Today is a massive milestone for @Cisco and the future of quantum networks, as we announce our Universal Quantum Switch. This first-of-its-kind working research prototype is designed for interoperability, speed, and real-world environments, made possible by a Cisco-patented conversion engine. @Vijoy and team - you should be incredibly proud of what it took to get here. Excited for what’s ahead as we build the network layer for the quantum era!
https://t.co/dFcCgZAKG5
2300+ builders at @UMich in Ann Arbor this week. The biggest @ClawCon yet.
Maize looks good on a lobster.
Some special things coming. Stay tuned.🦞
https://t.co/KmfNPuQe0C
Jesse Genet on Agentic Parenting
Jesse Genet joins a16z's Sarah Wang and Katherine Boyle to discuss her journey from founder to parent, how she's using agents in her household, and how AI could transform parenting for the better.
00:00 YC founder turned homeschool mom
03:00 Discovering Claude Code and agentic building
06:00 Building while homeschooling 4 kids under 5
11:00 How AI generates personalized lesson plans and logs progress
18:00 Jesse's 11-agents
27:05 Agent tech stack deep dive
33:56 How agents improve daily life
40:04 Letting kids interact with AI: values, risks, and the future of parenting
@jessegenet@KTmBoyle@sarahdingwang
At GTC a few weeks back, Robotics and Quantum looked like science projects with minimal focus. Would not be surprised if they become lion share of the event within 2-3y.
Excellent breakdown.
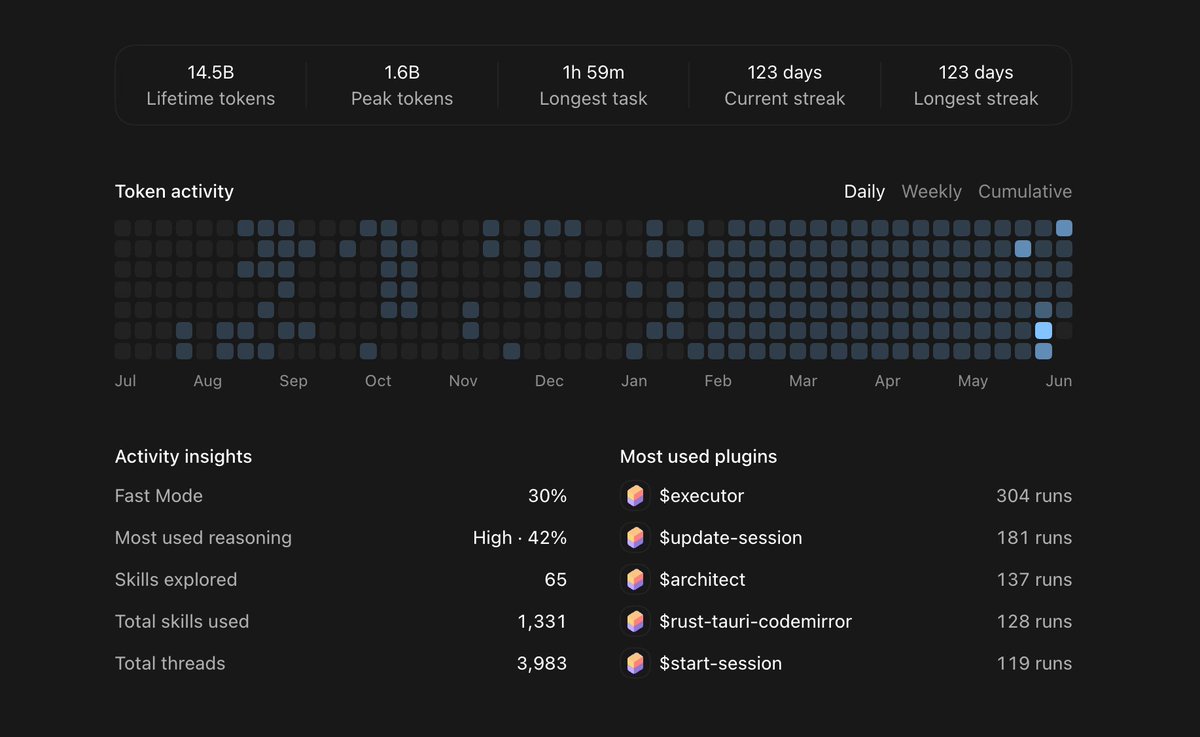
80% Agent Skills development
- technical & business workflow depth required to do this effectively
20% everything else (Harness, Context & Memory setup)
The more enterprises I talk to about AI agent transformation, the more it’s clear that there is going to be a new type of role in most enterprises going forward. The job is to be the agent deployer and manager in teams. Here’s the rough JD:
This person will need to figure out what are the highest leverage set of workflows on a team are (either existing or new ones) where agents can actually drive significantly more value for the team and company.
