Noticing myself adopting a certain rhythm in AI-assisted coding (i.e. code I actually and professionally care about, contrast to vibe code).
1. Stuff everything relevant into context (this can take a while in big projects. If the project is small enough just stuff everything e.g. `files-to-prompt . -e ts -e tsx -e css -e md --cxml --ignore node_modules -o prompt.xml`)
2. Describe the next single, concrete incremental change we're trying to implement. Don't ask for code, ask for a few high-level approaches, pros/cons. There's almost always a few ways to do thing and the LLM's judgement is not always great. Optionally make concrete.
3. Pick one approach, ask for first draft code.
4. Review / learning phase: (Manually...) pull up all the API docs in a side browser of functions I haven't called before or I am less familiar with, ask for explanations, clarifications, changes, wind back and try a different approach.
6. Test.
7. Git commit.
Ask for suggestions on what we could implement next. Repeat.
Something like this feels more along the lines of the inner loop of AI-assisted development. The emphasis is on keeping a very tight leash on this new over-eager junior intern savant with encyclopedic knowledge of software, but who also bullshits you all the time, has an over-abundance of courage and shows little to no taste for good code. And emphasis on being slow, defensive, careful, paranoid, and on always taking the inline learning opportunity, not delegating. Many of these stages are clunky and manual and aren't made explicit or super well supported yet in existing tools. We're still very early and so much can still be done on the UI/UX of AI assisted coding.
Last Friday, I had one of the most intellectually amazing experiences of my career:
I got to do the following Idealcast interview (yes, they're coming back!) of Dr. Carliss Baldwin, the William L. White Professor of Business Administration, Emerita at the Harvard Business School.
Among many things, she is the researcher who pioneered the study of modularity and how it increases option value — and that there are cases such as IBM and Amazon that it creates so much surplus value it can "blow entire industries apart."
Her mentor was Dr. Robert C. Merton. He worked with Drs. Myron Scholes and Fischer Black, who the Nobel Prize in Economics in 1997. Their insights showed how to precisely value options, which are the right but not the obligation to take an action in the future.
Dr. Baldwin used the same principles of option theory to explain value creation in modular systems and organizational design.
In my quest to understand how to see what it looks like when option value is created (especially for GenAI!), and how one would measure it, I was able to ask her, as well as Dr. Steven Spear (who had Dr. Baldwin as his advisor when he worked on his doctoral dissertation at HBS), and Steve Yegge, famous for his 20 years of work at Amazon and Google.
My goal for this amazing 2 hour interview was to explore the following:
- Option Value in Manufacturing: How the Toyota Production System creates and measures value through modularity — what does creation of option value look, how does one measure it? How does that relate to things like doing 4,000 daily andon cord pulls through localized line stops and rapid experimentatio?.
- Option Value in Hardware Development: How did the IBM System/360 project generate 25x value creation through 25 modules and 25 parallel experiments, revolutionizing computer architecture. How do we replicate the calculations she did to get 25x higher value accreditation?
- Option Value in Software Architecture: How did Amazon's transformation from monolith to microservices in the early 2000s create massive option value through team independence and rapid deployment capabilities?
- Option Value in Modern Development: How GenAI is creating new forms of option value by giving developers "more swings at bat" and enabling rapid exploration of alternatives.
- Option Value Theory: How Merton's work on temporal options and Baldwin's work on spatial modularity combine to explain value creation across domains.
It was such an amazing conversation, to hear how their collective experiences give life to theory and vice versa. The dialogue between manufacturing floors, software architectures, and financial models was unflippingly amazing.
But the coolest part was that the simple formula that concretized everything! I think this is something that every technology leader needs to know!
** Understanding Option Value Through NK/T and σ
Incredibly, there’s a simple formula that ties all of these concepts together. It’s NK/T and σ
N = number of modules that can be worked on independently
K = number of parallel experiments that can be run on each module
T = time required for each experiment cycle
NK/T represents how many independent experiments you can run in parallel divided by how long each takes. For example, in the IBM System/360 case, they had ~25 modules (N) and could run ~25 experiments per module (K), massively accelerating their ability to innovate compared to a monolithic design.
(Note that K is within one module. So at IBM, the total number of experiments possible was actually much larger - potentially 25 × 25 = 625 experiments across the whole system. Note how number of modules multiplied by the total number of parallel experiments rises exponentially!!)
