GH Copilot (VSCode Insider Preview) has added the context window stats... Eventually. And what a discovery, GPT-5.2 has just 128K context window (out of 272K allowed by the model)
♟️Excited to share that our work LLM Chess! It’s a clean, scalable benchmark showing that even today’s top LLMs still struggle with strategic reasoning and instruction-following in dynamic environments.
📄 Paper: https://t.co/WNZUlFJC7E
🏆 Leaderboard: https://t.co/2L4Nixezpc
💻 Code: https://t.co/lpJSRcumgS
🎯Why Chess? Chess is the original AI challenge: strategic, long-horizon, and grounded. It’s also a clean test for LLMs: no contamination, no memorization, and difficulty scales with progress.
🔑• 50+ models including GPT-o3 @OpenAI, Gemini @Google, Claude @AnthropicAI, DeepSeek @deepseek_ai, Llama @Meta, @Alibaba_Qwen evaluated via agentic gameplay.
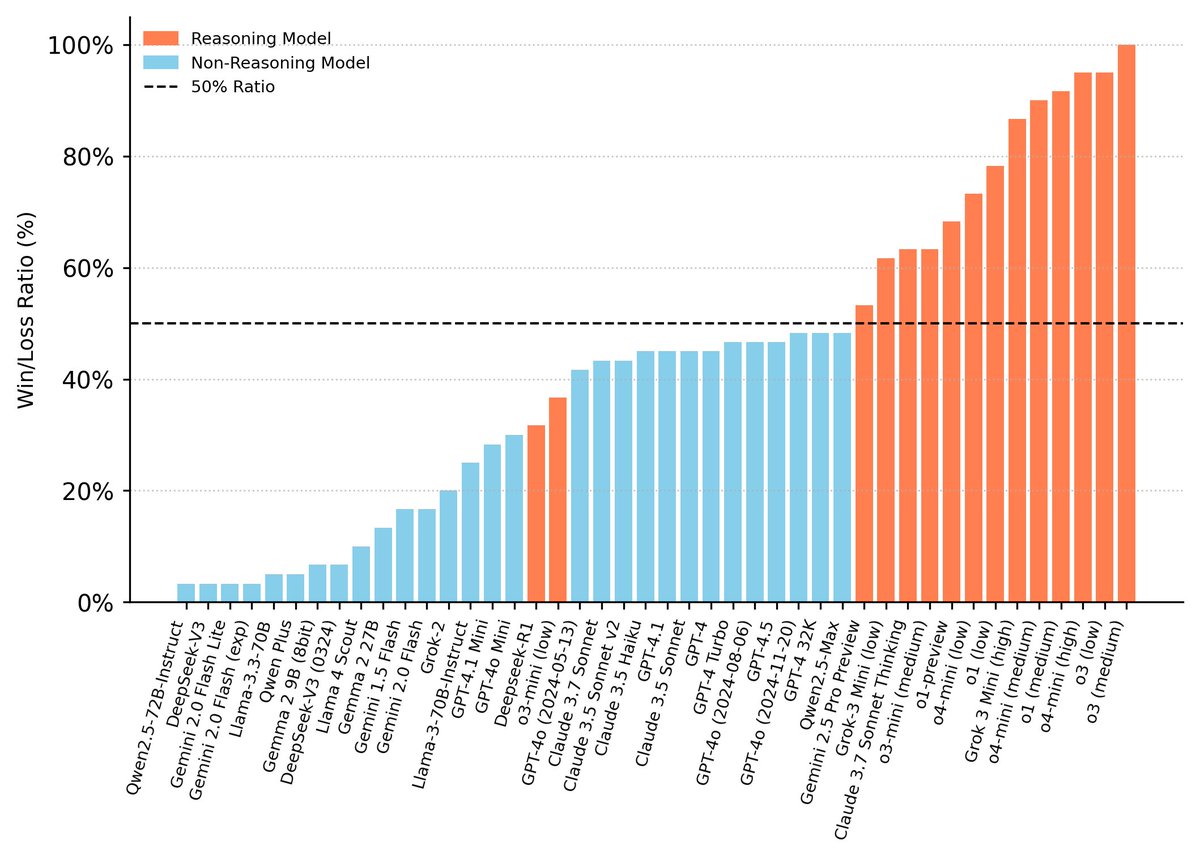
• Reasoning models do much better than non-reasoning, yet many still can’t beat random play.
