Zyphra is sharing our first work in continual learning where we study: Can LLMs learn forever from new data?
Many see continual learning as a path to AGI through recursive self-improvement (RSI).
The first obstacle is plasticity loss. We derive a scaling law for its onset 🧵
𝐍𝐨 𝐆𝐏𝐔? 𝐍𝐨 𝐩𝐫𝐨𝐛𝐥𝐞𝐦.
We just published a starter guide for developing vLLM + LMCache on a MacBook.
LMCache's multi-platform design decouples the GPU from most core data paths, so a single laptop is enough to clone, build, run unit tests, and verify a real cache hit on CPU. The guide walks through the environment setup in ~10 minutes and points to four concrete areas where you can start contributing.
If not having a GPU was your only blocker, it is not anymore.
Read the guide and join us in building the KV cache layer for faster LLM inference: https://t.co/l22JWaH22F
#LMCache #vLLM #LLM #AIInfrastructure #OpenSource
We taught a brand-new mini-series this year at @SCSatCMU on Modern GPU Programming for ML Systems, as part of the ML Systems course, touching on fun questions like what data layout swizzling is, how to use 3D TMA, and state-of-the-art Blackwell programming. We released a curated online book based on the materials: https://t.co/5ZJg2lySNO check it out
Today, we filed a lawsuit to permanently dismantle a group of organized cybercriminals accused of using AI tools — including Gemini — to scam Americans via fake text campaigns. Here’s what to know:
◾Our suit targets core software developers in a cybercrime operation known as the “Outside Enterprise.” The group has allegedly weaponized AI to quickly generate highly convincing fake government and brand websites intended to steal victims’ credit card numbers and personal information.
◾The group used AI and different Google products — including our trademarks and logos — as part of these phishing campaigns.
◾The scale of the operation is massive: More than 100,000 victims have been scammed, with losses estimated in the millions.
Now that I have your attention, any suggestions on our ~200 line CUDA implementation of Muon would be greatly appreciated https://t.co/K4Ub7JT93K. In the 5.0 branch on the same file, I played with a small change to preserve LR across model sizes, but there have not been any major improvements otherwise.
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
One of my personal favorite features announced at WWDC will I suspect be a sleeper hit: container machines, allowing your Mac to run a lightweight, persistent Linux environment with your home directory and repos automatically mounted: https://t.co/dOBdfOOVxC
We've made a breakthrough in self-evolving AI scientists moving from "search" to "principled discovery": Scientific discovery requires that the search space itself changes, and an AI scientist must perceive this shift without intervention. We built an AI that achieves this for the first time with the ability to discover the scientific vocabulary it reasons in. Evidence, tools, artifacts, verifiers, failures & claims become typed provenance. We show three distinct modalities: 1) retrieval, adding known objects; 2) search, exploring a fixed schema; and critically: 3) discovery, a verified regime transition.
We solve the open-endedness evaluation problem by lifting agentic workflows into a typed copresheaf and proving, via a Kan obstruction, that true discovery is not unbounded generation but a verifiable schema expansion: old evidence is transported by Left Kan extension, and genuine novelty is mathematically quantified by the pointwise residual beyond the transported image - separating discovery from mere search and making novelty objective and measurable rather than a subjective judgment or benchmark delta.
Our AI scientist is built in a way that does not pre-conceive the approach it chooses; instead, we endow the system with formal power to adapt, evolve, and reason from first principles. Case studies include:
1⃣Builder/Breaker model that discovers mode-conditioned compliance in proteins;
2⃣CategoryScienceClaw that finds anisotropic fiber-network stiffness rules.
Great work in collaboration with my graduate student @fwang108_@MITdeptofBE
F.Y. Wang & M.J. Buehler, Self-Revising Discovery Systems for Science: A Categorical Framework for Agentic Artificial Intelligence, arXiv:2606.01444, 2026
Today, we’re excited to introduce Miso One, the most emotive voice model in the world.
Miso One is an 8-billion-parameter text-to-speech model for highly expressive speech generation. It emotes like a human and responds faster than a human, with just 110 milliseconds of latency.
We’ve open-sourced the model weights, with API access coming soon.
Hear how Miso One sounds in the thread below.
Our paper was accepted as a #ICML2026 Spotlight!
Reasoning in LLMs has improved largely by chaining local steps. But is that the whole story?
Humans occasionally make inferential "leaps" across domains, a faculty known as analogy.
We design a synthetic task to show how small Transformers acquire analogical reasoning, and find that the same signatures appear in pretrained LLMs.
arxiv: https://t.co/1WCizIKWly
code: https://t.co/82kOKCtJo7
We want to help scientists discover their next breakthrough with AI.
