Higgsfield Video Face Swap is LIVE!
Another one, yes ✨
Upload a video and your face photo to put your face in any video you want.
The ultimate tool combining professional and daily use.
For the next 9 hours: Retweet + reply to get 200 credits straight in DMs.
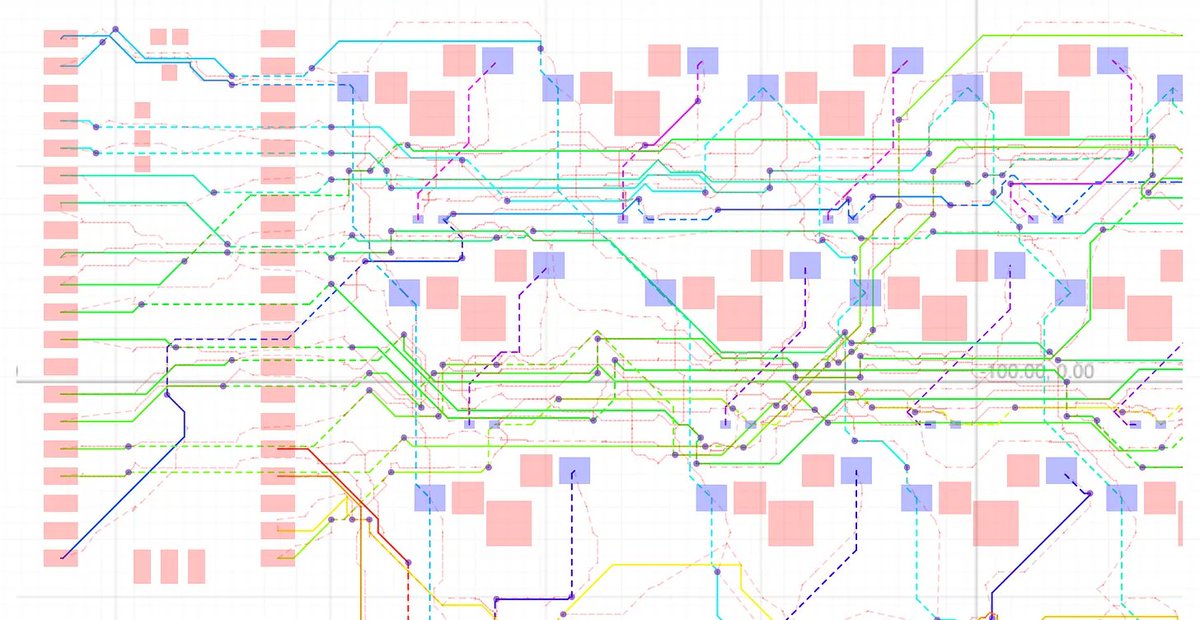
13 things I would have told myself before building an autorouter 🧵
I’ve spent about a year working on an autorouter for tscircuit (an open-source electronics CAD kernel written in Typescript). If I could go back a year, these are the 13 things I would tell myself
I don't have too too much to add on top of this earlier post on V3 and I think it applies to R1 too (which is the more recent, thinking equivalent).
I will say that Deep Learning has a legendary ravenous appetite for compute, like no other algorithm that has ever been developed in AI. You may not always be utilizing it fully but I would never bet against compute as the upper bound for achievable intelligence in the long run. Not just for an individual final training run, but also for the entire innovation / experimentation engine that silently underlies all the algorithmic innovations.
Data has historically been seen as a separate category from compute, but even data is downstream of compute to a large extent - you can spend compute to create data. Tons of it. You've heard this called synthetic data generation, but less obviously, there is a very deep connection (equivalence even) between "synthetic data generation" and "reinforcement learning". In the trial-and-error learning process in RL, the "trial" is model generating (synthetic) data, which it then learns from based on the "error" (/reward). Conversely, when you generate synthetic data and then rank or filter it in any way, your filter is straight up equivalent to a 0-1 advantage function - congrats you're doing crappy RL.
Last thought. Not sure if this is obvious. There are two major types of learning, in both children and in deep learning. There is 1) imitation learning (watch and repeat, i.e. pretraining, supervised finetuning), and 2) trial-and-error learning (reinforcement learning). My favorite simple example is AlphaGo - 1) is learning by imitating expert players, 2) is reinforcement learning to win the game. Almost every single shocking result of deep learning, and the source of all *magic* is always 2. 2 is significantly significantly more powerful. 2 is what surprises you. 2 is when the paddle learns to hit the ball behind the blocks in Breakout. 2 is when AlphaGo beats even Lee Sedol. And 2 is the "aha moment" when the DeepSeek (or o1 etc.) discovers that it works well to re-evaluate your assumptions, backtrack, try something else, etc. It's the solving strategies you see this model use in its chain of thought. It's how it goes back and forth thinking to itself. These thoughts are *emergent* (!!!) and this is actually seriously incredible, impressive and new (as in publicly available and documented etc.). The model could never learn this with 1 (by imitation), because the cognition of the model and the cognition of the human labeler is different. The human would never know to correctly annotate these kinds of solving strategies and what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome.
(Last last thought/reference this time for real is that RL is powerful but RLHF is not. RLHF is not RL. I have a separate rant on that in an earlier tweet
https://t.co/RMIpFPVpuM)
Google Quantum AI has launched a free quantum error correction course on @Coursera. From undergrads to researchers, discover this critical field. Enroll now: https://t.co/svLDyRGpac and learn more: https://t.co/gAKVRWMkt4
The (true) story of development and inspiration behind the "attention" operator, the one in "Attention is All you Need" that introduced the Transformer. From personal email correspondence with the author @DBahdanau ~2 years ago, published here and now (with permission) following some fake news about how it was developed that circulated here over the last few days.