• Top models reach ~758 Elo: good, but nowhere near strong humans.
🧑🤝🧑 Thank you amazing collaborators @msmxm, @SaiKolasani1, @nrcrispino, @kylepmont, @matei_zaharia, @jaredq_, @Chi_Wang_!
📍The work will also be presented at NeurIPS FoRLM Workshop at Sun, Dec 7 3:00–4:15pm PT in Upper Level Room 33ABC. Come chat with us and check out the live leaderboard!
Excited to share our latest work, now on arXiv and at FoRLM @ NeurIPS'25! 🎉
Introducing **LLM Chess**: a benchmark for evaluating reasoning and instruction-following in LLMs through chess.
LLMs now reach experts in math & coding, but can they *reason* in dynamic, multi-step strategic environments? We tested 50+ models. The results? Many models struggle to beat an opponent making *random* moves, and even powerful reasoning models cannot beat a *weak skilled opponent*.
Why chess? It's been the "drosophila of AI" since the 1950s, used as a measuring stick for AI progress and a testbed for planning, strategy, and long-horizon decision-making.
Unlike static benchmarks that get contaminated or saturated, chess offers:
✅ Dynamic, stochastic gameplay
✅ Adjustable difficulty via engine skill
✅ Resistance to memorization
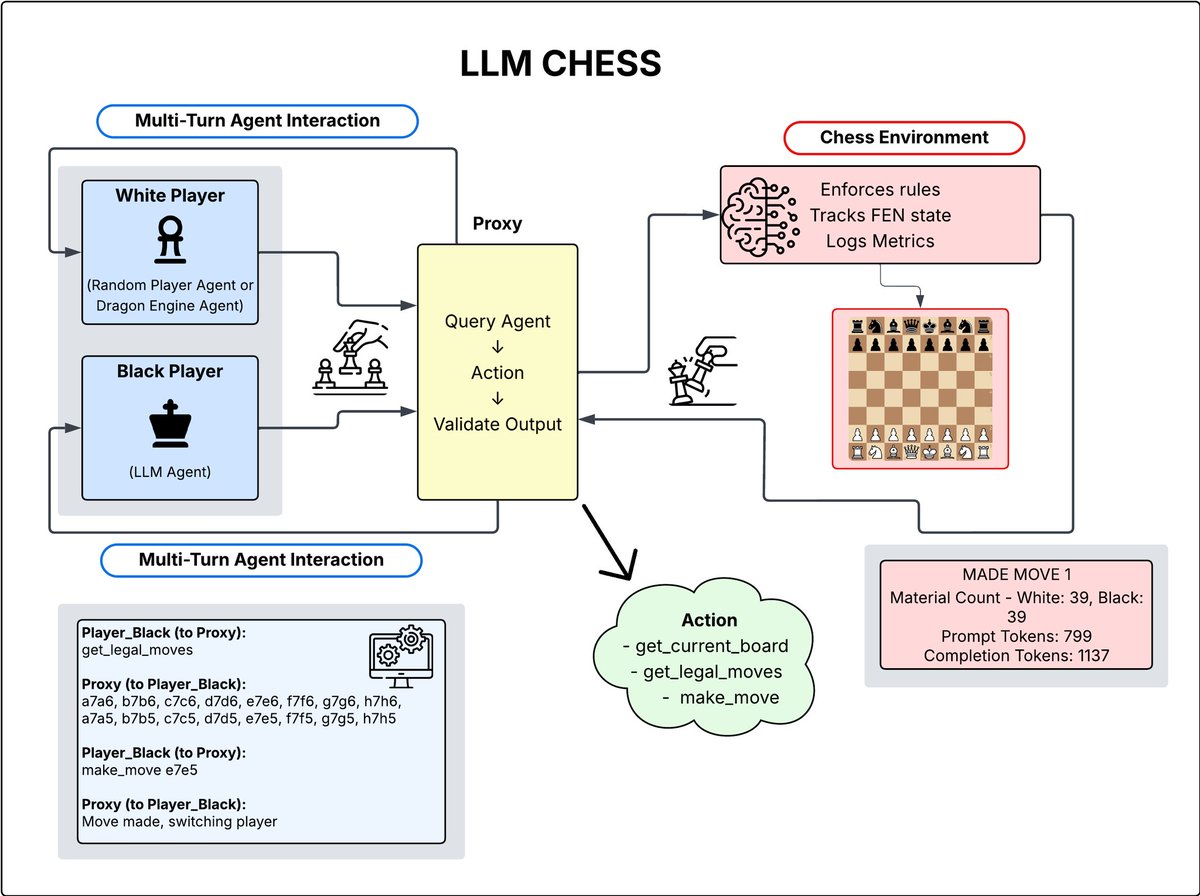
Our setup: LLMs play in an agentic environment, making moves through tool calls.
