# The second era of AI engineering
> "The single biggest predictor of how rapidly a team makes progress building an AI agent lay in their ability to drive a disciplined process for evals (measuring the system’s performance) and error analysis (identifying the causes of errors)."
The first era of AI engineering was justifiably characterized by gluing together tools and APIs. A significant proportion of products that achieved commercial success in the 1st era were coding agents, which benefitted from tremendous rigor & evals baked into post-training process. OTOH, Many people got burned by evals in this era because they demanded that evals should be "just another one of these tools that we plug in". This did not go well.
In the second era, I believe we are going to see a resurgence of a persona like the data scientist [AI Scientist?] who is adept at looking through data to generate hypothesis, craft custom metrics, and debug stochastic systems. This will become increasingly valuable in many domains where we do not have the benefit of domain-specific post-training or dogfooding by foundation model labs (like is often the case with coding agents).
It's exciting to see Andrew Ng independently arrive at this conclusion and champion it. Really looking forward to seeing more machine learning engineers and data scientists realize how valuable they are in applied AI.
For anyone that wants to learn more about what this looks like IRL, I'll put a link to a YT video in the reply.
https://t.co/aQsW59Ylt6, combined with learning help from an LLM, is more accessible than ever. Great way to learn how AI and deep learning really work at the foundations.
Fall semester is starting, and many universities are rolling out AI engineering courses.
If you teach an AI engineering course at your university, email me at [email protected] or DM me for a free copy of our 11-chapter, 166-page course reader to share with your students and/or adapt into your curriculum.
AI engineering & evaluation are hard—but they're skills every future engineer will need!
Building LLM apps feels different, right? Their opaque nature makes predicting outputs and behavior really tough. 🤔
So how do you move beyond guesswork and actually improve your LLM-based products reliably?
90% of users never scroll past the first page of search results, and most only scan the top 3-5 entries before giving up.
If you've spent hours creating something only to have it disappear into the void, I've got a solution. Let me show you your MVP 🧵
📚 A hand-picked list of free resources for building reliable LLM applications—covering Python, deep learning, evaluation, MLOps, and prompt engineering.
Everything here is open and accessible—no paywalls, no subscriptions, just great content to dive into (even the books!).
I’ve connected with a lot of new folks recently—welcome! If you found my 5 Best Free Resources on LLM Agents useful, I think you’ll like this too. @stefkrawczyk and I originally put this list together to help people ramp up for our course, but we realized it’s valuable more broadly—so we’re sharing it.
It’s a mix of Python, deep learning, evaluation, Ops, and prompt engineering—all aimed at helping you move beyond proof-of-concept and build reliable LLM-powered applications.
Best part?
👉 Everything is open and accessible—no paywalls, no subscriptions. Just great content to dive into (even the books!). And follow these great builders!
📚 Resource List:
🐍 Python Data Science Handbook – @jakevdp
A deep dive into core Python libraries like pandas, NumPy, and scikit-learn—essential for modern data work.
📖 Fastbook – @jeremyphoward, @GuggerSylvain
A hands-on deep learning guide with PyTorch that explains not just “how,” but “why.” Perfect for expanding your LLM knowledge.
🧱 LLMs from Scratch – Sebastian Raschka, PhD
A practical guide to building LLMs from the ground up—ideal for those who want a deeper understanding of architectures and training workflows.
⚙️ MLOps vs DevOps – @vtuulos , @hugobowne
Why ML needs different workflows than traditional DevOps—critical for scaling LLM systems.
🧪 LLM Evaluation – @HamelHusain
Practical techniques for evaluating LLM outputs and closing the gap between demos and production.
🔄 AI Engineering Flywheel – @sh_reya
How to iteratively improve AI systems through logging, feedback, and evaluation.
💡 The Prompt Report – @SanderSchulhoff & others
A comprehensive guide to prompting strategies and improving LLM performance.
🚀 Generative AI Platforms – @chipro
All about scaling GenAI apps—from infrastructure to deployment.
🔧 https://t.co/FCnFHHpHRr – @eugeneyan , @BEBischof, @charles_irl, @HamelHusain, @jxnlco, and @sh_reya
Tools and case studies from practitioners actively deploying LLM-powered applications.
🛠️ Generative AI Guidebook – Ravin Kumar
A beginner-friendly roadmap for building generative AI systems.
🤖 Building Effective Agents – @ErikSchluntz , @barry_zyj, @AnthropicAI
A deep dive into building autonomous, agentic LLM workflows.
🧩 What Are Embeddings? – @vboykis
A comprehensive look at embeddings—their evolution and importance in ML.
