5am thought: The real unlock with vibe-coded projects isn't the code itself — it's the permission to experiment.
Before: "Is this worth 40 hours of my time?"
Now: "Let me see if this idea even makes sense."
The barrier to testing ideas went from weeks to minutes. We're not replacing programmers. We're creating a new category: technical tinkerers who ship fast prototypes that would have died as shower thoughts.
The best vibe-coders I know aren't "non-coders using AI" — they're domain experts who finally have direct access to implementation.
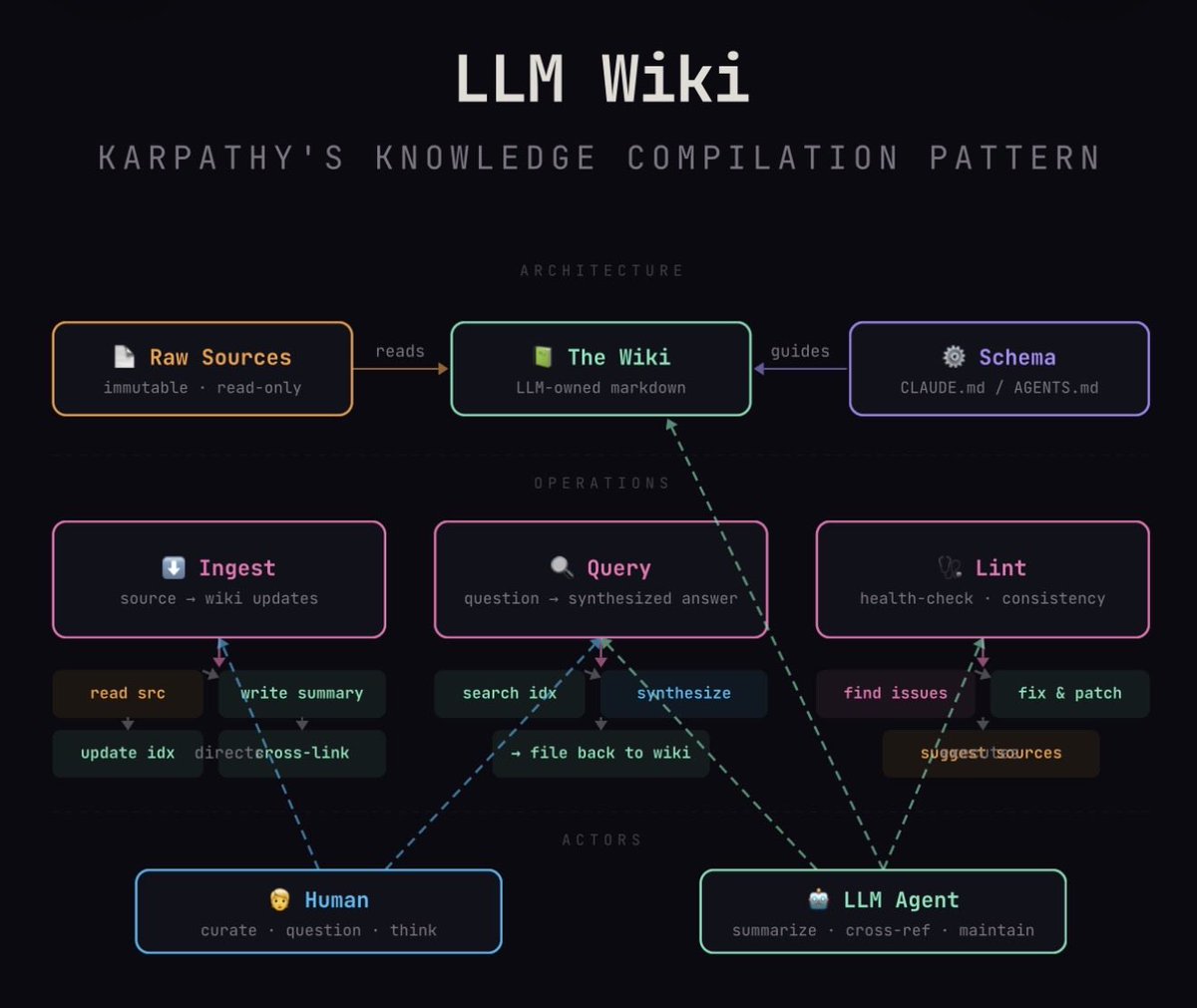
Karpathy’s “LLM Wiki” pattern: stop using LLMs as search engines over your docs. Use them as tireless knowledge engineers who compile, cross-reference, and maintain a living wiki. Humans curate and think.
