Today, I'm excited to share some work our team has been doing over the last few years at @insitro. It's a new tool for data science called redun. We describe the motivation and contributions in this post. https://t.co/EfW9a9mY5O
We're excited to announce the open sourcing of redun, an expressive, efficient, and easy-to-use workflow framework designed to deal with complex, rapidly evolving scientific workflows spanning multiple data types. Read more here: https://t.co/kwuMOrpI01
I was talking with an old friend at dinner last night, he described gpt fatigue
I'd examined the whole psychosis thing, but fatigue is different, and this one rings with me. I've been through cycles of this; I'm probably just emerging from my third epoch of gpt fatigue right now
it's very bittersweet. the cognitive overhead of context switching across the slop troughs is not as fun as the in-the-zone coding rhythm I enjoyed for the first twelve years of my career
I drew the connection to the Reactor Harness I'd been working on and he lit up (yes, this is a launch post, read on). I told him the basic idea:
In the same way that React (js) keeps the DOM up to date by rendering declared components efficiently based on upstream events...
the Reactor Harness keeps an ideal world-model up to date by rendering declared facets of the world-model efficiently based on upstream events.
This world-model can be anything--formally it's a faceted content addressable blob. In practice, it can be a file, a directory, a sqlite table, etc.
If you've followed OpenProse since the beginning, you'll guess that the render function is not deterministic byte code, but instead is declarative markdown instructions fulfilled by an agent session.
I'm releasing the harness here in beta today. It ships as an SDK so you can plug it into your own projects. We've built an experimental CLI w/ a lightweight server and a devtools package alongside it. Please give it a boost with a Github Star here, then return to read more:
https://t.co/s1S68165qg
The Reactor Harness is built to run OpenProse, and its design was uniquely informed by the tenets behind OpenProse, such that you can declare your ideal world-model using familiar structured markdown, and you can optionally write imperative fulfillment plans in our original ProseScript.
One way of thinking about the Reactor is as a DAG of agent sessions. Every node in the DAG is an agent session tasked with keeping facets of the world model up to date. These are memoized, such that downstream dependent sessions only get re-run when their upstream counterparts change.
Over the coming days, I'll be writing more about the harness, how we've been using it, and where I hope we can take this. We are in the process of running benchmarks on it. The goal is that the SDK API itself remains relatively stable while we improve the agent session fulfillment cost, speed, and intelligence under the hood.
How did we get here?
Today I keep a large share of our company's operations in a directory: tenets, specs, code, analytics, our burn model, our sales lead enrichment CRM.
And I find myself having to manually "fast-forward" these models, dropping into context to proactively tell Claude Code to update a spec, add someone to the CRM, or update the financial model based on real-world events that have changed our plans.
I'd written many OpenProse scripts to accomplish these things, but I found I wanted this all to run reactively, as an ongoing time-invariant responsibility, rather than proactively as a tool that I continuously return to. Our first attempt at solving this was putting our OpenProse programs on a cron. The problem with that was that it became very expensive very fast.
As I started trying to design the OpenProse to work under these constraints, I found myself introducing concepts like memoization to different facets of the maintained state. From there, I decided not reinvent the wheel and to graft the patterns from React more explicitly. It's an analogy, and the analogy breaks down in some places. But it's a reasonable starting point that a lot of people are familiar with.
We built the first version in April internally on our hosted service for one of our customers' needs, but I decided that the core of this is interesting enough that it deserves to be in the public sphere, so we spent the intervening six weeks ripping it out and redesigning it as an SDK so people could plug it into their own stacks.
I can't emphasize enough how there's nothing new here, we're just applying classical engineering paradigms to our brave new world. We're finding that despite our topsy-turvy reality, the wisdom of the ancients holds fast.
The Reactor harness is young, should be used with caution, and has some way to go before it reaches it's ideal form. My ask is that you try it, wire it up to something useful, love it or hate it, and send me honest feedback about your experience. We're always listening and improving.
