Can a VLM see without a vision encoder?
We trained one for $100, inspired by Gemma 4 12B.
Latency on an M3 Pro MacBook:
112 ms -> 1.1 ms for the image path
30% lower end-to-end image+LLM
The architecture is just:
patchify the image -> linear projection with pos embeddings -> LLM
Writeup:
https://t.co/yt0IKzsF7O
The Mixture of Experts (MoE) inside 🤗 Transformers is out now!
This is going to be a long tweet, so if you just want to jump to the blog, the link is in the thread.
We already had a great blog post on MoEs (which has more than 1k upvotes 😯 at the time of writing). The reason we wanted to build another blog post altogether was just noticing how far we have come in the realm.
This blog post is not meant to be another "What is MoEs and how to implement them". Rather talk about how the transformers team at @huggingface made MoEs the "first class citizen" of the library and the Hub.
The transformers library and the entire ecosystem was built around dense architectures, but now with the rapid growth of MoEs, it was inevitible to build around MoEs and not consider them as "just another model addition".
In the post we talk about better model loading, expert backend, expert parallelism, and also @UnslothAI and out collaboration on training MoEs faster!
In the process of building the blog post, I also understood how beautiful the ideas are, and ended up making my first YouTube video on the routing algorithm alone.
I am very proud of this project and I think it shows in some paragraphs of the blog post. I am also very thankful to all the people who helped me in the project, I am really happy to be in the team that helps me flourish! Glad to be alive.
PS: I owe you all an apology for delaying the release. I hope I (and the team) could make it worth the wait.
New art project.
Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.
https://t.co/HmiRrQugnP
Imagine writing a pure C, dependency free, fast enough Flux 2 Klein 4B inference library. In a weekend. Thanks to AI writing the code, and the human steering it towards the right direction.
https://t.co/VDDsxrUkD3
𝗦𝗼𝘂𝗻𝗱 𝗢𝗻 🎙️
Last month we took our annual offsite and yes, we had an amazing time.
Menorca treated us with great food, stunning sunsets, long afternoons at the beach, and plenty of conversations that sparked new ideas. ⚡️
And by conversations, we mean exciting upcoming projects. 💯
We’ve been working on a few things behind the scenes, including something that might involve Fermat and a podcast?
Stay tuned, more is coming soon. 🏖️ 🎙️
Fashion has always been about vision. Now, it can keep up with it. We're building a space where creativity doesn’t slow down: designers can try, change, and reimagine instantly. From a single sketch to an entire campaign, Fermat makes the process feel as fluid as the imagination behind it 🌠
Ever wondered how simple it is to create with Fermat? Turn ideas into fully generated garments in just a few clicks. Feel the freedom of experimenting with fabrics, colors, and silhouettes.
⚡️ Ready to power your next design? Here’s a quick demo:
https://t.co/HvIiNzaFIW
You can now train FLUX Kontext loras on Replicate.
https://t.co/dD81w8hx9K
- A 1,000 step training takes about 4 minutes
- Train with image pairs, a start and end image
- Write a short prompt instruction that takes you from the start to the end
- Use about 10 image pairs
Hola, tenim una habitació lliure a Barcelona a la Rambla del Poblenou, a partir de l'agost. El pis està a 10 min de Glòries i 2 de la L4 Poblenou. Som 2 noies i un noi, i busquem una companya de pis amb qui tenir una bona convivència. Interessades escriviu DM. Gràcieees!!
Hola, tenim una habitació lliure a Barcelona a la Rambla del Poblenou, a partir de l'agost. El pis està a 10 min de Glòries i 2 de la L4 Poblenou. Som 2 noies i un noi, i busquem una companya de pis amb qui tenir una bona convivència. Interessades escriviu DM a mi o a @marcagve
We @fermat_app are hiring for a Barcelona or London-based account manager/customer success role for our Fashion & Luxury Vertical.
We are growing 30% MoM and serving some of the best brands in the world. If you want to join an AI startup making a very real impact in productivity, send me a DM or comment below.
If it's a fit, you can start working at Fermat next week.
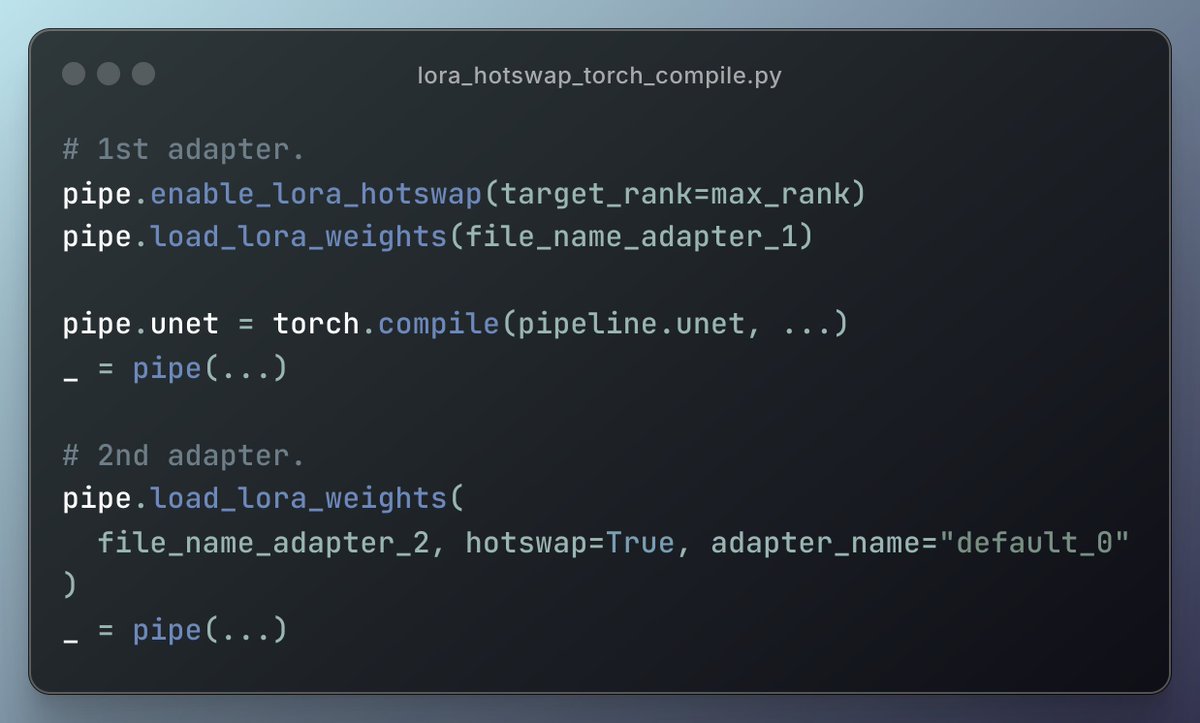
Want to benefit from `torch.compile()` while hotswapping LoRA adapters into your diffusion models?
This is now possible, thanks to the OG @BenjaminBossan's incredible hard work!
Follow the comments for a tutorial, code, etc.
HiDream Text Encoder Dependency test. HiDream has 4 text encoders. Having more than 1 will always lead to one text encoder carrying all the weight so I tested dropping them all but one at a time. It is 100% dependent on the llama 8B encoder. The rest can be removed.
Today we had an INCREDIBLE Gen AI kick-off at the Adidas HQ. Super happy to be able to work with such a legendary brand and proud of the Fermat team.
More than +150 designers at Adidas had the chance to get started with Fermat. They will be using our Fashion AI toolbox to speed up their ideation, time to factory & look creation processes.
(We also got to see Leo Messi's foot. Look at the next post)