@andrewwhite01 For Wikipedia itself over a decade ago I tried to get a page for every bacterial species, but anti-bot politics meant only etymology and very limited scraped data was okay. Albeit not protein the info is neatly documented in Bergey's Manual and in journals
OPIGlets are out in force at #AIChem24, organised by our very own @gmm DPhil students @LucyVost, @arun_raja007 and @isakvals are presenting posters, and Yael is giving a talk about her recent work MolSnapper on Wednesday! Please come and chat to them!
DPhil student Steph Wills has led efforts to expand catalogue searching via bioisosteric fragment merges, using a graph database approach.
Preprint now available on the bioRxiv: https://t.co/Wptp6l6N0S
DPhil student @oliverturnbull1 has built pIg-Gen, a language model for paired-chain antibody generation. It creates diverse, natural-like distributions of antibodies w/ similar biophysical properties to therapeutics.
bioRxiv: https://t.co/OX8dSnEtC6
Code: https://t.co/Orut8WMbCZ
OPIG DPhil student @GemmaLGordon led work to build and analyse "PLAbDab-nano: a database of camelid and shark nanobodies from patents and the literature". Just released on bioRxiv and available as an OPIG webapp:
Preprint: https://t.co/OzbefvcyKB
Webapp: https://t.co/5yvBJ4IRyn
Generative models for molecular optimization & protein design often rely on data-driven guidance functions for conditional sample generation. Our new #ICML2024 paper presents a simple but effective approach to improve their performance in OOD settings.
https://t.co/Q1iLAFjDjY
@SKleinfelter1 It's ironic that PyRosetta is so versatile yet requires _endless_ patience in its reverse engineering... In my post I was hoping to address covalent ligands and NNCAs, but I honestly had no willpower left to face that wall... 🧗♂️☠️
RFdiffusion is sometimes quirky, often infuriating, but most often fun. As a result, I wrote a long blogpost on how to manipulate and score RFdiffusion models in PyRosetta 📚🛠️https://t.co/fSzti5PyLc
It took a while but it's here: the Fragmenstein preprint!
https://t.co/kysZwziyZF
A big thank-you to everyone who helped in its creation, especially user feedback!
Before the break I presented at the AViDD forum (https://t.co/Nnpzg6YqqR) for which I am very grateful for, but totally forgot to share the link: https://t.co/YH1Hdy8CJZ
(Title: Advancing Fragment-Based Drug Discovery in the @asap_discovery consortium with Fragmenstein)
The incredible @asap_discovery team members working with @XChem_DLS collected 14,631 X-ray datasets and deposited 6.7% of all X-ray structures in the PDB for ASAP in 2023 to advance structure-based antiviral discovery--with hundreds more pending release. 🚀
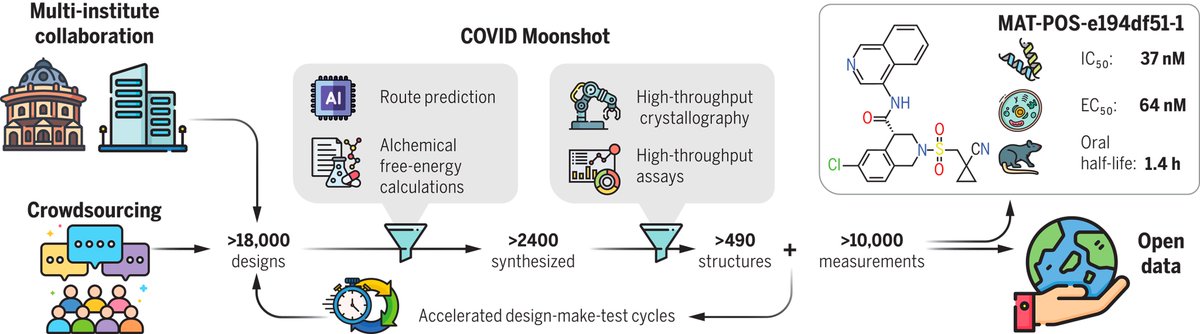
Here's what I spent the last few years working on. Incredibly proud of the work done by all of the amazing scientists and volunteers who contributed, and optimistic for the future of open science drug discovery for globally equitable and affordable access:
https://t.co/uATa6ScVo4
The @covid_moonshot paper is out in Science: but can it help you as a compchem algo testset? Yes!
All steps (frag to lead) crystallised & assayed, incl. negatives. Diverse methods, 4 series. Don't take my word, have a gander yourself: https://t.co/hfIVdrcCkx
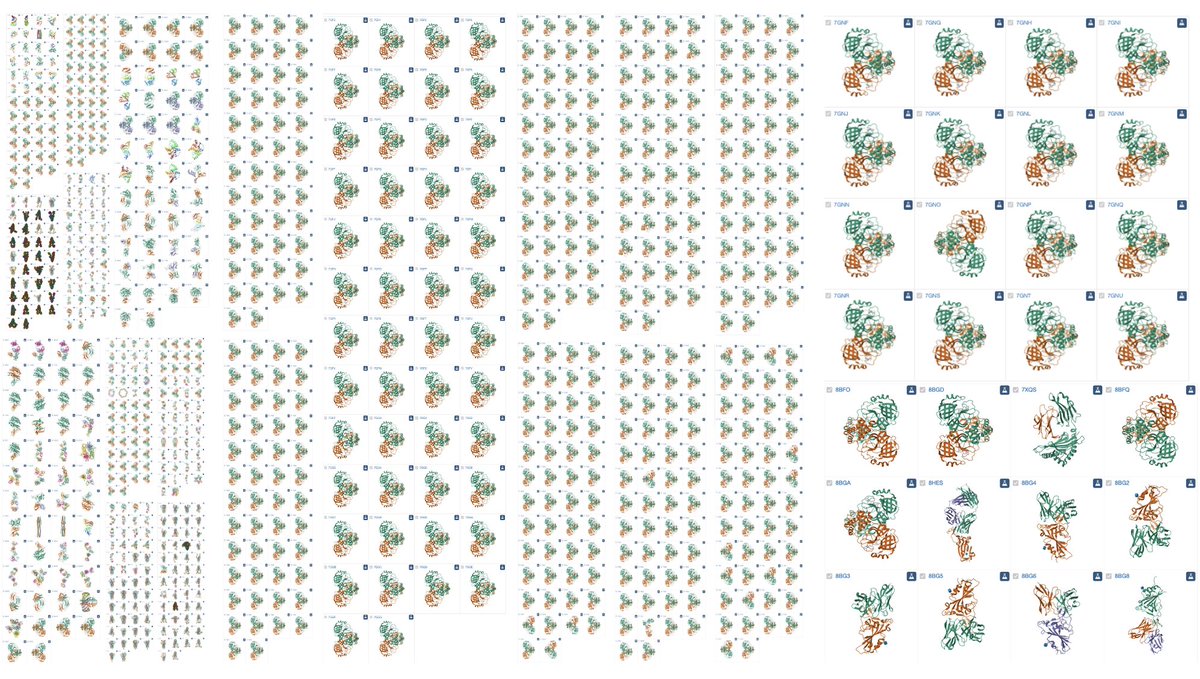
PDB released 478 SARS-CoV-2 structures this week, including 466 mpros with inhibitors from the COVID Moonshot project. 966 have been released this year (shown), for 3826 total since the first CV19 structure was released in Feb 2020.
Explore them all at https://t.co/q3UBxbZoaF
@RolandDunbrack Chrome has an open source plugin (Authenticator extension) that does the 2FA authentication (it partially defeats that security measures as then thieves only need to steal a device where one is logged into Chrome and an index finger to unlock the device)