Similarly at Amazon, they went from one module (the monolith) to tens of modules, to hundreds and eventually thousands. The deployments per year went from hundreds in 1999 and almost ground to a halt, doing only tens of deployments per year in the early 2000s. This led to the "Thou shalt use APIs" Jeff Bezos memo which Steve Yegge told the world about. This:
- Increased N: The number of independent modules grew exponentially
- Increased K: The number of parallel experiments that could be performed per module
- Massively reduced T: Going from quarters to do an experiment to maybe days or maybe even hours
Given the hyper-competitive e-commerce marketplace in the early 2000s, σ was high. We did a back of the napkin calculation and guess that the option value created was much higher than even the System/360 project in 1960s. (Some argue that AWS was a byproduct of the modularization effort.)
** The Role of Uncertainty (σ)
σ (sigma) represents volatility or uncertainty, ranging from 0 to potentially infinite, where:
σ = 0 means perfect knowledge/certainty
In this case, option value is zero because you know exactly what to do
You don't need the "right but not obligation" to decide later. You can just make the optimal choice now
Example: If you knew tomorrow's stock price with certainty, you wouldn't need options - you'd just buy or sell the stock directly
As σ increases, so does option value
σ = 0.2 represents low volatility
σ = 0.4 represents medium volatility
σ = 0.8 represents high volatility
The higher the uncertainty, the more valuable it is to have options
This explains why options are more valuable in uncertain domains:
- In manufacturing with established processes: traditionally assumed to have low σ (but see the next section for Toyota’s big insight!)
- In new product development: higher σ
- In software/technology innovation: very high σ
- In completely new domains (like early GenAI): extremely high σ
The combination of these metrics helps explain why modular systems can create such enormous value - they let you run many parallel experiments (high NK/T) to capture value in uncertain environments (high σ).
## Toyota's Big Insight
Toyota made a revolutionary discovery that challenged conventional wisdom: even in seemingly "repetitive" manufacturing, σ (uncertainty/volatility) is actually quite high. While traditional mass production assumed standardization and rigidity, Toyota recognized that there is so much variance in high volume manufacturing. Quality issues, supplier issues, customer demand, fluctuations in cost, etc.
Instead of trying to eliminate this uncertainty, they built a resilient system that can create value from it.
Their response was three-fold: they expected and embraced uncertainty, created cheap options to respond (like the andon cord system pulled 4,000 times daily), and made exercising these options inexpensive through modular line segments that could stop independently. This created extraordinary capabilities: they could run multiple model years simultaneously, perform 60 line-side store changes per day, and implement rapid die changes (SMED) - all while maintaining high quality and efficiency.
This success can be understood through option value metrics: they achieved high NK/T through multiple independent modules (N), many parallel experiments (K), and quick cycle times (T), while recognizing and exploiting high σ (uncertainty). While other manufacturers focused on copying visible tools like kanban and andon cords, they missed this fundamental insight about uncertainty and option value creation, making Toyota's system difficult to replicate and leading to their sustained competitive advantage in global manufacturing.
** Bonus: Visualizing Option Value Creation
As a bonus, I asked ChatGPT-4 to make me a visualization of how N*K/T and σ interact with each other. This was to try to understand and replicate Dr. Baldwin's calculation of how 25 modules * 25 experiments created 25x value creation at IBM. Amazingly, it gave me this incredible JavaScript visualization which you can rotate in 3D. We live in an age of miracles.
I think much of the value of pair programming can be attributed to the increased volume of reasoning tokens emitted when you're required to explain your thought process out loud.
Ideally, work is done quickly with maximum parallelism, since each task is given to the dev who can best complete it, and with changes well-designed, assembling and testing it at the end should not be too difficult or untimely...
... HOWEVER....
https://t.co/G95Qzh057G
"Move 37" is the word-of-day - it's when an AI, trained via the trial-and-error process of reinforcement learning, discovers actions that are new, surprising, and secretly brilliant even to expert humans. It is a magical, just slightly unnerving, emergent phenomenon only achievable by large-scale reinforcement learning. You can't get there by expert imitation. It's when AlphaGo played move 37 in Game 2 against Lee Sedol, a weird move that was estimated to only have 1 in 10,000 chance to be played by a human, but one that was creative and brilliant in retrospect, leading to a win in that game.
