Continuous diffusion dominates image & video generation, but people used to believe that it inherently lags behind its discrete counterparts in language modeling.
Today, we challenge this belief with LangFlow: the first continuous diffusion language model that rivals—and even beats—discrete diffusion. (1/7)
Blog: https://t.co/EtZRSx9MQv
GitHub: https://t.co/NgWUDDAXd6
Arxiv: https://t.co/2WfaQL7IZZ
A language is only as useful as the community speak it!
"Beyond the code, we have a community goal. We want to build the language of statistics in Lean together with statisticians and lean experts: shared design decisions, open discussion of architecture"
AI evaluation is entering an interactive benchmark era.
Across tool-use agents, web/OS benchmarks, multi-agent systems, and reliability evaluations, interaction is becoming central to how modern AI systems are tested.
But the field risks adding interaction faster than it develops the scientific principles for evaluating interaction.
Our position:
Interactive evaluation is not just longer tasks, tool use, or multi-turn interaction.
It requires a design science for mapping trajectories to valid evaluative claims.
📄 https://t.co/lKGuDOuBZy
💻 https://t.co/LkadiPYnnw
👋Excited to share our new work:
Taming Outlier Tokens in Diffusion Transformers
We found that outlier tokens are not only a ViT recognition problem — they also appear in modern diffusion pipelines and hurt generation quality.
📜Project-page: https://t.co/M1yWgZsNPD
Continuous diffusion dominates image & video generation, but people used to believe that it inherently lags behind its discrete counterparts in language modeling.
Today, we challenge this belief with LangFlow: the first continuous diffusion language model that rivals—and even beats—discrete diffusion. (1/7)
Blog: https://t.co/EtZRSx9MQv
GitHub: https://t.co/NgWUDDAXd6
Arxiv: https://t.co/2WfaQL7IZZ
@punyajoysaha Thank you for your attention. TESS series are great pretrained models while our work focuses on methodology at smaller scales for now. If we have the chance to scale up our model, we would love to compare it to TESS.
Thank you for the note. To our best knowledge, we believe LangFlow is the first to provide comprehensive and size-controlled ppl/gen ppl/entropy comparison across LM1B/OWT/zero-shot, and demonstrated clear win over best DDLM in significant portion of the tasks. We have included discussion on several brilliant recent concurrent work in DLMs, such as FMLM, we believe these few-step distillation techniques can be synergistically combined with our embedding-space DLM to further improve efficiency.
The potential of continuous DLMs extends far beyond just performance. They open the door for all continuous diffusion techniques to be introduced into language modeling:
- One-step generation, such as Consistency Models
- Guided generation, such as CFG
- Unified multimodal generation, such as protein structure-sequence co-design
LangFlow suggests: continuous diffusion is NOW a viable and promising paradigm for language modeling. (7/7)
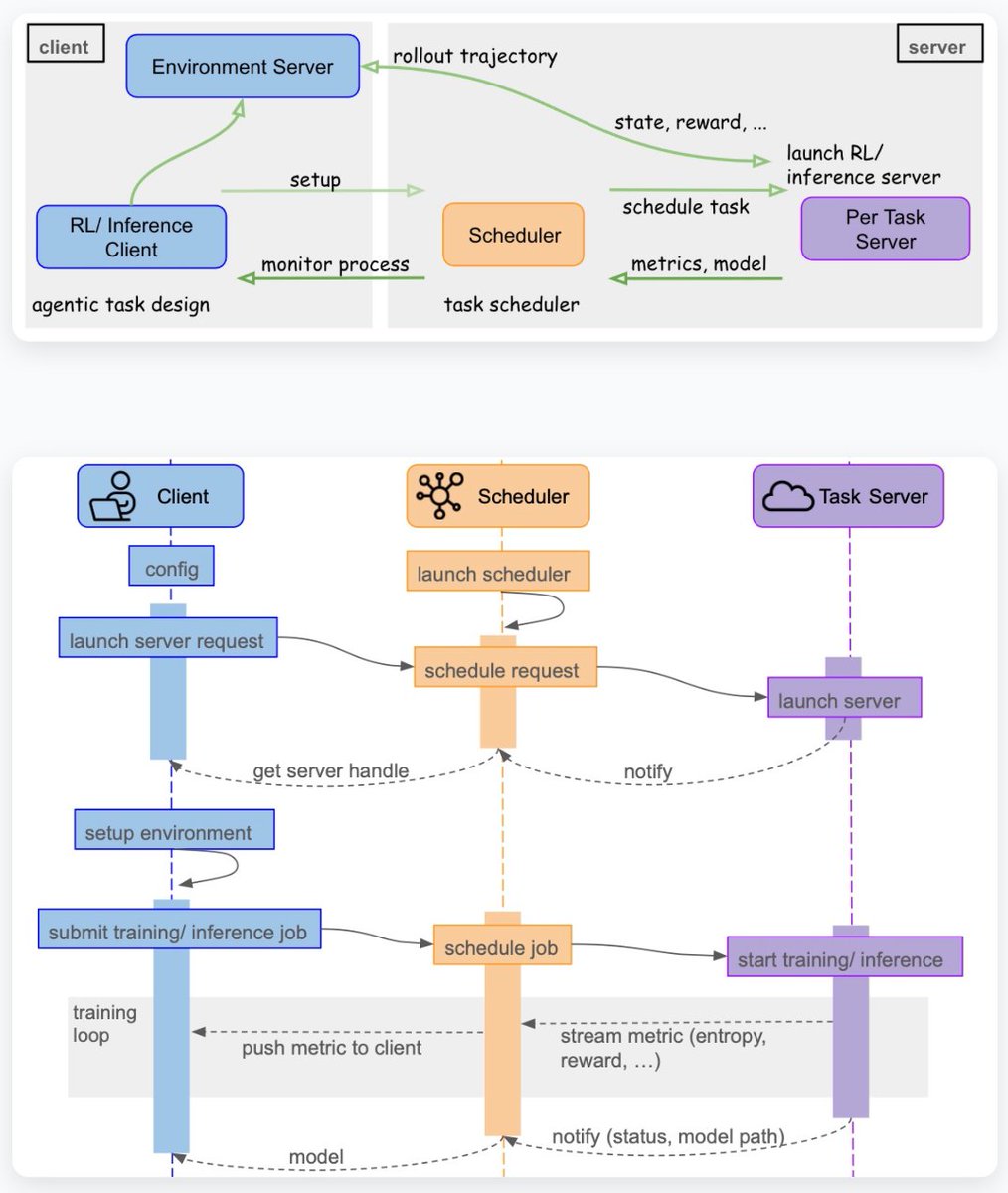
🚨 RL for LLMs is finally accessible.