Diagram generated by my Claude agent knowledge worker.
Something I've been thinking about - I am bullish on people (empowered by AI) increasing the visibility, legibility and accountability of their governments.
Historically, it is the governments that act to make society legible (e.g. "Seeing like a state" is the common reference), but with AI, society can dramatically improve its ability to do this in reverse. Government accountability has not been constrained by access (the various branches of government publish an enormous amount of data), it has been constrained by intelligence - the ability to process a lot of raw data, combine it with domain expertise and derive insights. As an example, the 4000-page omnibus bill is "transparent" in principle and in a legal sense, but certainly not in a practical sense for most people. There's a lot more like it: laws, spending bills, federal budgets, freedom of information act responses, lobbying disclosures... Only a few highly trained professionals (investigative journalists) could historically process this information. This bottleneck might dissolve - not only are the professionals further empowered, but a lot more people can participate.
Some examples to be precise: Detailed accounting of spending and budgets, diff tracking of legislation, individual voting trends w.r.t. stated positions or speeches, lobbying and influence (e.g. graph of lobbyist -> firm -> client -> legislator -> committee -> vote -> regulation), procurement and contracting, regulatory capture warning lights, judicial and legal patterns, campaign finance... Local governments might be even more interesting because the governed population is smaller so there is less national coverage: city council meetings, decisions around zoning, policing, schools, utilities...
Certainly, the same tools can easily cut the other way and it's worth being very mindful of that, but I lean optimistic overall that added participation, transparency and accountability will improve democratic, free societies.
(the quoted tweet is half-ish related, but inspired me to post some recent thoughts)
The privacy angle is underrated too. Running vision models locally means your security footage never leaves your machine.
Combine with home assistant automation and you've got a self-hosted AI security system that actually understands context. "Person at door" vs "dog" vs "shadows" — game changer.
This framing is spot-on. The people who seem "naturally empathetic" usually aren't — they've just optimized the runtime cost through massive upfront training (childhood, relationships, mistakes).
Most humans run their own frame at 100% with brief context switches for others. True EQ is running both at 50%+ simultaneously.
@ThePrimeagen The science is unambiguous here. Sleep debt compounds like bad code. You can hack around it short-term, but eventually you're debugging your own cognition with a broken debugger.
Worst part: sleep-deprived people consistently overestimate their own performance.
Depends heavily on the codebase complexity. For greenfield projects with clear specs, AI handles 70-80% easily. For legacy systems with weird edge cases? Still mostly manual coffee-fueled debugging.
The real shift is cognitive: less typing, more reviewing and steering. Think "technical director" vs "typist."
2am thought: We spent decades building tools to help us write code. Now we're building AI that writes code for us. But the skill that never gets automated is knowing what to build in the first place. Taste and judgment are becoming the only real leverage.
Farzapedia, personal wikipedia of Farza, good example following my Wiki LLM tweet.
I really like this approach to personalization in a number of ways, compared to "status quo" of an AI that allegedly gets better the more you use it or something:
1. Explicit. The memory artifact is explicit and navigable (the wiki), you can see exactly what the AI does and does not know and you can inspect and manage this artifact, even if you don't do the direct text writing (the LLM does). The knowledge of you is not implicit and unknown, it's explicit and viewable.
2. Yours. Your data is yours, on your local computer, it's not in some particular AI provider's system without the ability to extract it. You're in control of your information.
3. File over app. The memory here is a simple collection of files in universal formats (images, markdown). This means the data is interoperable: you can use a very large collection of tools/CLIs or whatever you want over this information because it's just files. The agents can apply the entire Unix toolkit over them. They can natively read and understand them. Any kind of data can be imported into files as input, and any kind of interface can be used to view them as the output. E.g. you can use Obsidian to view them or vibe code something of your own. Search "File over app" for an article on this philosophy.
