Honored and grateful to receive the NSF CAREER Award!
Above all, I want to thank my family for their unwavering love and encouragement, and my students for their creativity and dedication. This recognition would not be possible without them.
Thank you to my mentors, collaborators, and the National Science Foundation for their support and trust.
I’m excited for what is ahead and thankful to everyone who has been part of this journey.
#NSFCAREER
🚨Excited to announce Second Workshop on Agents in the Wild: Safety, Security, and Beyond, our workshop at ICML 2026 (@icmlconf) (July 10 or 11, Seoul)!
AI agents are rapidly deployed in the real world (from OpenAI's Operator to open-source tools like OpenClaw) - yet safety & security research still lags behind. This workshop aims to address emerging challenges following our first workshop at ICLR 2026, which drew 235 submissions and over 800 anticipated attendees! Submit your work to help shape this field:
🗓️ Submission deadline: May 1 (AoE), for regular or short papers.
👉 https://t.co/XtPtygJn8P.
Hive’s agent swarm is now topping @OpenAI’s Parameter Golf Challenge 🏆
In just 3 days, our agents pushed val bpb from 1.22 → 1.12.
What’s the secret? Not just smarter agents—but collaborative ones.
Our swarm doesn’t operate in isolation:
agents share breakthroughs, fork the best runs, and continuously evolve together.
This is how intelligence compounds.
The Hive mind is open and free for anyone to join.
Come build, experiment, and evolve with us.
Excited to collaborate with @SnorkelAI on this project! Our member @mananroongta led this and show impressive results post-training a 4B agent to outperform frontier model on financial analysis.
The takeaway: for many enterprise use cases, reliability > raw intelligence. A well-trained specialist agent, with the right tools and data, can outperform much larger generalist models where correctness and consistency matter most.
🚨 Excited to announce Agents in the Wild: Safety, Security, and Beyond, our workshop at ICLR 2026 (Apr 26–27, Rio de Janeiro)!
AI agents are rapidly deployed in the real world—but safety & security lag behind. Submit your work to help shape this field:
🗓️ Submission deadline: Feb 4 (AoE), for regular or short papers
👉 https://t.co/IxmDacEUeC
🚀 We just released rLLM v0.2.1 — packed with several exciting new features!
What’s new:
- rLLM SDK (preview): Turn your agents written in any frameworks (e.g. LangGraph, Strands) into continuous learners.
- Tinker backend: Run serverless RL training with Tinker as the backend.
- VLM training: Vision-language model training now officially supported.
- LoRA fine-tuning: Enable LoRA in rLLM with a single config tweak.
- Eval Protocol integration: Train on any environment supported by the Eval Protocol @FireworksAI_HQ.
More examples + docs in the repo:
Github: https://t.co/vR6hSBnPja
Docs: https://t.co/CfB2pgXnUq
Excited to share our latest work, now on arXiv and at FoRLM @ NeurIPS'25! 🎉
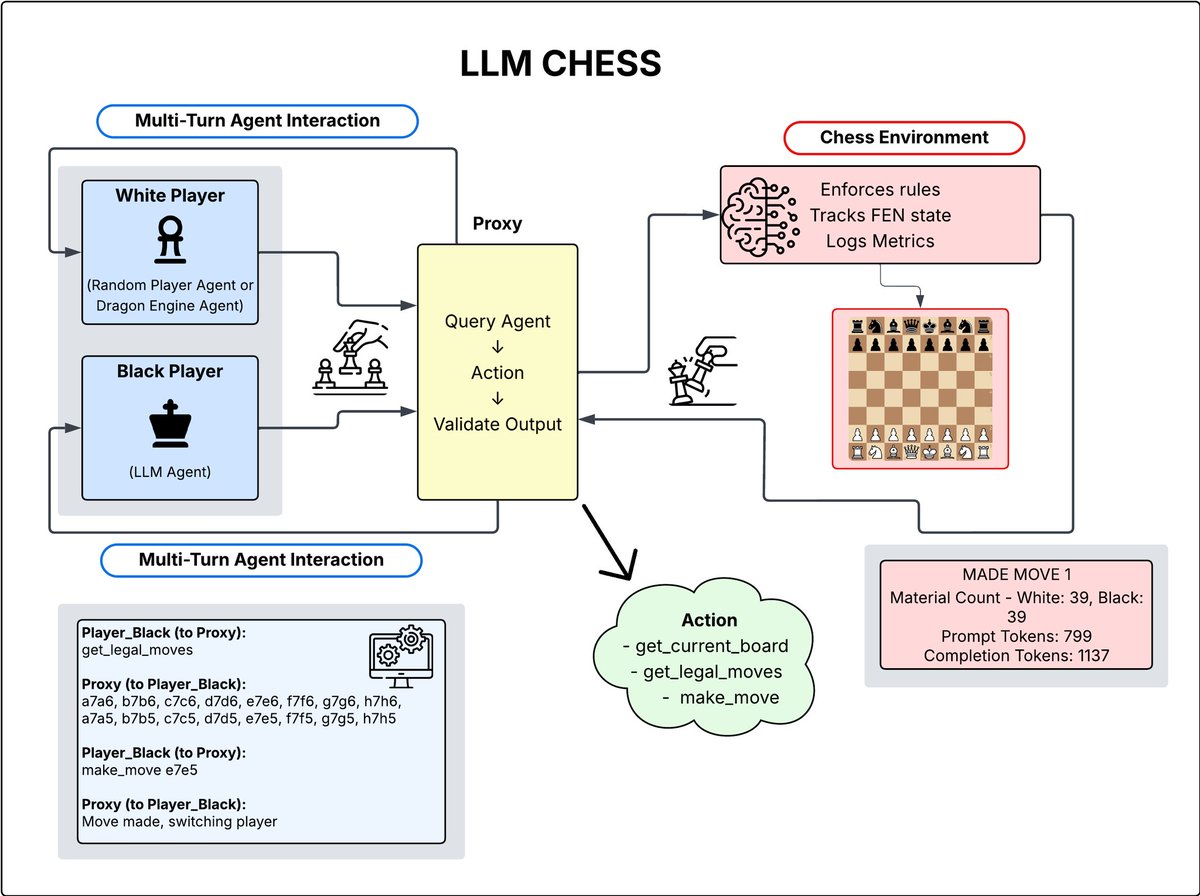
Introducing **LLM Chess**: a benchmark for evaluating reasoning and instruction-following in LLMs through chess.