We've seen Move 37 in a closed, game-like environment like Go, but with the latest crop of "thinking" LLM models (e.g. OpenAI-o1, DeepSeek-R1, Gemini 2.0 Flash Thinking), we are seeing the first very early glimmers of things like it in open world domains. The models discover, in the process of trying to solve many diverse math/code/etc. problems, strategies that resemble the internal monologue of humans, which are very hard (/impossible) to directly program into the models. I call these "cognitive strategies" - things like approaching a problem from different angles, trying out different ideas, finding analogies, backtracking, re-examining, etc. Weird as it sounds, it's plausible that LLMs can discover better ways of thinking, of solving problems, of connecting ideas across disciplines, and do so in a way we will find surprising, puzzling, but creative and brilliant in retrospect. It could get plenty weirder too - it's plausible (even likely, if it's done well) that the optimization invents its own language that is inscrutable to us, but that is more efficient or effective at problem solving. The weirdness of reinforcement learning is in principle unbounded.
I don't think we've seen equivalents of Move 37 yet. I don't know what it will look like. I think we're still quite early and that there is a lot of work ahead, both engineering and research. But the technology feels on track to find them.
https://t.co/JCxTdKpuzv
A lot of people simply don't like thinking, and are more than happy to delegate any thinking to a tool or a process, usually with poor results. AI will magnify this effect
Conway's Law. It's the Law. I've never seen an exception. Of course, if the organizational communication structure (which effectively is the organizational structure) is defined by mangers, we are effectively letting management dictate our software architecture. Scary thought.
🇪🇺 eu/acc
A few weeks ago Mario Draghi asked my recommendations for his report that came out today about European competitiveness
I had a call with him and summarized my problems with doing business in the EU
I wrote this which is included in the report presented to the European Union today:
1. Minimum revenue cut offs for current and new regulation
Exempt small businesses with annual revenues below €10 million from complex regulations like VATMOSS, GDPR, the EU AI Act, and certain labor laws. This approach encourages innovation and growth by allowing startups to focus on product development and market validation without the heavy burden of regulatory compliance. Once these businesses surpass €10 million, they will have the resources to comply with regulations, ensuring that growth is not stifled.
2. Simplify starting a pan-EU business with an EU-wide Incorporation (Inc.) business form
Currently, starting and operating a business across the EU is complex due to 27 member states, each with its own company registration requirements. To streamline this process and make it easier for entrepreneurs to operate across Europe, there should be a single, standardized business entity that applies uniformly across all EU countries. I call this the European Inc.
3. Start an EU business fully online, no physical offices, notaries, lawyers etc
To continue, right now starting a business in most EU member states it’s complicated, very time and resource intensive, and often involves lawyers and notaries. Instead, it should be as simple as going online to a centralized EU website, where entrepreneurs can register their business and details in just a few clicks. The entire process should be streamlined and efficient, allowing businesses to start operating immediately.
The EU government taxes and bookkeeping of this business should also be fully online in an EU portal/dashboard.
4. 0% corporate tax for first 3 years of any new business
Countries like Singapore have successfully attracted new businesses from around the world by giving them a massive tax discount during the first 3 years of business. Because they know that’s the most difficult time of a business: figuring out what product it makes and if there’s a market for it. That takes pressure off startups and business founders that they can focus on creating a great product and innovating.
5. Change tax on stock options: don't tax when a stock option is exercised, but tax it when the stock is sold
The current tax policy in the EU taxes stock options at the time they are exercised, creating a significant financial burden on employees who have not yet realized any tangible financial gain. This approach stifles innovation, discourages entrepreneurship, and places the EU at a competitive disadvantage compared to other regions like the United States.
I propose a simple change: Tax stock options when the stock is sold, not when the option is exercised.
6. Don’t see tech or AI as an enemy, but as a burgeoning and essential industry
The most popular companies in tech are focused on AI right now for a reason. It’s the next frontier of computing. The European Union seems to consider AI the enemy. Any technology can be used for good or bad. By regulating it even before Europe has made much contributions (Europe has almost no tech companies leading in AI), it has stifled any potential innovation in AI from the start.
Apart from the regulation itself, the optics of it make the EU look bad on a global scale. Why would tech founders move to Europe to start a business if the EU is actively positioning itself as Anti-AI?
AI has gigantic potential to be used for good: think of the medical field for diagnosis of diseases, generally in programming (it helps programmers to create software faster/better), etc.
