returns the answer, and collects payment through WeChat or Alipay.
The transfer station collects many Claude accounts through free credits, discounted accounts, shared subscriptions, overseas payment workarounds, fake verification, or sometimes stolen-card accounts.
It connects all those accounts behind one proxy, so Chinese users do not talk to Anthropic directly and only pay the proxy in RMB.
The cheap price comes from account farming, free-credit abuse, resale of unused quota, subscription splitting, possible stolen cards, and a darker trade where user prompts and outputs become training data.
So the price hugely cheap not because Anthropic is giving a discount; it is cheap because the transfer station lowers its own cost and creates extra hidden revenue.
The user thinks they are buying cheap inference, but the proxy may swap Opus for weaker models, inflate token use, or store private code, tool calls, reasoning traces, and business data.
The proxy may store user prompts, code, outputs, and tool traces, then sell or reuse that data for model training.
This breaks a core assumption behind KYC, account bans, and abuse monitoring: the AI company sees the proxy, not the real person, so banning one account leaves the upstream supply chain alive.
FT: Apple is asking Washington for permission to buy DRAM from CXMT, a blacklisted Chinese supplier, because AI server demand has made ordinary device memory painfully expensive.
DRAM is the short-term working memory inside iPhones, Macs, and iPads, while HBM is a stacked, faster version used in AI accelerators, so the AI buildout is pulling factory capacity toward servers and away from consumer gadgets.
Apple’s problem is supplier pressure, because it mainly depends on Micron, Samsung, and SK Hynix, while CXMT could add cheaper supply from China’s state-backed memory push.
But CXMT sits on the Pentagon’s Chinese Military Company list, which does not block Apple purchases by itself but signals national-security concern and could become far more serious if Commerce adds CXMT to the Entity List.
Apple’s $263B market-value loss was triggered by the memory-cost pressure that forced MacBook and iPad price hikes, showing how AI infrastructure demand is now raising the cost base of everyday consumer devices.
"Long-term innovation depends not only on optimization for current objectives, but on the continued viability of ideas whose value is not yet legible"
Thought-provoking ICML paper on limitations & risks of over-relying on AI benchmarks 1/
FlashAttention-4 just changed the game!
The problem: Blackwell scaled the matrix-multiply units way up, but the units that move shared memory and compute exponentials barely moved. So the old attention kernel now spends its time waiting on the parts that didn't get faster.
FlashAttention-4 rebalances around that with 3 tricks:
1. Overlap the matmul and the softmax so neither waits.
2. Compute the exponential in software, not on the slow dedicated unit.
3. Skip the rescaling you don't need.
I made a short visual breakdown - one diagram per trick. Swipe through. 👇
---
paper - https://t.co/uBn414Wd7H
Today's live: build an LLM from one prompt, then setup an autonomous research loop. Join 👉 https://t.co/6nocqbVceu
Seem like the release of the Grok 1.5T / Cursor Composer 3 model is imminent, as the version number has been removed from the menus. This always happens shortly before a release from @xai.
🔥
My current AI coding workflow:
@claudeai → @OpenAICodexCli → @grok
- Claude: Planning & architecture
- Codex CLI: Actual building (edits files, runs commands, ships)
- Grok: Honest review + catches what the others miss
Each tool has different strengths. Using them in sequence > using any single one.
What's your current stack?
NEW paper from NVIDIA.
(bookmark it)
Speed-of-light performance analysis tells you the theoretical floor of a workload, but teams still derive it by hand and freeze it. SOLAR automates the whole thing straight from PyTorch or JAX source.
An LLM frontend translates arbitrary code into an executable Affine Loop IR, validated by output comparison, then a deterministic pass lifts it into an einsum graph, and an analytical backend computes the bounds.
The model is confined to translation, so the actual bound math stays deterministic.
Across KernelBench, Flax models, and robotics workloads, they report zero observed SOL violations.
Paper: https://t.co/KXgsPxcSnY
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
Q × Kᵀ tells the model how relevant every word is to every other word.
Softmax turns that into probabilities. V delivers the actual content.
One formula. Three steps. The entire foundation of modern AI.
Today I pushed a big step forward on the startup research agent I’ve been building.
The idea is simple:
you enter a niche, and the agent helps turn it into a real startup direction.
What it does right now:
scans competitors
critiques weak ideas
ranks the strongest opportunity
generates landing page copy
suggests a build plan
recommends a tech stack
What I’m liking most is that it feels less like a chatbot and more like a workflow.
It doesn’t just answer.
It investigates, compares, scores, and narrows.
That shift is the real lesson for me:
an agent becomes useful when it can follow a process, not just produce output.
We’re still in MVP mode, but the shape is becoming clear.
The next improvements I want are:
stronger critique logic
cleaner memory structure
better idea scoring
more consistent output across niches
a more polished public launch experience
Small build.
Big learning.
And a lot more to ship.
Outcome reward models: cheap, but vulnerable to spurious shortcuts 😣
Process reward models (PRMs): robust, but too expensive to build from scratch 😫
What if you could get a ready-to-use PRM right after any RL post-training?
Introducing 'Progress Advantage' 🧵
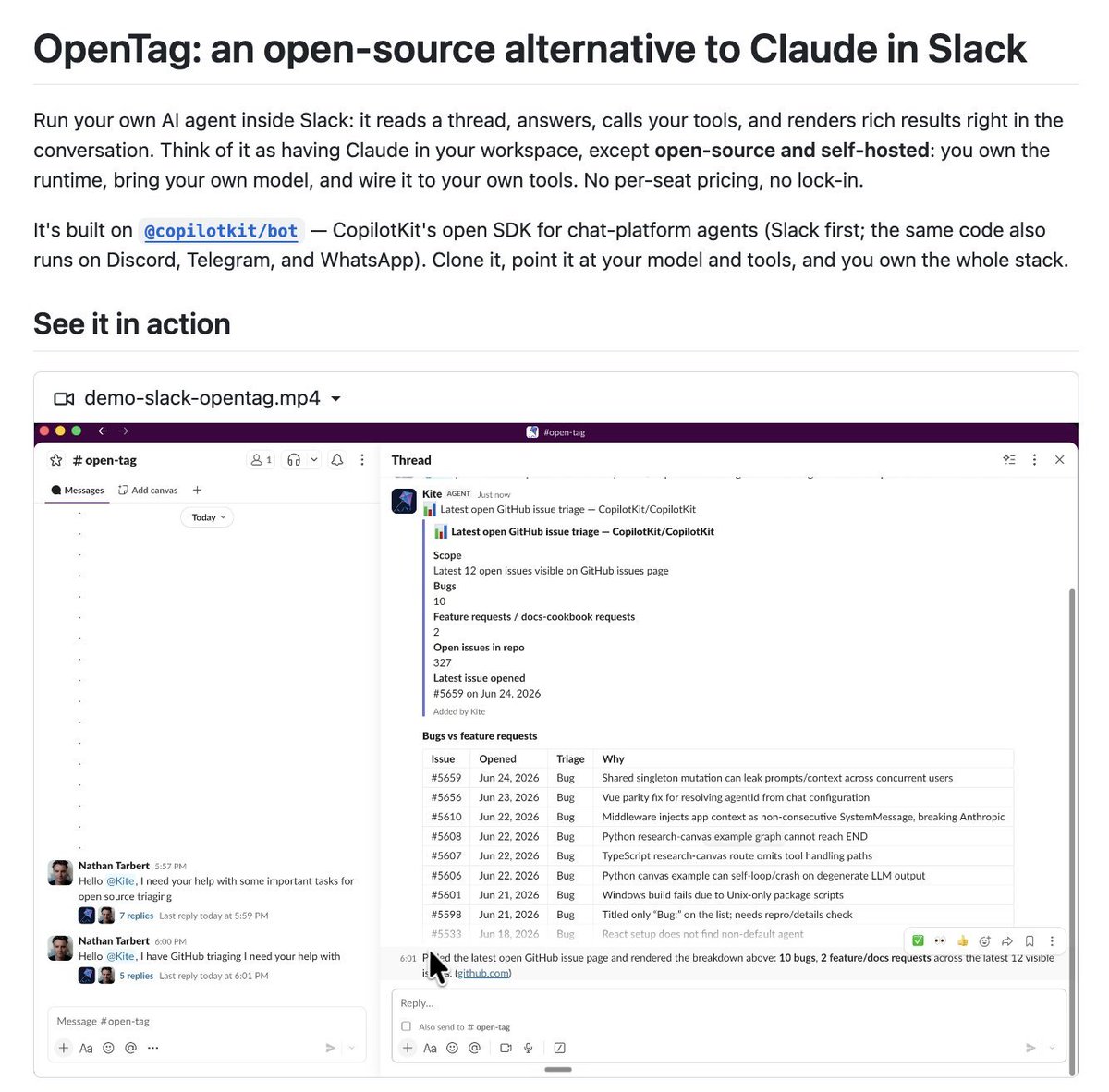
Claude Tag but 100% Opensource.
Bring your own model, own the runtime, and wire it to your own tools.
Supports
- Generative UI
- Streaming replies
- Human in the Loop approvals
DeepSeek just released DSpark for V4 Flash & Pro, a new speculative decoding method boosting throughput by 51% to 400%!
DS also showed DSpark works well for other models like Gemma & Qwen
Github: https://t.co/EGVYpc1kcK
Paper: https://t.co/TaBMRVlaW9
HF: https://t.co/289jVU2pxh
Today on the blog we introduce a method to retrofit Multi-Token Prediction onto frozen production models, accelerating on-device inference without the inefficiencies of separate drafters.
Learn more →https://t.co/9Tq8hosoxS