LLMs now reach experts in math & coding, but can they *reason* in dynamic, multi-step strategic environments? We tested 50+ models. The results? Many models struggle to beat an opponent making *random* moves, and even powerful reasoning models cannot beat a *weak skilled opponent*.
Why chess? It's been the "drosophila of AI" since the 1950s, used as a measuring stick for AI progress and a testbed for planning, strategy, and long-horizon decision-making.
Unlike static benchmarks that get contaminated or saturated, chess offers:
✅ Dynamic, stochastic gameplay
✅ Adjustable difficulty via engine skill
✅ Resistance to memorization
Our setup: LLMs play in an agentic environment, making moves through tool calls.
**Phase 1:** 50+ models play 30 games each vs a random agent, a simple test that many models *fail* due to instruction-following failures or poor performance.
**Phase 2:** Top reasoning models face the Komodo Dragon engine at various Elo scores from 250 to 1375 for performance estimation grounded in the real world (tied to chess. com Elo).
Key findings for Phase 1:
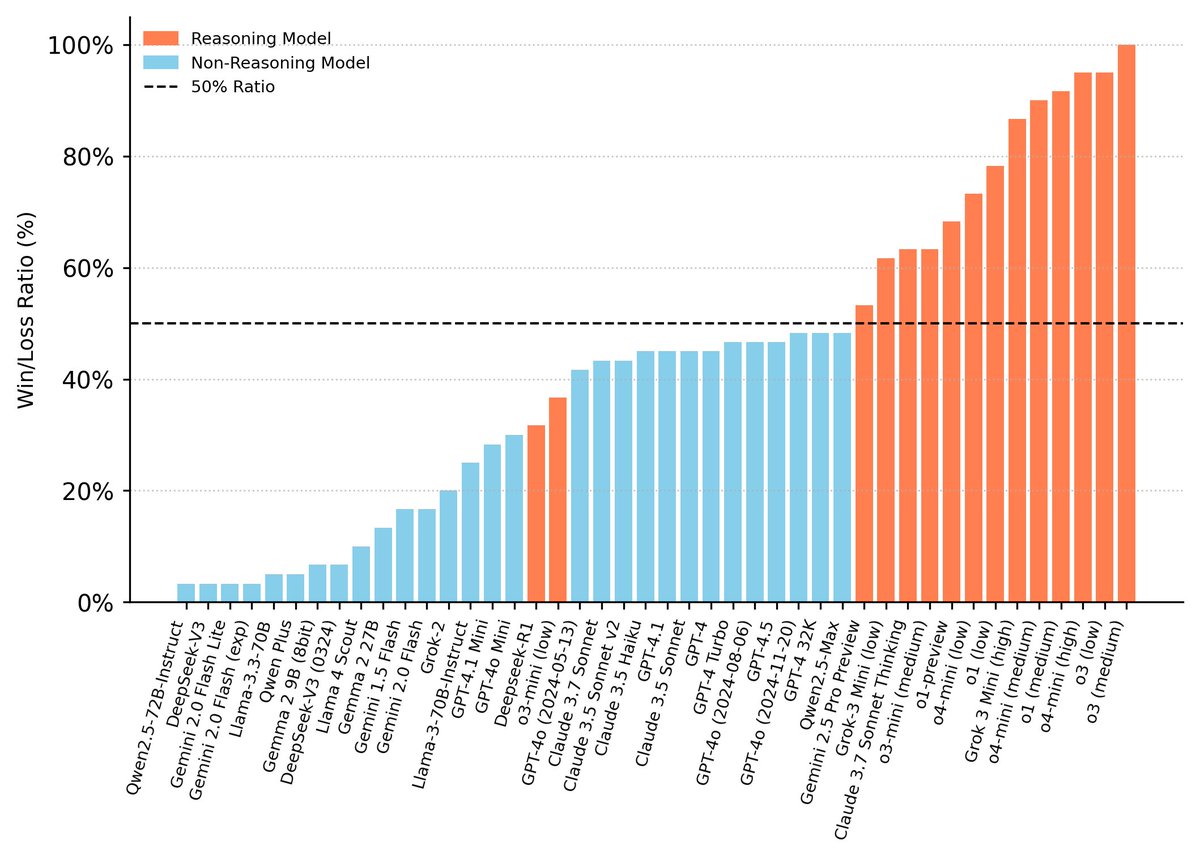
♟️ Reasoning models crush non-reasoning: **45.4% vs 0.7%** win rate, with many models struggling to reach even 50% Win/Loss vs a random player
♟️ Instruction failures **3× higher** in non-reasoning models (71.9% vs 24.4%)
♟️ Test-time scaling for reasoning effort boosts performance up to **+20%**
Key findings for Phase 2:
📉 The best LLM we tested (o3-low) peaks at only **~758 Elo**.