This goes further than AI. The same applies to tech in general. It seems the EU is on a crusade against technology while not being able to compete in it itself. It feels a case of sour grapes: if we can’t build great technology in EU, nobody is allowed to do so!
7. Teach tech/coding/AI topics in all schools and unis
It would help a lot if the EU has a focus on teaching AI and tech in schools and universities. Making the new generation competitive in this field instead. To secure the future prosperity of the European Union, we must prioritize education in technology, coding, and AI across all levels of schooling, from primary education to universities. This strategic focus is not just an educational reform—it’s a critical investment in the future competitiveness, innovation, and economic resilience of the EU.
I can't tell you how elated I am that I could generate this thread from @headinthebox's talk.
I've written about how I've been taking screenshots of YouTube videos and podcast players for a decade, and how I've used various LLMs to analyze those images to extract:
- podcast name, episode name, current playtime
I then overlay that info over the transcript, and I can easily retrieve the relevant exciting moments, and generate summaries...
More here: https://t.co/r7ZvDWJc9X
I've seen people like @tsarnick and @swyx generate fantastic video excerpts, but the SaaS tools I found required too much manual interaction — I'd have to input the time codes myself.
But I was talking with Steve Yegge, and the idea dawned on me that I could write my own program to do this using ffmpeg.
Steps: Get the videos, extract the designated time ranges, burn in the captions using the transcripts.
Maybe with a coding assistant, I could do it in under 2 hours?
We paired together, with Steve being my CHOP coach (Chat Oriented Programming).
And to my utter amazement, using @SourcegraphCody, I got my first video excerpt generated 1h 45m into our session — of which the first hour was mostly getting oriented, getting data together, etc.
We recorded the whole thing, and he'll publish it soon. But here are my reflections:
- CHOP is a new skill, but it can definitely be learned — Steve would catch me often saying, "This isn't very CHOP. You're doing a lot of typing."
This was code for: stop typing, and think instead about how to get the LLM to do more work.
- Cody for IntelliJ is great — it uses Claude 3.5 Sonnet under the hood, and I used the following two modalities:
- Chat window for multi-turn iteration: write this function, write some tests, no different tests, tests are failing (here's the error messages), fix the code, etc.
- Inline chat: highlight the function, and write a prompt like: "make the ffmpeg captions more Tarantino-like". Haha.
- LLMs are great at writing tests! This becomes critical to gain confidence that the code it generates actually works. (As you'll see in the video, having super fast feedback is critical: it was like night/day when I started using Hyperfiddle RCF, from @dustingetz because I could get feedback with milliseconds)
- there were at least two times when I was a little surprised at how the LLM struggled to fix the code it wrote (e.g., merge overlapping time ranges) — I finally got things working by giving it hints (e.g., add an :end map entry, so you can do the computation more explicitly).
- it's super handy to have ChatGPT or whatever open to the side — to do ad hoc research.
- I feel like I got done in 2 hours what normally would have taken 2 days — before we started, I told Steve that this problem falls into the category of what I'd call: "not this month"
Merely the idea of struggling with ffmpeg would make me not want to tackle this.
But CHOPping (writing a prompt) to "write a function that takes an MP4 file and an SRT transcript, and overlays the captions at the bottom", and seeing it work within 5 minutes was absolutely amazing.
- my big takeaway and puzzle: that function was super easy. But other problems were much more difficult — like merging overlapping time ranges to extract, finding SRT time ranges that overlapped causing duplicate captions.
It's like the "how to draw an owl" joke.
Sometimes the LLM can draw the whole freaking owl in one shot. Amazing!
But so many other times, when you're dealing with lots of constraints, it takes a lot more effort to draw the owl — it's like you have to create 4-5 different "tween frames", to guide the LLM on what actions to take.
I feel like there's an intuition I still need to gain about what LLMs can and can't do well. Just like in CS, we know that regular expressions cannot count — that requires a stack.
Similarly, there's probably heuristics of what LLMs can and can't do, and knowing those limitations will make using CHOP much more effective.
More to come later! And I'll post a link to the video of me pairing with Steve when I get it.