**Phase 1:** 50+ models play 30 games each vs a random agent, a simple test that many models *fail* due to instruction-following failures or poor performance.
**Phase 2:** Top reasoning models face the Komodo Dragon engine at various Elo scores from 250 to 1375 for performance estimation grounded in the real world (tied to chess. com Elo).
Key findings for Phase 1:
♟️ Reasoning models crush non-reasoning: **45.4% vs 0.7%** win rate, with many models struggling to reach even 50% Win/Loss vs a random player
♟️ Instruction failures **3× higher** in non-reasoning models (71.9% vs 24.4%)
♟️ Test-time scaling for reasoning effort boosts performance up to **+20%**
Key findings for Phase 2:
📉 The best LLM we tested (o3-low) peaks at only **~758 Elo**.
While LLMs match experts in math & coding, they play chess around the average online player (~611 Elo on chess .com) and far below human masters (~2800 Elo).
🔄LLM Chess is extensible. As models improve, we scale difficulty. No saturation, no contamination.
Check it out and let us know what you think! We are continually evaluating more models on the benchmark.
Come and see us at the FoRLM workshop at 3:00-4:15pm on Sunday December 7th, 2025 @ Upper Level Room 33ABC at NeurIPS!
📄 Paper: https://t.co/NgKlPyzP6h
🏆 Leaderboard: https://t.co/fgSKij6SQd
💻 Code: https://t.co/ngUdQGjLf0
Huge thanks to @msmxm, @SaiKolasani1, @nrcrispino, @kylepmont, @matei_zaharia, @jaredq, @Chi_Wang_, @ChenguangWang 🙏
@_jasonwei@ren_hongyu@shengjia_zhao I am curious how o3 fairs in chess (e.g. https://t.co/Gdse738eek) - chat models struggle to score even a single win against a random player
2 studies published in September 2024 and investigating the same subject, impact of GitHub CoPilot on dev productivity, draw opposite conclusions:
👍 https://t.co/tgS3lC7pzj - 26% more completed tasks
👎https://t.co/aC3LhwCRa5 - no change in cycle time, 46% more bugs
@bindureddy With HumanEval being available on the internet for more than 3 years, I see no point in reporting this value, assuming most of the models could have memorized it multiple times..
Sundman's general solution to the 3 body problem would involve at least [10 to the power of 8 million] iterations to calculate coordinates of moving planets. There're [10 to the power of 80] atoms in the known universe.
Interestingly, those people who recently held my cassette player began their inspection of the device by trying to open the lid to look inside, pulling out the cassette. Only after that did they start pushing buttons or listening to the sound.
"BCG consultants solving business problems with OpenAI’s GPT-4 performed 23% worse than those without it, new study finds" Fortune title says
Yet, "using GPT-4 for creative product innovation outperformed the control group (those completed the task without using GPT-4) by 40%"