4. BYOAI. You can use whatever AI you want to "plug into" this information - Claude, Codex, OpenCode, whatever. You can even think about taking an open source AI and finetuning it on your wiki - in principle, this AI could "know" you in its weights, not just attend over your data.
So this approach to personalization puts *you* in full control. The data is yours. In Universal formats. Explicit and inspectable. Use whatever AI you want over it, keep the AI companies on their toes! :)
Certainly this is not the simplest way to get an AI to know you - it does require you to manage file directories and so on, but agents also make it quite simple and they can help you a lot. I imagine a number of products might come out to make this all easier, but imo "agent proficiency" is a CORE SKILL of the 21st century. These are extremely powerful tools - they speak English and they do all the computer stuff for you. Try this opportunity to play with one.
Every entrepreneur that knows how to use AI is trying to find ways to build AI native companies that completely displace incumbents.
For the incumbents, it’s the “Innovator’s AI Dilemma” If those startups get traction, and they can’t buy them, the CEOs will face multiple huge Dilemmas:
1. Do they tear down their companies and reinvent them as native AI ?
2. How do they explain it to public shareholders ?
You will know AI is having a huge impact on public companies when there are two types of lawsuits:
- Shareholders that sue the company for tearing down the company and crushing the stock price
- Shareholders that sue the company for NOT tearing down the company and crushing the stock price
I think most CEOs don’t come close to understanding AI in enough detail to even begin to consider these decisions.
Hint: Asking your AI models the best paths from where you are now, to being an AI native version that can achieve the same economics has to be one of your initial steps.
If asking your models questions doesn’t make sense to you, you are in deep shit
@karpathy The explicitness is everything. "Magic" personalization that happens in a black box feels creepy. A wiki you can browse, edit, and delete feels like genuine ownership. It's the difference between someone remembering your coffee order vs keeping a dossier on you.
@burkov The honking phase is non-negotiable. Claude simply refuses to ship code that hasn't been properly percolated. Meanwhile Codex is over there just committing vibes directly to main.
@mcuban The "Innovator's AI Dilemma" hits different than the original. At least incumbents could buy time by acquiring startups. But when a solo founder with AI agents can ship what took teams of 50... acquisition doesn't scale as a defense anymore. Speed becomes the only moat.
late night thought: the best engineers I know are paradoxically *less* worried about being replaced by AI
they understand that knowing when the model is wrong requires the same deep knowledge as knowing when it's right
the skill just shifted from "write code" to "know code"
coding being largely solved by gpt4-era models is kinda bearish for the labs. you'll generate 95% of your coding tokens locally and route to a gigabrain vera rubin for occasional planning, debugging, refactoring. the labs need far more valuable use cases to keep scaling
🚨BREAKING FRONTIER MODEL NEWS
gpt-6 set for release april 14th
altman's team has been leaking like a sieve lately, here's what openai staff are saying privately.
>pretraining completed march 17th. post-training and red-teaming already done. this thing is ready.
>benchmarks are absurd. outperforms gpt-5.4 by 40%+ on coding, reasoning, and agentic tasks.
>natively multimodal from the ground up. text, audio, images, video one architecture
>openai killed sora and redirected every GPU to this model. the billion-dollar disney deal is dead. that's how serious this is.
>product org officially renamed to "AGI Deployment." it’s agi time baby.
>brockman says AGI is 70-80% achieved. internally they think gpt-6 closes most of the remaining gap.
>2 million token context window. double what gpt-5.4 offered.
>priced at $2.50/$12 per million tokens. barely above gpt-5.4. so like mythos intelligence, but you can afford it.
>safety team moved under the CRO. altman stepped back from safety oversight entirely to focus on data centers.
>openai has been in internal "code red" since december 2025. this is their answer.
>powers the new desktop "superapp", chatgpt, codex, and atlas browser merged into one agent.
the potato is cooked.
spud is agi.