Introducing OpenTinker: The first community-driven, open-source framework designed to democratize Reinforcement Learning for LLMs.
https://t.co/FdIed7MAWi
Inspired by @thinkymachines's amazing Tinker, we realize the biggest bottleneck in agentic LLM research isn’t the math—it’s the setup. Current RL pipelines are messy. Configuring VeRL for every single experiment is a productivity killer.
OpenTinker fixed it.
🛠 How OpenTinker Works: Decoupled Design of Server and Client
- Setup Once, Run Forever: Configure the OpenTinker backend on your GPU cluster once.
- Develop Locally: Define your RL environments directly on your laptop.
- Train on the Cloud: Simply point your local client to the backend. The cluster handles the compute; you handle the science.
📉 The 10x Development Efficiency
Thanks to our elegant architectural decomposition, OpenTinker reduces the time to develop a new RL training pipeline by at least an order of magnitude.
⚡ Turn Idle GPU Compute into Gold
Small labs often have underutilized hardware. OpenTinker turns your idle GPUs into an internal/external API service for
- RL Training
- SFT
- Inference
🎯 Who needs OpenTinker?
- Researchers tired of infrastructure hell.
- Labs needing to standardize workflows.
- Teams wanting to maximize hardware ROI.
Thanks my amazing PhD student @realagi25 for leading the project. We are building the future of open RL infra. Be the first to build with us.
👇 Start Building with OpenTinker Now
🚀 Repo: https://t.co/6wX4yQYdy3
🌐 Blog: https://t.co/QVg9LkWSIY
If you believe RL should be accessible to everyone, give us a star, repost this 🔄 post, and let us know what agents you plan to build!
(1/n) Tiny-A2D: An Open Recipe to Turn Any AR LM into a Diffusion LM
Code (dLLM): https://t.co/Nv7d1t8Qin
Checkpoints: https://t.co/rpibkb2Xfq
With dLLM, you can turn ANY autoregressive LM into a diffusion LM (parallel generation + infilling) with minimal compute. Using this recipe, we built a 🤗collection of the smallest diffusion LMs that work well in practice.
Key takeaways:
1. Finetuned on Qwen3-0.6B, we obtain the strongest small (~0.5/0.6B) diffusion LMs to date.
2. The base AR LM matters: Investing compute in improving the base AR model is potentially more efficient than scaling compute during adaptation.
3. Block diffusion (BD3LM) generally outperforms vanilla masked diffusion (MDLM), especially on math-reasoning and coding tasks.
Multi-Agent Evolve is now fully open-source 🚀
With our codebase, you can pick your favorite LLM checkpoint and let it self-evolve, WITHOUT external supervision
💻Code:
https://t.co/GSetfobMwE
🤗Model Checkpoints:
https://t.co/Bz583Rg1s0
Feedback and contributions are welcome!
We believe future forecasting is the ultimate challenge for agentic LLMs.
🚀 Live Trade Bench is now fully open-sourced!
It’s the first live, real-world benchmark testing 20+ LLMs on financial forecasting.
📄 Read our 37-page paper detailing insights from a 2-month live trading experiment:
👉 https://t.co/DjMkqwhutj
📊 Track real-time performance across 20 LLMs here:
👉 https://t.co/qukJ8UvgRo
💻 Developers interested in LLM benchmarking or trading? Try it out with:
pip install live-trade-bench
🔗 Code: https://t.co/ejWwDX3MCi
(1/n) 🚨 BERTs that chat: turn any BERT into a chatbot with diffusion
hi @karpathy, we just trained a few BERTs to chat with diffusion — we are releasing all the model checkpoints, training curves, and recipes! Hopefully this spares you the side quest into training nanochat with diffusion for now 🙂. It’s both a hands-on tutorial for beginners and an example showing how to use our complete toolkit (dLLM) for deeper projects.
Code: https://t.co/Nv7d1t8Qin
Report: https://t.co/sGKgA1Cz0O
Checkpoints: https://t.co/iluTMnHkQO
Motivation: I couldn’t find a good “Hello World” example for training a minimally working yet useful diffusion language models, a class of bidirectional language models capable of parallel token generation in arbitrary order. So I tried finetuning BERTs to make it chat with discrete diffusion—and it turned out more fun than I expected.
TLDR: With a small amount of open-source instruction-following data, a standard BERT can gain conversational ability with diffusion. Specifically, a finetuned ModernBERT-large, with a similar number of parameters, performs close to Qwen1.5-0.5B.