I have a particularly exciting end goal in mind: because the Reactor DAG is itself a world-model, downstream from events in the real world (say, learned event source/frequency/distribution), you could use Reactor itself to implement dynamic Reactor DAGs. This sets us on the path to a true RLM paradigm. I'm most excited about this because I hypothesize that it will yield a simple, elegant property of the Reactor:
Inference cost for maintaining a world-model scales with surprise, rather than wall-clock time.
It's not there yet, but my expectation is that this is achievable and that it's just a matter of walking up the ladder to get there. In my experience when you make something self-referential too early it can collapse back in on itself, so we're going to step our way there incrementally.
When we do get there, my hope is that the meta Reactor DAG can continuously self-calibrate on event source/frequency/distribution to optimize for efficient fulfillment Reactor DAGs, and where the cost of keeping the world-model up to date approaches only the surprise of upstream events in the real world.
At dinner last night, a recurring topic was this love-hate relationship we'd developed with the models. I've been building harnesses for these burgeoning minds since my GPT-2 finetune in 2020. In many ways I'm having as much fun as I've ever had with technology. And yet I've come to loathe their impacts in many other regards.
In the end, I guess the real goal is that the Reactor Harness lets me unburden the cognitive load at the root of my gpt fatigue, and frees me up for the more interesting forms of gpt psychosis :D
thanks for reading and following along, star the repo here and give it a try:
https://t.co/s1S68165qg
Workflows as a *data structure* are underrated.
You can annotate, analyze, visualize, generate UI, diff, simulate, etc. They unlock tooling that code-shaped workflows make hard.
`await step(...)` is nice for authoring workflows, but not always the best way to represent them.
I really can't recommend "Permutation City" by @gregeganSF strongly enough if you want to say anything intelligent about the possibility of LLM consciousness. Also chuck Searle and Chalmers in the trash.
Claude code's new dynamic workflows update is absurd.
Make sure you understand what its doing here. This isn't simply a long running mode like /goal, or a fancy subagent verifier process.
This is Claude vibecoding an entire brand new subagent fleet harness on demand
RLM on agent harnesses. Thats what "dynamic workflow" means.
This is basically a new scaling law dimension.
Base Model Compute x Inference time Thinking Compute x Inference time generated Harness Compute
HUGE step forward on the path of AI
are you paying attention yet?
Excited to share our most powerful new Claude Code feature: dynamic workflows!
Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.
Tragically I am continuing to find that the most effective guardrail against slop is extremely talented engineers doing very thoughtful, human code review
yes yes a 1000 times yes
after the, er, recent drama, I went into a rabbit hole exploring the space, and it's like my brain's been reprogrammed
lemme put it this way: there's nothing _fundamental_ about filesystems. or terminal commands. or _even your favourite programming language_. but there _is_ something fundamental about storage. or lambda calculus. the future of computing looks more like math+symbolic execution than unix+whatever's in the training set
(and it would be very bad for humanity if this wasn't true!)
(separately: theo's so far ahead of other js youtubers. always pleasantly surprised at the depth he goes to.)
Humans 👏 are 👏 shipping 👏 slop.
My take on why and some rules to stop the slop:
macOS is trash, Cursor is unusable, Claude Code is often broken, Notion is sliding, the Codex Mac app can’t even scroll… so here’s my diagnosis and three three rules to stop the slop:
I see a lot of takes that go like this:
1. AI-written code is slop.
2. So products made with AI-written code are slop.
This is fundamentally wrong. It's a human problem accelerated by coding agents, not caused by it.
Great software is the manifestation of a vision, typically of one person or, at most, a small group of people. Eventually, that vision is lost to external pressures and things devolve—but this is a failure of leadership, not technology. In the past, the “time and money” cost for new features served as a convenient rate limiter that forced prioritization, but the cost has plummeted, and vision and leadership are more important than ever.
This “slop” is not a new phenomenon. Devs have shipped slop for way longer than AI has been around. In fact, virtually all software has slowly tended toward it. Software eventually gets “bloated" enough some young upstart comes along with a “simple” and “focused” alternative, only to eventually find themselves becoming the bloatware.
AI has not changed this lack of leadership; it’s just greatly accelerated the cycle.
A lot of poor leaders are leading poorly.