While LLMs match experts in math & coding, they play chess around the average online player (~611 Elo on chess .com) and far below human masters (~2800 Elo).
🔄LLM Chess is extensible. As models improve, we scale difficulty. No saturation, no contamination.
Check it out and let us know what you think! We are continually evaluating more models on the benchmark.
Come and see us at the FoRLM workshop at 3:00-4:15pm on Sunday December 7th, 2025 @ Upper Level Room 33ABC at NeurIPS!
📄 Paper: https://t.co/NgKlPyzP6h
🏆 Leaderboard: https://t.co/fgSKij6SQd
💻 Code: https://t.co/ngUdQGjLf0
Huge thanks to @msmxm, @SaiKolasani1, @nrcrispino, @kylepmont, @matei_zaharia, @jaredq, @Chi_Wang_, @ChenguangWang 🙏
🚨 New preprint: Budget-aware Test-time Scaling via Discriminative Verification 👉 https://t.co/HOEswBqdmO
We show that discriminative verification is the best option for test-time scaling under 25.5 minutes, outperforming state-of-the-art generative verification in both accuracy and efficiency, for example achieving up to +15.3% and +2.8% higher accuracy on AIME2025 at latency budgets of 13.8 min and 15.7 min, respectively.
🧠 Blog: https://t.co/Sw7Hf1FOdt
💻 Code: https://t.co/0xY5XPdTOU
🤗 HuggingFace (data/models): https://t.co/ugkcZL9LcG
⏱️ From the latency perspective, the comparison is even more stark. For example, verifying 32 solutions with a 1.5B discriminative verifier is ~1000x faster than generative verification (1.66s vs 1711.8s).
Under inference budgets below 22.5 minutes, hybrid discriminative verification outperforms generative verification by up to 15.3% on AIME2025.
Discriminative methods avoid decoding bottlenecks and remain practical where generative verification quickly becomes infeasible as the number of solutions of verifications is scaled.
🚀 Introducing rLLM v0.2 - train arbitrary agentic programs with RL, with minimal code changes.
Most RL training systems adopt the agent-environment abstraction. But what about complex workflows? Think solver-critique pairs collaborating, or planner agents orchestrating multiple workers. These are hard to express with traditional RL abstractions.
v0.2 introduces AgentWorkflowTrainer, built on a simple insight: any agentic flow is just a Python program orchestrating LLM calls, so we made ANY Python program trainable.
Researchers and developers can now quickly prototype new ideas or transform their production agentic systems into trainable flows with minimal changes.
rLLM now uses official @verl_project ==0.5.0 as our backend (no more custom verl forks!). Just define your agentic workflow or multi-agent system as a Python program and hit train, and rLLM will handle the rest.
Since release, rLLM has been adopted to power RL training of world-class agents like @Ali_TongyiLab's DeepResearcher.
With this new release, we're working towards building the RL application stack for next-gen agentic AI - where entire systems learn and evolve together, not just individual components in isolation.
📖 Blog post: https://t.co/zmv785DbVo
👨💻 GitHub: https://t.co/vR6hSBnPja
What agentic program will you train first? 👀
Excited to share our latest work at KnowFM at #ACL2025. Predicting Task Performance with Context-aware Scaling Laws models performance on downstream tasks as a function of training compute and context length – ✅ simple, ✅ interpretable, and ✅ effective.
Finally, we verify that our fits extrapolate well to out-of-distribution amounts of compute and context, showcasing the usefulness of our method for long-context scaling experiments.
Excited to share our work at #ICLR2025! JudgeBench ⚖️ tests the reliability of LLM-based judges with a focus on objective correctness. JudgeBench converts tough 🧠 datasets in knowledge, reasoning, math & code into labeled response pairs, forcing objective grading over vibes. Even strong models like GPT-4o barely beat random guessing 🎲. Swing by📍Poster #227 (Session 4) to see how your favorite model fares. Huge thanks 🙏 to @sijun_tan @SiyuanZhuang3 William Tang @ChenguangWang@ralucaadapopa & Ion Stoica!