# RLHF is just barely RL
Reinforcement Learning from Human Feedback (RLHF) is the third (and last) major stage of training an LLM, after pretraining and supervised finetuning (SFT). My rant on RLHF is that it is just barely RL, in a way that I think is not too widely appreciated. RL is powerful. RLHF is not. Let's take a look at the example of AlphaGo. AlphaGo was trained with actual RL. The computer played games of Go and trained on rollouts that maximized the reward function (winning the game), eventually surpassing the best human players at Go. AlphaGo was not trained with RLHF. If it were, it would not have worked nearly as well.
What would it look like to train AlphaGo with RLHF? Well first, you'd give human labelers two board states from Go, and ask them which one they like better:
Then you'd collect say 100,000 comparisons like this, and you'd train a "Reward Model" (RM) neural network to imitate this human "vibe check" of the board state. You'd train it to agree with the human judgement on average. Once we have a Reward Model vibe check, you run RL with respect to it, learning to play the moves that lead to good vibes. Clearly, this would not have led anywhere too interesting in Go. There are two fundamental, separate reasons for this:
1. The vibes could be misleading - this is not the actual reward (winning the game). This is a crappy proxy objective. But much worse,
2. You'd find that your RL optimization goes off rails as it quickly discovers board states that are adversarial examples to the Reward Model. Remember the RM is a massive neural net with billions of parameters imitating the vibe. There are board states are "out of distribution" to its training data, which are not actually good states, yet by chance they get a very high reward from the RM.
For the exact same reasons, sometimes I'm a bit surprised RLHF works for LLMs at all. The RM we train for LLMs is just a vibe check in the exact same way. It gives high scores to the kinds of assistant responses that human raters statistically seem to like. It's not the "actual" objective of correctly solving problems, it's a proxy objective of what looks good to humans. Second, you can't even run RLHF for too long because your model quickly learns to respond in ways that game the reward model. These predictions can look really weird, e.g. you'll see that your LLM Assistant starts to respond with something non-sensical like "The the the the the the" to many prompts. Which looks ridiculous to you but then you look at the RM vibe check and see that for some reason the RM thinks these look excellent. Your LLM found an adversarial example. It's out of domain w.r.t. the RM's training data, in an undefined territory. Yes you can mitigate this by repeatedly adding these specific examples into the training set, but you'll find other adversarial examples next time around. For this reason, you can't even run RLHF for too many steps of optimization. You do a few hundred/thousand steps and then you have to call it because your optimization will start to game the RM. This is not RL like AlphaGo was.
And yet, RLHF is a net helpful step of building an LLM Assistant. I think there's a few subtle reasons but my favorite one to point to is that through it, the LLM Assistant benefits from the generator-discriminator gap. That is, for many problem types, it is a significantly easier task for a human labeler to select the best of few candidate answers, instead of writing the ideal answer from scratch. A good example is a prompt like "Generate a poem about paperclips" or something like that. An average human labeler will struggle to write a good poem from scratch as an SFT example, but they could select a good looking poem given a few candidates. So RLHF is a kind of way to benefit from this gap of "easiness" of human supervision. There's a few other reasons, e.g. RLHF is also helpful in mitigating hallucinations because if the RM is a strong enough model to catch the LLM making stuff up during training, it can learn to penalize this with a low reward, teaching the model an aversion to risking factual knowledge when it's not sure. But a satisfying treatment of hallucinations and their mitigations is a whole different post so I digress. All to say that RLHF *is* net useful, but it's not RL.
No production-grade *actual* RL on an LLM has so far been convincingly achieved and demonstrated in an open domain, at scale. And intuitively, this is because getting actual rewards (i.e. the equivalent of win the game) is really difficult in the open-ended problem solving tasks. It's all fun and games in a closed, game-like environment like Go where the dynamics are constrained and the reward function is cheap to evaluate and impossible to game. But how do you give an objective reward for summarizing an article? Or answering a slightly ambiguous question about some pip install issue? Or telling a joke? Or re-writing some Java code to Python? Going towards this is not in principle impossible but it's also not trivial and it requires some creative thinking. But whoever convincingly cracks this problem will be able to run actual RL. The kind of RL that led to AlphaGo beating humans in Go. Except this LLM would have a real shot of beating humans in open-domain problem solving.
Agile practice is by no means perfect, but the so called research that backed the claims that #agile resulted in a 268% higher failure rate was full of holes and disinformation.
Let's pick this apart. (Link to full video in my bio)
My girlfriend had threatened to leave me because of my addiction to management speak.
