BREAKING NEWS: NVIDIA HAS JUST OPEN SOURCED THEIR RUBIN NVSWITCH TRAY BoM & DIAGRAM & IT INCLUDES AMD EYPC 3151 EMBEDDED CPU. Since there is 9 NVSwitch Trays Per VR200 Rack, that is 9 small AMD embedded CPUs per NVIDIA rack.
NVIDIA has open sourced this in their "NVIDIA/nvbmc-docs" public github repo which has an CC 4.0 open source license!
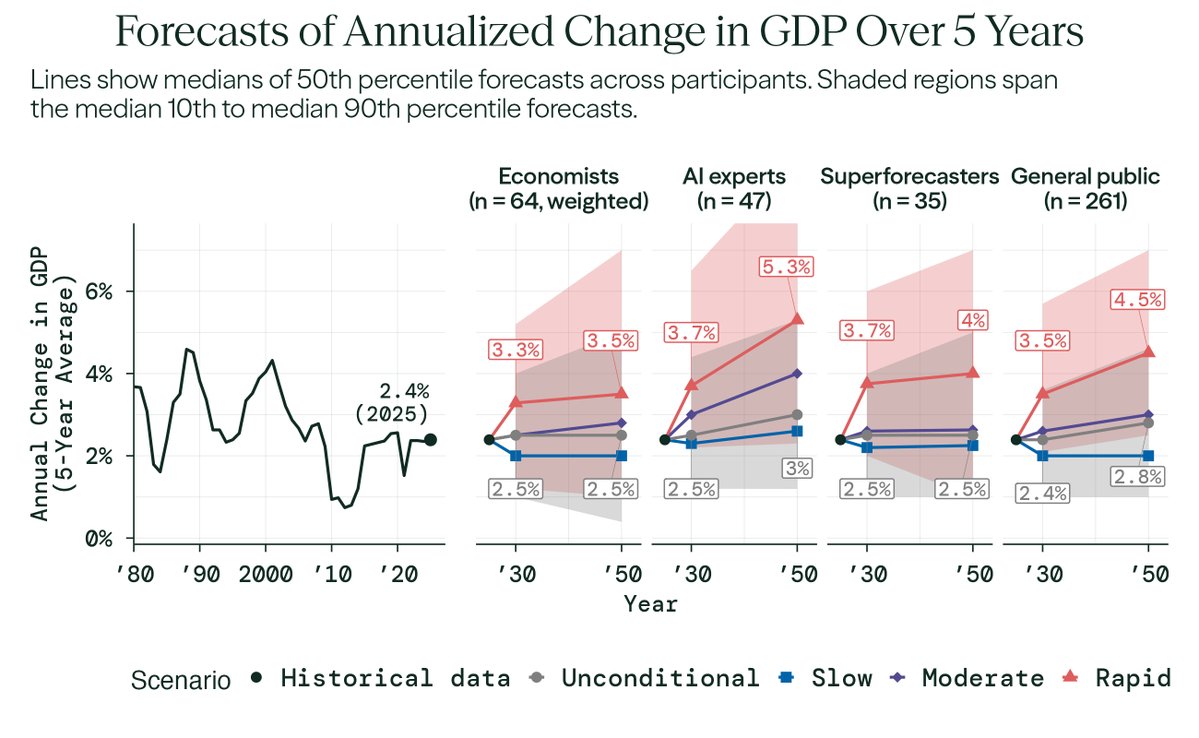
We completed the most comprehensive study of how economists and AI experts think AI will affect the U.S. economy.
They predict major AI progress—but no dramatic break from economic trends: GDP growth rates similar to today's and a moderate decline in labor force participation.
However, when asked to consider what would happen in a world with extremely rapid progress in AI capabilities by 2030, they predict significant economic impacts by 2050:
• Annualized GDP growth of 3.5% (compared to 2.4% in 2025)
• A labor force participation rate of 55% (roughly 10 million fewer jobs)
• 80% of wealth held by the top 10% (highest since 1939)
🧵 Here's what we found:
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control.
The result: our first Frontier Risk Report.
Sincitium is finally here.
We are pleased to present our latest piece: a concept trailer created specifically for the @runwayml Big Pitch Contest. For this project, we wanted to explore a completely different aesthetic from our usual studio style, and this film is the result of that experimentation.
We hope you enjoy it as much as we enjoyed the creative process.
Produced by: Contanimation
Directed by: Javier De La Chica and Guillermo Miranda Art Direction: Javier De La Chica
Editing: Guillermo Miranda
Voices: Juan Rabadán
#runwaybigpitchcontest
The quality of animation you can create on your own is truly amazing. We really are just limited by our imaginations at this point. Go tell your story!
Made in @runwayml in a few hours and a handful of gens.
Karpathy's Confusion Protocol is now in GStack
Karpathy called it: the #1 AI coding failure mode is the agent confidently picking the wrong path at an ambiguous decision point. You lose 10 minutes of work and have to start over.
gstack now has an ambiguity gate built into every workflow. Hit a fork in architecture, data modeling, or a destructive operation with unclear scope? The agent stops and asks. No more “I assumed you wanted…”
Not a blunt “confirm everything” prompt. Scoped to decisions where guessing wrong actually costs you time.
I just launched /office-hours skill with gstack.
Working on a new idea? GStack will help you think about it the way we do at YC.
(It's only a 10% strength version of what a real YC partner can do for you, but I assure you that is quite powerful as it is.)
nanochat now trains GPT-2 capability model in just 2 hours on a single 8XH100 node (down from ~3 hours 1 month ago). Getting a lot closer to ~interactive! A bunch of tuning and features (fp8) went in but the biggest difference was a switch of the dataset from FineWeb-edu to NVIDIA ClimbMix (nice work NVIDIA!). I had tried Olmo, FineWeb, DCLM which all led to regressions, ClimbMix worked really well out of the box (to the point that I am slightly suspicious about about goodharting, though reading the paper it seems ~ok).
In other news, after trying a few approaches for how to set things up, I now have AI Agents iterating on nanochat automatically, so I'll just leave this running for a while, go relax a bit and enjoy the feeling of post-agi :). Visualized here as an example: 110 changes made over the last ~12 hours, bringing the validation loss so far from 0.862415 down to 0.858039 for a d12 model, at no cost to wall clock time. The agent works on a feature branch, tries out ideas, merges them when they work and iterates. Amusingly, over the last ~2 weeks I almost feel like I've iterated more on the "meta-setup" where I optimize and tune the agent flows even more than the nanochat repo directly.
I lied. pi 0.37.8 is my final holiday gift.
npm install -g @mariozechner/pi-coding-agent
git clone https://t.co/mHjY7L61o5
pi -r pi-doom
/doom
Enjoy DOOM in your coding harness*
*terminals with Kitty keyboard protocol support only
🤔First Text/Image-to-3D Skill?
🔥Claude Code just made a selfie for @grok & itself instantly with Rodin #3D#Skill 😂
🚀Quick Setup:
/plugin marketplace add DeemosTech/rodin3d-skills
/plugin install rodin3d-skill@rodin3d-skills
Free to use! Just ask #Claude to generate🎨
We're experimenting with ways to keep AI agents in sync with the exact framework versions in your projects. Skills, 𝙲𝙻𝙰𝚄𝙳𝙴.𝚖𝚍, and more.
But one approach scored 100% on our Next.js evals:
https://t.co/8ACw9BgudB
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.