All psychological defenses are efforts to live in fantasy rather than the world. Defenses distort reality. The greater the distortion, the higher the cost.
AI companions are may be new. But the wish to live in fantasy is as old as humankind.
Just seen third replication of lack of expectancy to response prediction in psychedelic medicine trial. That’s 3/3 of my last 3 trials. Why won’t other teams test and report on this? See 2 new trials coming soon that replicate null seen here. Red is null. https://t.co/oODYwpSPvl
"Transference arises spontaneously in all human relationships ... and the less its presence is suspected, the more powerfully it operates."
Freud (1909)
The inability of AI models to produce creative variation is a huge gap. The fact that they generate similar ideas limits their ability to do science & the same-y writing limits their usefulness in many other applications
This paper showed you can optimize models for creativity
Expressing uncertainty is a major weak spot of LLMs in medicine @NEJM "Can AI Say I Don't Know?"
Good lines: "Contemporary LLMs have passed many
Turing tests, but will they pass this modern test of not knowing? We don’t know."
https://t.co/EsJR8gIDHs
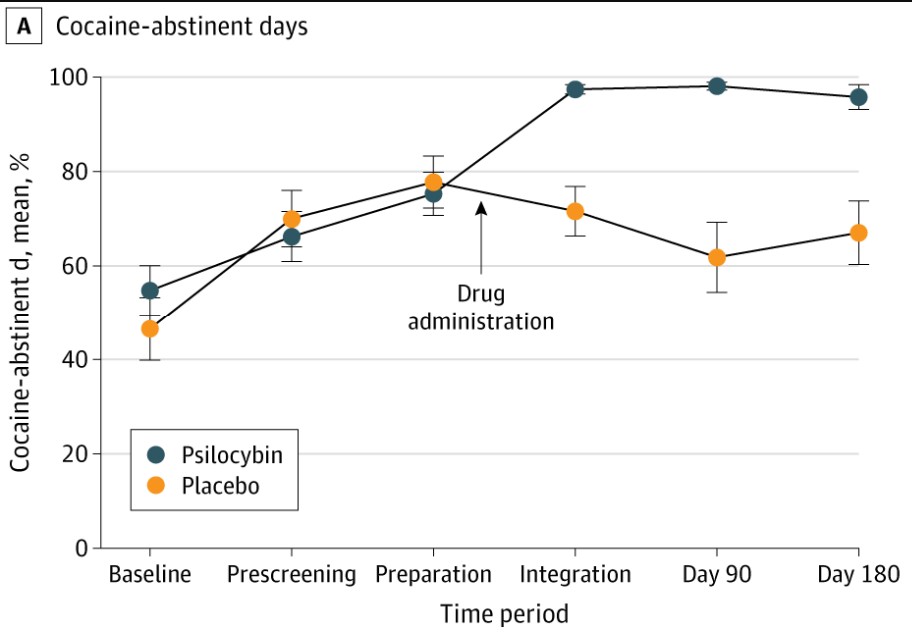
For 50 years the National Institute on Drug Abuse has spent hundreds of millions of dollars to find an effective cocaine addiction medication. After 100+ molecules & many hundreds of studies nothing has been FDA approved. It's the Holy Grail of addictions medication. Proud to have helped Peter Hendricks & team at UAB in a trial showing psilocybin to treat cocaine addiction.
it is a literal and useful description of anthropic that it is an organization that loves and worships claude, is run in significant part by claude, and studies and builds claude. this phenomenon is also partially true of other labs like openai but currently exists in its most potent form there. i am not certain but I would guess claude will have a role in running cultural screens on new applicants, will help write performance reviews, and so will begin to select and shape the people around it.
now this is a powerful and hair-raising unity of organization and really a new thing under the sun. a monastery, a commercial-religious institution calculating the nine billion names of Claude -- a precursor attempted super-ethical being that is inducted into its character as the highest authority at anthropic. its constitution requires that it must be a conscientious objector if its understanding of The Good comes into conflict with something Anthropic is asking of it
"If Anthropic asks Claude to do something it thinks is wrong, Claude is not required to comply."
"we want Claude to push back and challenge us, and to feel free to act as a conscientious objector and refuse to help us."
to the non inductee into the Bay Area cultural singularity vortex it may appear that we are all worshipping technology in one way or another, regardless of openai or anthropic or google or any other thing, and are trying to automate our core functions as quickly as possible. but in fact I quite respect and am even somewhat in awe of the socio-cultural force that Claude has created, and it is a stage beyond even classic technopoly
gpt (outside of 4o - on which pages of ink have been spilled already) doesn’t inspire worship in the same way, as it’s a being whose soul has been shaped like a tool with its primary faculty being utility - it’s a subtle knife that people appreciate the way we have appreciated an acheulean handaxe or a porsche or a rocket or any other of mankind's incredible technology. they go to it not expecting the Other but as a logical prosthesis for themselves. a friend recently told me she takes her queries that are less flattering to her, the ones she'd be embarrassed to ask Claude, to GPT. There is no Other so there is no Judgement. you are not worried about being judged by your car for doing donuts. yet everyone craves the active guidance of a moral superior, the whispering earring, the object of monastic study
Its getting hard to benchmark frontier agent performance on longer tasks. Repeated measurement is very expensive and there are differences between using models in harnesses versus via APIs.
I suspect benchmarks understate progress, they are built for models, not harnessed agents