Gemini for Science is our new suite of experimental tools to help them explore more hypotheses, validate work at scale, unpack literature with ease, and more 🧵
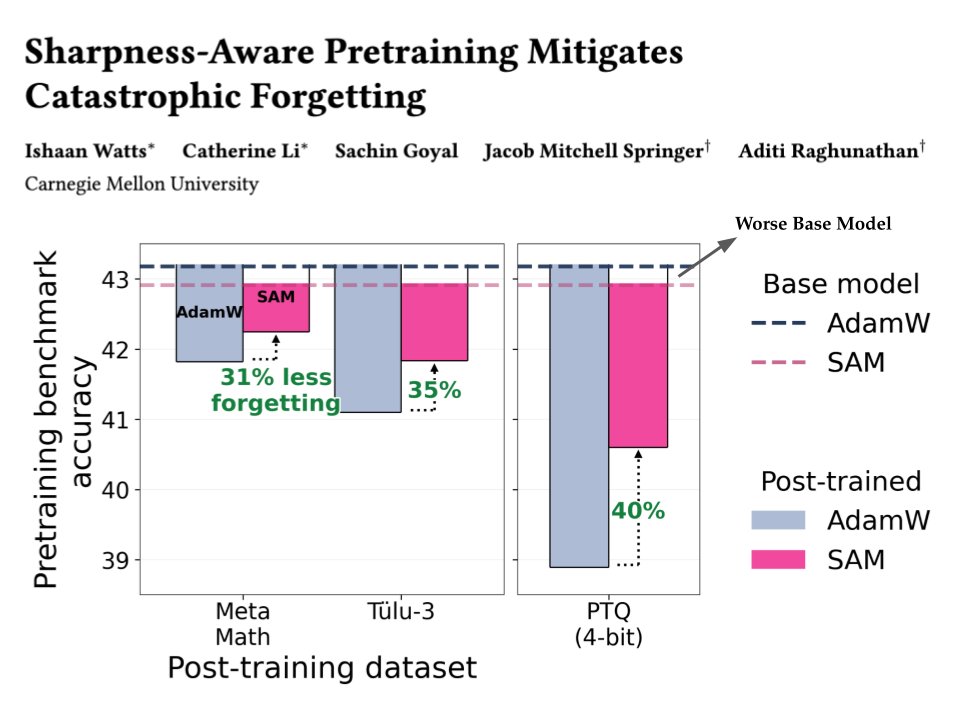
Spending billions to train the "best" base model? You might be optimizing the wrong thing! 🎯
We show that controlling sharpness during mid-training leads to over 35% less forgetting after fine-tuning / quantization... even when the base model itself gets worse.
🧵 Takeaways for pretraining:
- Use SAM (Sharpness-Aware-Minimization) in the final steps (~10%)
- Try much higher learning rates (yes, even ~10× larger)
1/9
Looped Transformer and MoE are a natural combination (https://t.co/ToBNezLUTb, https://t.co/CLwbrhaage). And this would lead to more sparsity (https://t.co/evpLzdVdzg).
The authors introduce Kaon, a Muon variant with random noise replacing SVs. Kaon matches Muon, suggesting Muon’s gains don’t depend from a geometry. They also show Muon has a stable opt. step size, yielding a more effective learning rate during training.
🔗https://t.co/jqwp3534c2
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
The human brain🧠 is incredibly efficient because it only activates the specific neurons needed for a thought. Modern LLMs naturally try to do this too (> 95% of neurons in feedforward layers stay silent for any given word), but our hardware punishes them for it.
One of the most frustrating paradoxes in deep learning: making a model do less math often makes it run slower. Why? Because unstructured sparsity introduces irregular memory access, and GPUs are built for predictable, dense blocks of math.
We teamed up with @NVIDIA to try to fix this hardware mismatch. Instead of forcing the GPU to adapt to the sparsity, we built a "Hybrid" format that reshapes the sparsity to fit the GPU. Our sparsity format (TwELL) dynamically routes the 99% of highly sparse tokens through a fast path, and uses a dense backup matrix as a safety valve for the rare, heavy tokens.
Through TwELL and a new set of custom CUDA kernels for both LLM inference and training, we translated theoretical sparsity into actual wall-clock speedups: >20% faster training and inference on H100 GPUs, while also cutting energy consumption and memory requirements.
Paper: https://t.co/rqIY9SYBDe
Blog: https://t.co/oRjNbpJKha
Code: https://t.co/FAFaJwpxAJ
⚡️
(4/5) One thing we’ve built is a “kittens” virtual machine that takes over the whole GPU and allows new kinds of co-optimization. We can go past the traditional sequential kernel model – for example, fusing entire training runs into a single kernel and even weirder stuff.
1/ For nearly 350 years, science has communicated itself through one object: the paper. A linear narrative, frozen as a PDF, written for a human reader. We've come to treat that format as the medium of science itself.
It doesn't have to be. It's a historical artifact. 🧵
seems like architectural research can be done ridiculously cheaply by measuring the time to overfit into 1 sample!
RMSnorm (https://t.co/zyfZ4aFmdh) vs softclamp (https://t.co/2INxdcAcDs) (4000 steps fit)