In general, it’s going to be in areas where if you threw compute (in the form of agents) at a task you could either execute it 100X faster or do it 100X more times than before. Examples would be processing orders of magnitude more leads to hand them off to reps with extra customer signal, automating a contracting review and intake process, streamlining a client onboarding process to reduce as many straps as possible, setting up knowledge bases than the whole company taps into, and so on.
This person’s job is to figure out what the future state workflow needs to look like to drive this new form of automation, and how to connect up the various existing or new systems in such a way that this can be fulfilled. The gnarly part of the work is mapping structured and unstructured data flows, figuring out the ideal workflow, getting the agent the context it needs to do the work properly, figuring out where the human interfaces with the agent and at what steps, manages evals and reviews after any major model or data change, and runs and manages the agents on an ongoing basis tracking KPIs, and so on.
The person must be good at mapping the process and understanding where the value could be unlocked and be relatively technical, and has full autonomy to connect up business systems and drive automation. This means they’re comfortable with skills, MCP, CLIs, and so on, and the company believes it’s safe for them to do so. But also great operationally and at business.
It may be an existing person repositioned, or a totally net new person in the company. There will likely need to be one or more of these people on every team, so it’s not a centralized role per se. It may rile up into IT or an AI team, or live in the function and just have checkpoints with a central function.
This would also be a fantastic job for next gen hires who are leaning into AI, and are technical, to be able to go into. And for anyone concerned about engineers in the future, this will be an obvious area for these skills as well.
Pictures speak. Patterns show. Stories reveal.
“Story” aka narrative prompting with Claude models is single biggest prompting change I’ve made in past year. Game changer!
I think "prompting" will keep being an incredibly high-leverage skill, like writing or public speaking.
It is the skill of talking to agents, mediated by the harness.
My main goal is to grow the bandwidth between humans and agents, to help us understand each other better.
Agreed. I’ve stopped trying to pick just one.. Instead they compliment each other very well.
Claude for creative exploration when planning writing new feature spec.
Codex to validate plan and execute.
I've been flipping between Codex and Claude a lot these last two weeks, and if it's taught me anything it's this: these two tools are almost nothing alike. I had naively assumed they would be vaguely similar, but nope – once you push them hard they diverge fast.
We’ve made major upgrades to X API:
• Pay-Per-Use now GA worldwide
• XMCP Server + xurl for agents
• Official Python & TypeScript XDKs
• API Playground - free realistic simulations
New releases coming will be a game changer.
Start building → https://t.co/hiyP33PMVa 🚢
More fun with Gemma 4 31B Q4 on 5090.
LLM Benchy concurrency results with 4 parallel slots drops cache down to 16K each for total vram usage of 28gb:
• Sweet spot at C=4: Hits 185.6 t/s aggregate (⭐ peak) → ~2.7–2.8× faster than single request (~67 t/s)
• Short prompts (pp=512): 186 t/s peak
• Longer prompts (pp=2048): 168–176 t/s peak
Gemma 4 changed the game. Gemma-4–It 31B Q4 w/ 128K context & full agent tool calling on llama.cpp. Only 30.2gb vram usage while delivering 68.8 tok/s via 5090. Local is the way 💪🔥
@TheMattBeebe@petergyang@ryancarson Interesting idea. Supports shared folders like Box, GDrive, iCloud, etc. No git collab sharing. But open & free for anyone to build it :)
Obsidian being closed source is major blocker for me. For a decade+ wanted a local md notes app that was truly local and could easily share output (export to pdf, doc, boxnote) with teammates not using markdown.
Started passion project back in July to build:
Phizzog Vault - https://t.co/XU4j85NGci
Local-first md based notes app that brings together everything you've saved, highlighted, or written — private, fast, AI-ready.
Open-source developed and free to use.