Attention is a brilliant (data-dependent) weighted average operation. It is a form of global pooling, a reduction, communication. It is a way to aggregate relevant information from multiple nodes (tokens, image patches, or etc.). It is expressive, powerful, has plenty of parallelism, and is efficiently optimizable. Even the Multilayer Perceptron (MLP) can actually be almost re-written as Attention over data-indepedent weights (1st layer weights are the queries, 2nd layer weights are the values, the keys are just input, and softmax becomes elementwise, deleting the normalization). TLDR Attention is awesome and a *major* unlock in neural network architecture design.
It's always been a little surprising to me that the paper "Attention is All You Need" gets ~100X more err ... attention... than the paper that actually introduced Attention ~3 years earlier, by Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio: "Neural Machine Translation by Jointly Learning to Align and Translate". As the name suggests, the core contribution of the Attention is All You Need paper that introduced the Transformer neural net is deleting everything *except* Attention, and basically just stacking it in a ResNet with MLPs (which can also be seen as ~attention per the above). But I do think the Transformer paper stands on its own because it adds many additional amazing ideas bundled up all together at once - positional encodings, scaled attention, multi-headed attention, the isotropic simple design, etc. And the Transformer has imo stuck around basically in its 2017 form to this day ~7 years later, with relatively few and minor modifications, maybe with the exception better positional encoding schemes (RoPE and friends).
Anyway, pasting the full email below, which also hints at why this operation is called "attention" in the first place - it comes from attending to words of a source sentence while emitting the words of the translation in a sequential manner, and was introduced as a term late in the process by Yoshua Bengio in place of RNNSearch (thank god? :D). It's also interesting that the design was inspired by a human cognitive process/strategy, of attending back and forth over some data sequentially. Lastly the story is quite interesting from the perspective of nature of progress, with similar ideas and formulations "in the air", with a particular mentions to the work of Alex Graves (NMT) and Jason Weston (Memory Networks) around that time.
Thank you for the story @DBahdanau !
@alfcnz So yes, it sounds you use versioning, git it is 😂 Anyway my point was, the repo should contain the source, the product can be built by the puller. Unless there is a heavy computation that only you have access to. But it’s an abstract advice, I don’t have the full context. Cheers
@alfcnz Is it something the contributors and users need to work with or modify? If yes, LFS. If it’s just a visual aid - cloud storage will be enough and perhaps the best, imo
@alfcnz I think, it really depends on a use case. Perhaps, sharing weights via GitHub isn’t the best idea. Having diagrams in the repository is fine though. Of course, those are not the rules. Depends also on usage. =>
⚡️ Excited to share that I am starting an AI+Education company called Eureka Labs.
The announcement:
---
We are Eureka Labs and we are building a new kind of school that is AI native.
How can we approach an ideal experience for learning something new? For example, in the case of physics one could imagine working through very high quality course materials together with Feynman, who is there to guide you every step of the way. Unfortunately, subject matter experts who are deeply passionate, great at teaching, infinitely patient and fluent in all of the world's languages are also very scarce and cannot personally tutor all 8 billion of us on demand.
However, with recent progress in generative AI, this learning experience feels tractable. The teacher still designs the course materials, but they are supported, leveraged and scaled with an AI Teaching Assistant who is optimized to help guide the students through them. This Teacher + AI symbiosis could run an entire curriculum of courses on a common platform. If we are successful, it will be easy for anyone to learn anything, expanding education in both reach (a large number of people learning something) and extent (any one person learning a large amount of subjects, beyond what may be possible today unassisted).
Our first product will be the world's obviously best AI course, LLM101n. This is an undergraduate-level class that guides the student through training their own AI, very similar to a smaller version of the AI Teaching Assistant itself. The course materials will be available online, but we also plan to run both digital and physical cohorts of people going through it together.
Today, we are heads down building LLM101n, but we look forward to a future where AI is a key technology for increasing human potential. What would you like to learn?
---
@EurekaLabsAI is the culmination of my passion in both AI and education over ~2 decades. My interest in education took me from YouTube tutorials on Rubik's cubes to starting CS231n at Stanford, to my more recent Zero-to-Hero AI series. While my work in AI took me from academic research at Stanford to real-world products at Tesla and AGI research at OpenAI. All of my work combining the two so far has only been part-time, as side quests to my "real job", so I am quite excited to dive in and build something great, professionally and full-time.
It's still early days but I wanted to announce the company so that I can build publicly instead of keeping a secret that isn't. Outbound links with a bit more info in the reply!
Today we’re announcing Meta LLM Compiler, a family of models built on Meta Code Llama with additional code optimization and compiler capabilities. These models can emulate the compiler, predict optimal passes for code size, and disassemble code. They can be fine-tuned for new optimizations and compiler tasks.
@HuggingFace repo ➡️ https://t.co/9URAr9sn5E
Research paper ➡️ https://t.co/nIYvWHqm1D
LLM Compiler achieves state-of-the-art results on code size optimization and disassembly. This work shows that AI is learning to optimize code and can assist compiler experts in identifying opportunities to apply optimizations.
We’re releasing LLM Compiler 7B & 13B models under a permissive license for both research and commercial use in the hopes of making it easier for developers and researchers alike to leverage this in their work and carry forward new research in this space.
@karpathy Kind of expected. Voice to Action from what Rabbit promised. Apple silicon to power the cloud. Using data from their ecosystem to empower and personalize the results.
P.S. I was more impressed by the math notebook!
@RnaudBertrand@RichardSSutton You might’ve overthought this event. It’s nothing but formality. You can use the translator one more time.
https://t.co/LdQY7yUqZ6