![fly51fly's tweet photo. [CV] Unlimited OCR Works
Y Yin, H Liu, YY, Q Xie… [Baidu Inc.] (2026)
https://t.co/aQaQGvdSbv https://t.co/qD3pLlIqzz](https://pbs.twimg.com/media/HL2WVocacAEAshE.jpg)
![fly51fly's tweet photo. [CV] Unlimited OCR Works
Y Yin, H Liu, YY, Q Xie… [Baidu Inc.] (2026)
https://t.co/aQaQGvdSbv https://t.co/qD3pLlIqzz](https://pbs.twimg.com/media/HL2WVZwaAAAW0vZ.jpg)
![fly51fly's tweet photo. [CV] Unlimited OCR Works
Y Yin, H Liu, YY, Q Xie… [Baidu Inc.] (2026)
https://t.co/aQaQGvdSbv https://t.co/qD3pLlIqzz](https://pbs.twimg.com/media/HL2WVBQbAAAj1Q4.png)













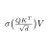









![fly51fly's tweet photo. [CV] Unlimited OCR Works
Y Yin, H Liu, YY, Q Xie… [Baidu Inc.] (2026)
https://t.co/aQaQGvdSbv https://t.co/qD3pLlIqzz](https://pbs.twimg.com/media/HL2WV18aQAA4Qrr.jpg)