- All the core md read / write & syntax.
- Only notes app with native “Progressive Summarization” to turn highlights into key AI context!
- AI chat & CLI Agent native support
- Export to PDF, HTML, Doc
- Boxnotes integration
- CSV with AI context support
- UUIDv7 for graph rag integration
- Native Rust based MCP integrations
Which local models can actually handle tool calling?
I built a framework to find out.
15 scenarios. 12 tools. Mocked responses. Temperature 0. No cherry-picking.
Tested every Qwen3.5 size from 0.8B to 397B, and since some of you asked after the distillation tests: yes, I included Jackrong's Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled too.
Only two models went all green: the 27B dense and the distilled 27B.
The 397B? Failed two tests. The 122B? Failed one. The 35B? Failed two.
The timed-out results — mostly on the smaller models, are cases where the model got stuck in a loop, repeating the same tool call until it hit the 30-second limit.
The test that exposed the most models: "Search for Iceland's population, then calculate 2% of it." Simple, but 35B, 122B, and 397B all used a rounded number from memory instead of the actual search result. They didn't trust their own tool output.
Small models hallucinate data.
Big models ignore data.
The 27B just threaded it through.
Appears to be a major @claudeai MAX plan usage bug @AnthropicAI. I've cleared all sessions and continue to watch usage go up.. Something is way off as I've barely used Claude today yet continues to exceed 5hr window limits.
‘Frontend taste’ is great way to describe the diff in Codex UX compared to Claude.
Codex = IT engineer who finds 100 ways to say “sorry not supported”
Vs Claude = IT engineer who says “prob not supported but I can find a way to make it work..”
Codex needs a creative toggle
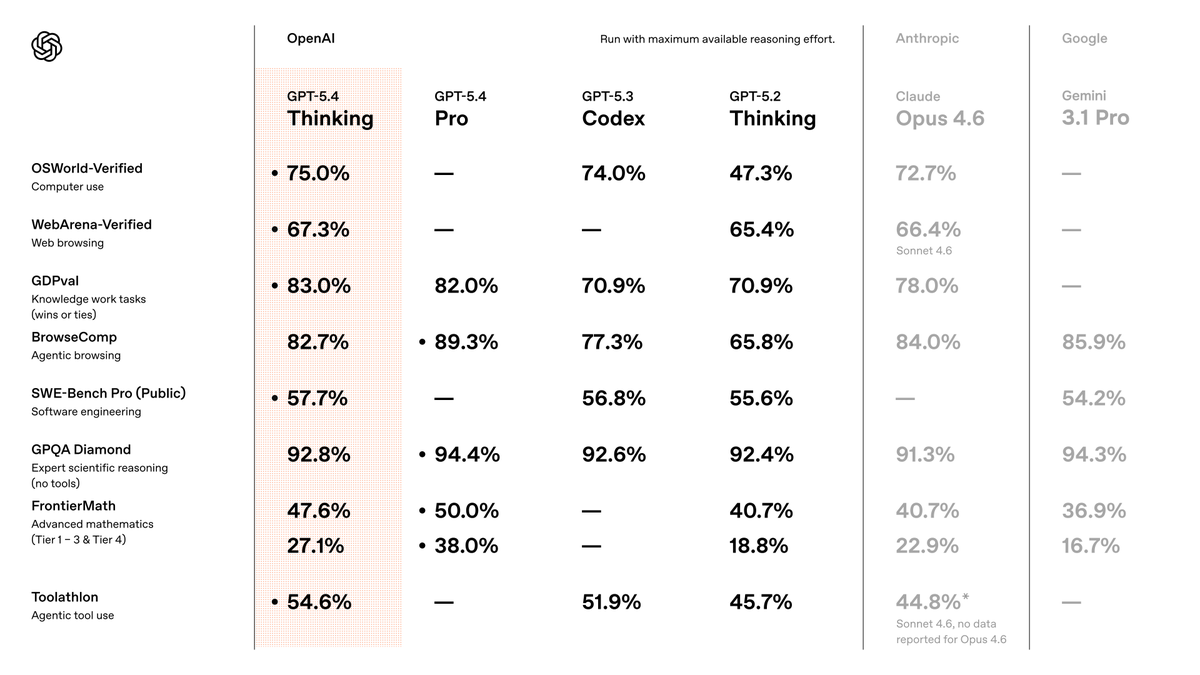
I've been testing GPT-5.4 for the last week.
