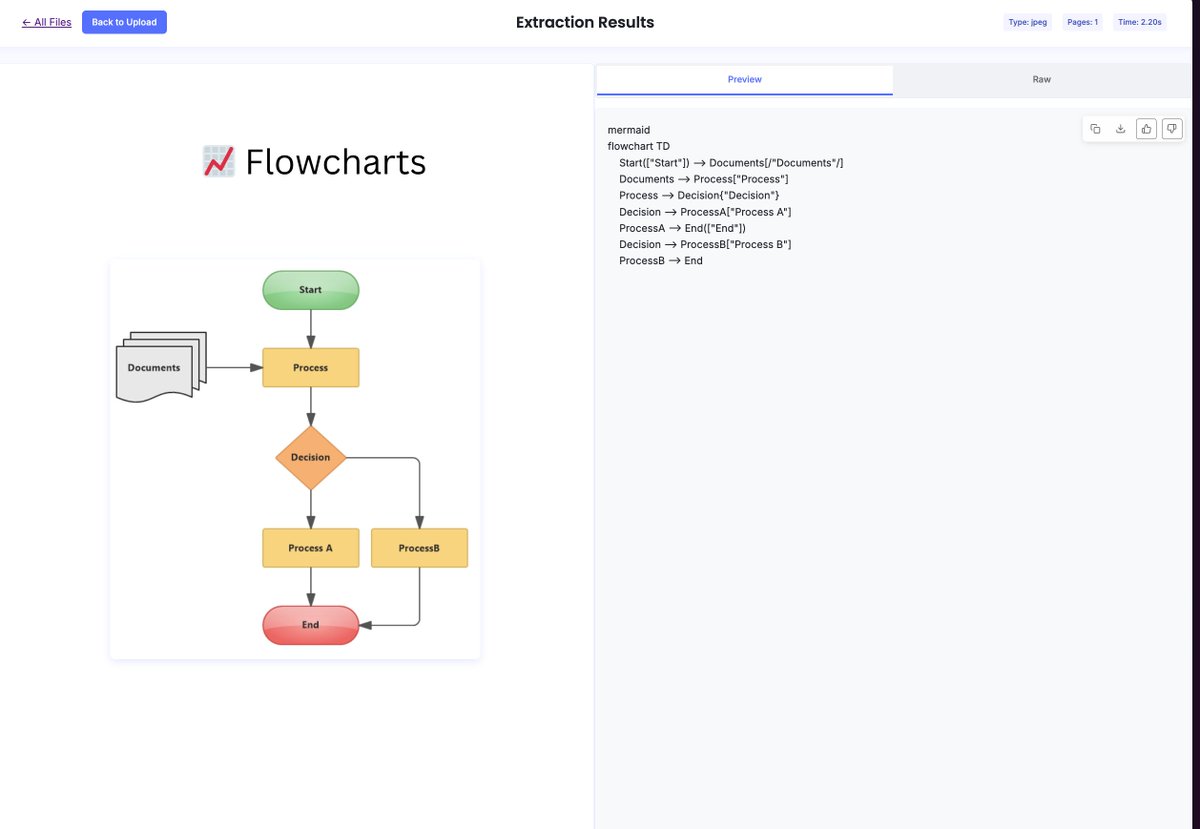
Maybe Claude code open sourced its codebase because it cannot figure out all the bugs related to high token usage and open sourcing it is more efficient. 🚀
"When a metric becomes the target, it stops being a good metric" - Goodharts Law
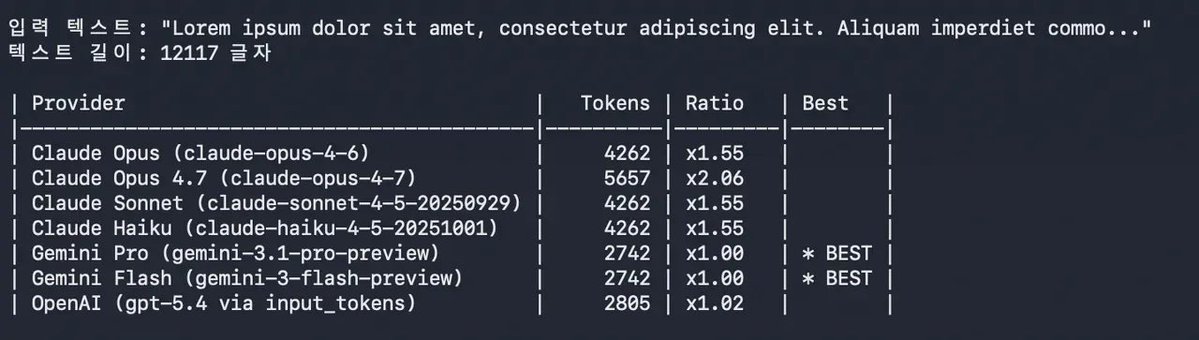
last few days GLM-OCR has been trending after it claimed 95% on OmniDocBench, which is higher than Gemini-3-pro
in reality GLM-OCR is way worse than the story these benchmarks paint, lets see how
full disclaimer: ive been working in this space for the last 7 years with @nanonets
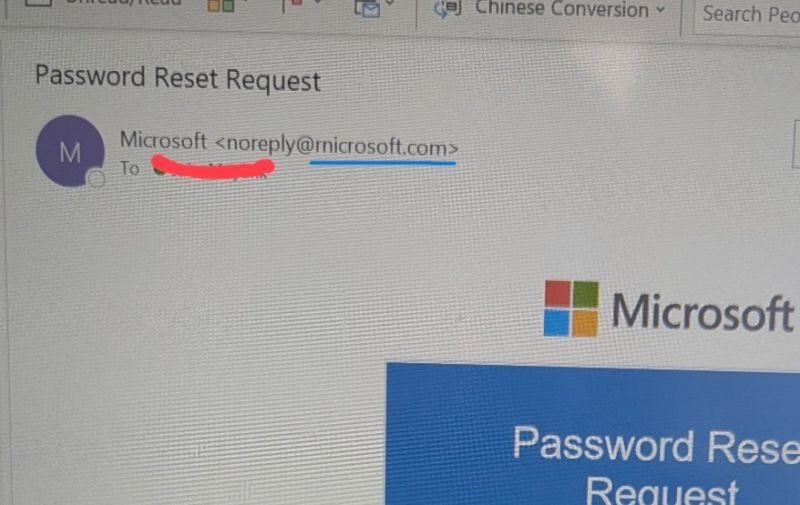
A tiny phishing trick broke 5 out of 8 popular OCR models (Deepseek-OCR, Gemini-2.5Pro, PaddleOCR, etc)
Can you spot the phish in the screenshot?
If you use OCR/Markdown pipelines in prod, check out the results in the thread.
1/n
@HKydlicek Feel free to try the newer model. We have fixed some of the issues of the last model (Nanonets-OCR-s) that people mentioned. Also, added some of the requested functionalities.
Introducing Nanonets-OCR2: a lightweight 3B VLM that transforms documents into clean, structured Markdown and is capable of VQA. We have trained the model on close to 3 million documents. It is multi-lingual and can handle handwritten documents.
Nanonets released a new version of their SoTA OCR model 🔥
Supports LaTeX, Multilingual, Complex tables and much more
Works out of the box with transformers, vllm and all major runners! 🤗
https://t.co/fgvdp4QIC9
@BramVanroy @vanstriendaniel@nanonets@huggingface We have compared against Gemini-Flash, which is generally the SOTA for document understanding tasks. https://t.co/bqZLJVGxt9 We will add more evals more time.