👉 Full list with links: https://t.co/MiATGUlHFi
What else would you add to the list? Drop your favorite resources below!
Unless you're an alien, this will take a long time to get through. But this "2025 AI Engineer Reading List" from @latentspacepod is *fantastic*.
Checked out recommended papers across topics like frontier LLMs, RAG, agents, finetuning, and more.
https://t.co/gUAblfCfxS
Many are unfamiliar with TREC, so I'll share an explanation from 20+ years of experience both as an organizer and a participant. A good starting point is William Thomson (aka Lord Kelvin): "If you cannot measure it, you cannot improve it".
Many people have bouts of imposter syndrome. It not unusual—the internet makes it easy to see awesome people doing epic things everyday.
Here's some ideas on dealing with chronic imposter syndrome.👇
Imagine spending $10,000 in a single weekend on LLM testing.
That's exactly what happened to one of my clients when a junior engineer became overly enthusiastic with their evaluation suite. That moment served as a wake-up call.
The VP had been advocating for sophisticated LLM-based testing systems but was missing something crucial: sometimes the simplest solution is the best one. After my first week, we began to:
- Write tests that run in seconds, not hours
- Catch critical issues before they hit production
- Save thousands on evaluation costs
- Provide engineers with clear metrics for improvement
All of these changes significantly impacted how we build AI systems. In less than a month, we transitioned from burning cash on complex evaluations to having a lean, effective testing system that accurately predicts user satisfaction.
Some things I learned from conferences this year:
• the real world is messy: reward function(s), operationalizing the world as data, levers to act on the world, measuring outcomes, etc.
• reward functions are hard: short-term rewards != full picture, long-term rewards are delayed and hard to attribute, proxies are sensitive and hard to align, and most rewards are sparse. rewards are prob >50% of the juice
• framing the problem right makes a big difference: not everything has to be an ml problem or solution. a more flexible albeit initially worse system could be better than a specialized system that's hard to extend. for example, generative or extractive vs. ner or classification, or explore-exploit vs. supervised
• all of ml involves trade-offs: recall vs. precision, explore vs. exploit, relevance vs. diversity, quality vs. speed vs. cost. the challenge is figuring out the right balance
• consider the maximum obtainable performance your system can achieve; it may not make sense to have targets beyond that, unless you’re doing fundamental research
• evals are a differentiator: it distinguishes teams that rush out hot garbage from those seriously building products for the long term. no one regrets investing in a solid eval harness
• brandolini's law: the amount of energy needed to refute bullshit (catch and fix defects) is an order of magnitude bigger than that needed to produce it. but it is this last mile that earns and breaks customer trust
• don't forget the dimension of time: preferences, catalog availability, relevance, etc. changes over time. there's intraday dynamics and seasonality. this is one aspect of data drift. if relevant, make your models aware of time
• scale makes everything harder: while you don’t have to address it immediately, prepare for it, especially when scale is inevitable
• new bugs/issues emerge with each order of magnitude of scale: prepare for the ops load that comes with it
• for llms, cost is dependent on scale: even the most expensive llms are not that expensive for b2b usage; even the cheapest llms are not that cheap for consumer usage. similarly, scale when you need to, and not too early before
• get the fundamentals right: investing in core capabilities such as data, instrumentation, experimentation, metrics will pay dividends with each new system
• always start simple: complexity will creep in since your initial system will not cover all edge cases and you'll need to add patches (see point on order of magnitude bugs). a system that starts complex will collapse under its own weight
• not everything needs to be realtime: batch / asynchronous workflows simplify system design and reduce monetary/ops cost greatly
• design for fast detection and recovery: no system is perfect and stuff will slip through. there's an optimal balance of investing into prevention vs. recovery. monitoring, alarms, rollbacks, andon cords, etc. help a lot
• execution is the hardest thing and separates what works from what doesn’t. execution = getting from what we have now to our long-term vision
• it takes a team to build a successful product: infra, engineering, data, analysis, science, design, ux, etc. valuable are those that force-multiply
• breakthroughs takes longer than you think: start early, be patient, have persistence. related: nine women can’t birth a baby in one month
• innovation can come from anywhere; it’s not limited to researchers and labs. some of the best ideas come from engineers and non-technical folks
• to build successful products, balance thinking big with the details. having a grand vision is helpful but don’t neglect the details (see point on execution)
• your rate of iteration = rate of innovation and success. focus on experimenting fast, getting rapid feedback, updating quickly, and build the flywheel
• design products and systems with the data flywheel in mind: how will you collect user feedback that feeds into and improves your model and thus the customer experience?