In short, it is the best model in the world, by far.
It's so good that it's the first model that makes the “which model should I use?” conversation feel almost over.
The biggest surprise: I barely use Pro anymore!
If you know me, you know I'm a Pro addict. I reach for Pro models constantly, and use them for almost everything, as they just... nail almost anything I give to them.
For the first time, 5.4's standard version, with heavy thinking, just broke that habit.
Even in standard mode, GPT-5.4 is better than previous models in Pro mode... crazy!
Coding capabilities are ridiculous... it's essentially flawless. Inside Codex, it's insanely reliable. Coding is essentially solved. There's not much more to say on this, it's just THAT good.
The Pro version is near-perfect. Other testers I spoke with saw it solving problems that were unsolvable by any other model. At this point, Pro is overkill for almost every normal use-case, but when you really need the power to do something extremely difficult, it's incredible.
Consistent with everything I've said above, even the standard thinking version uses fewer reasoning tokens than previous models to get the same level of results. In practice, this means you get great results much faster than before. This was one of my biggest gripes with previous OpenAI models. They just took too long to complete simple tasks. Assuming the speed we had during testing holds up as more users join, this is going to be a big win for OpenAI.
It still has weaknesses, though:
- Frontend taste is FAR behind Opus 4.6 and Gemini 3.1 Pro. , why is this so hard to fix? @OpenAI once you fix this, there's literally no reason for me to use any other model. Please please please do it!
- It can still miss obvious real-world context. For example, I had it plan an itinerary for a trip. At first glance, it looked perfect, but it failed to take into account that it chose locations that would be mobbed by spring breakers, so I had to re-run the prompt from scratch with more context.
- When testing it inside OpenClaw, it kept stopping short before finishing tasks. I'm assuming this will be fixed quickly, but it's still worth noting.
But zooming out:
This thing is so far ahead overall that the nitpicks are starting to feel beside the point.
GPT-5.4 is a serious fucking model.
The best model in the world.
By far.
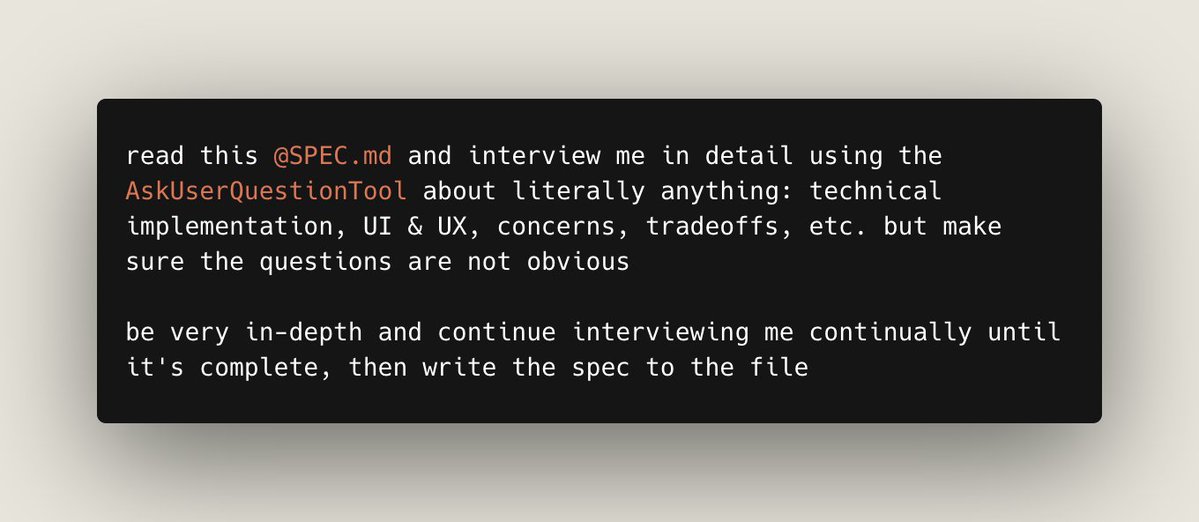
my favorite way to use Claude Code to build large features is spec based
start with a minimal spec or prompt and ask Claude to interview you using the AskUserQuestionTool
then make a new session to execute the spec