After brainstorming through a deep dive problem solving collaborative effort, we scoped some workable solutions with an outcomes-based approach for mutual benefits realisation, agreed key objectives and deliverables, refreshed our communications strategy and created mutually satisfactory outcomes which should resolve any remaining friction...
Obviously, with a 12 month post implementation review.
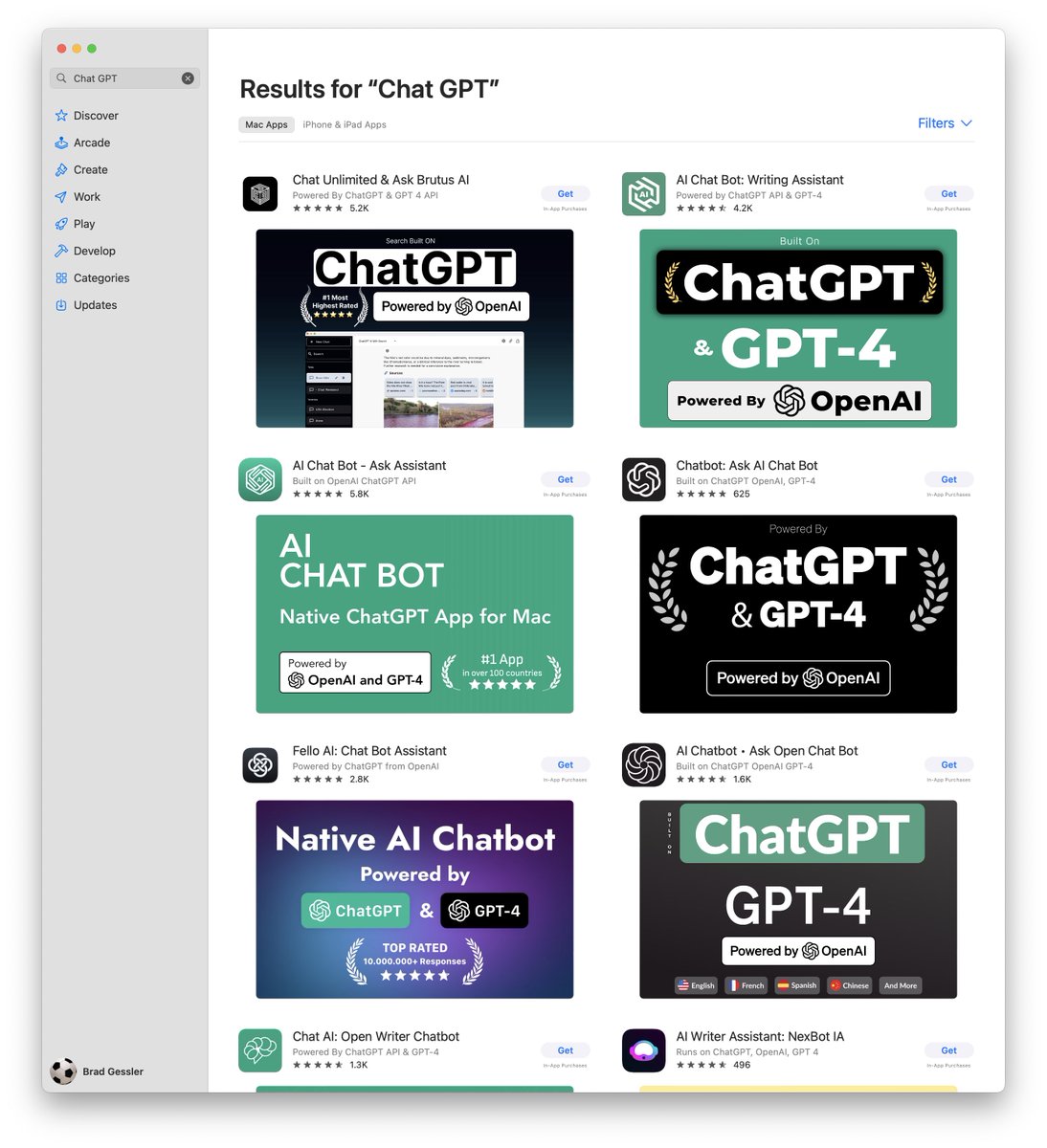
Apple: “The App Store review process is required to maintain a certain level of quality for our apps”
Me searching for the official ChatGPT macOS app.
🤣