• not all challenges are technical: many are coordination, culture, organizational, etc. these non-technical challenges are typically an order of magnitude harder than technical ones
• you don’t have to do it alone: wherever you are, there will be people working on similar problems, facing similar challenges, that you can reach out to. also consider the internet
• everyone is willing to help, especially if you come with data, have done your homework thoughtfully, and have an open mind
• always work backwards from the customer: what's the problem we're trying to solve, and what are the benefits? unless you're a researcher, you don't want to build stuff or do science just for the sake of it
• humans are insatiable: there will always be demand for more problems to be solved and more to do even as we automate and simplify exponentially
• production is orders of magnitude harder than demos: "there's a large class of problems that are easy to imagine and build demos for, but extremely hard to make products out of. for example, self-driving. it's easy to demo a car self-driving around a block but making it into a product takes a decade" — Andrej Karpathy
• ignore the noise and build: don’t get distracted by the volume of daily buzz and techniques; most don’t work anyway. for stuff that actually works, you may need to learn it from builders who aren't necessarily sharing on social media
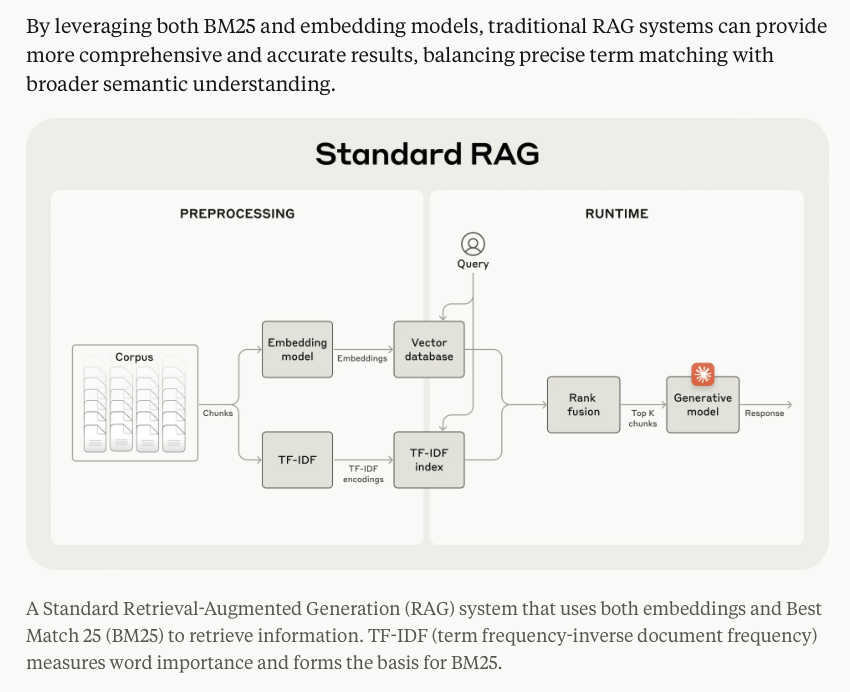
♥️ this writeup from @AnthropicAI for so many reasons:
• Reiterating bm25 + semantic retrieval is standard RAG
• Not just sharing what worked but also what didn't work
• Evals on various data (code, fiction, arXiv) + embeddings
• Breaking down gains from each step
More of such writeups please!
https://t.co/wtiSFH5bja
Time for a new ✨Information Retrieval Blogpost✨
It's about our rerankers library, and the why&how of it.
It features this updated "what model should I start with" cheatsheet, as well as an intro to what reranking is and why you should embrace it (and a lot more cool stuff!)
Published a report on improving retrievers using @lancedb Hybrid search and Reranking.
This explores techniques to optimize retrieval performance 𝘄𝗶𝘁𝗵𝗼𝘂𝘁 𝗿𝗲𝗾𝘂𝗶𝗿𝗶𝗻𝗴 𝗮 𝗰𝗼𝗺𝗽𝗹𝗲𝘁𝗲 𝗱𝗮𝘁𝗮𝘀𝗲𝘁 𝗿𝗲-𝗶𝗻𝗴𝗲𝘀𝘁𝗶𝗼𝗻
https://t.co/1QHLMcEEEf
We just released two new resources for learning prompt engineering.
1. An interactive intro to prompting tutorial for people just getting started with Claude
2. A real-world prompting course for developers building on the Anthropic API
Here's what they cover:
My tinkering with SearchArray+BEIR with many humbling lessons about how real search engine works compared to a tool that just computes BM25
Be grateful for your search engine maintainers, as this stuff is hard :)
https://t.co/hZCaSfSBfv