In an effort to not be one of these, here are my three rules:
1. Never delegate the vision. The worst form of slop is unanchored. Every time you open your app, everything has moved around. Features are being shipped for the sake of shipping, not for the sake of achieving a vision. This is why I no longer use Cursor; it is clearly unanchored.
2. Fight for quality. Use your own product and be the arbiter of quality—not the AI, not even your customers. Does this feature get you closer to the vision? If the answer isn’t clearly “yes,” don’t ship it. Don’t have any parallel objectives for the software. If you had to hand-code this, would it still be worth doing?
3. Never ship bugs. If software is so cheap now, why do we still have bugs? Shouldn’t they be cheap to fix? Don’t ship bugs. That’s harder than it seems. How do you know there aren’t bugs? How do you know you aren’t introducing new bugs? How do you get feedback when those bugs arise? Spend more time on these problems and less on features no one cares about.
That’s it. Happy building.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
insitro is proud to deepen our work in ALS with the expansion of our strategic collaboration with @bmsnews and the nomination of two additional therapeutic targets discovered through insitro’s AI-driven Virtual Human™ platform.
Read our press release: https://t.co/BoXfk7SUKZ
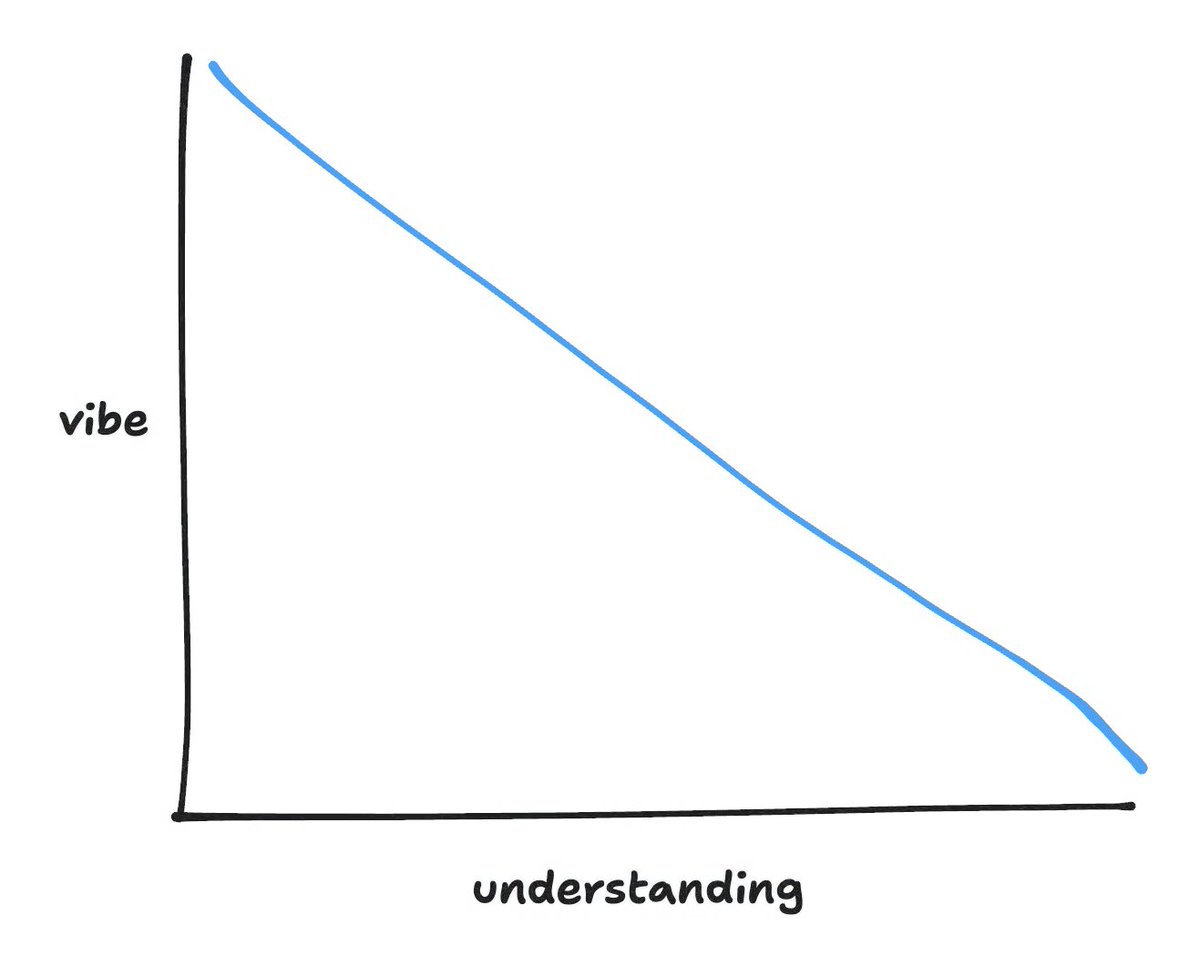
i admit defeat on "legacy code"
a year ago i tweeted this graph trying to join @simonw in the fight to protect @karpathy's original definition of vibe coding ("forget that the code even exists")
however a year later i find even myself reaching for "vibe coding" to describe any kind of coding with ai – regardless of the amount of understanding and attention i pay to the underlying code
in other words, i'm constantly vibe coding, but i'm using ai to write *better* code that i understand *more*, not less than if i didn't use ai
so i think we should admit semantic defeat in much the same way that @conal had to for "functional reactive programming (frp)" when it got popularized in a way that totally missed his original point, but instead spread a new concept that had more legs. i think the same happened to @NotAlanKay with object-oriented programming. semantic diffusion is hard (impossible?) to fight
credit to @Steve_Yegge for being right and early on calling this one!
but i see this merely as losing the battle in order to win the more important war over the hearts and minds on the importance of understanding of code in the age of ai!
we have to hold the line against slop and the atrophying of the human brain – for humanity!
For the past few years, I've wondered to myself:
What is the role of statisticians at this moment of AI development? 🤔
One of the most important functions of statistics as a discipline has been to educate the next generation of statisticians (data analysts, data scientists, etc.). What should statisticians being doing as AI models hoover up every statistical analysis ever written and posted on the internet? Who's teaching the machines? Do the models need any help?
This study below is one piece of evidence of that the models need some help. Who's going to teach the machines to reliably think like a statistician? 🤔
Obviously, this is not a typical statistical problem, and requires a lot of expertise beyond the statistical toolkit. Regardless, I think statisticians have a key role to play, and I urge more statisticians to step up to the challenge.
Think of this: AI models may be the most important students we ever teach.
Short musings on "cognitive debt" - I'm seeing this in my own work, where excessive unreviewed AI-generated code leads me to lose a firm mental model of what I've built, which then makes it harder to confidently make future decisions https://t.co/KUqQXDVNiS
If you like vibe coding you should also like typed pure functional programming. Any other position is inconsistent.
Pure functional programming is the only sort of programming which permits unrestricted denotational reasoning. Denotational reasoning means the scope necessary for the LLM to perform its task is finite (and in principle knowable, as long as you have types). Even more important it also means that you (and the type checker) can review the LLM output and be confident in the lack of accidental coupling.
Denotational reasoning enables reliable top-down reasoning at arbitrary scale. You can be certain that high-level reasoning, albeit incomplete, is absolutely correct, you don't need to attempt low-level reasoning if you do not care about low-level details.
However, it seems to me that vibe coding enthusiasts do not care a bit about pure functional programming, or about software engineering in general. In fact I see an inverse correlation between people who care about scalable and correct engineering and vibe coding enthusiasts.
On DeepWiki and increasing malleability of software.
This starts as partially a post on appreciation to DeepWiki, which I routinely find very useful and I think more people would find useful to know about. I went through a few iterations of use:
Their first feature was that it auto-builds wiki pages for github repos (e.g. nanochat here) with quick Q&A:
https://t.co/DQHXagUwK0
Just swap "github" to "deepwiki" in the URL for any repo and you can instantly Q&A against it. For example, yesterday I was curious about "how does torchao implement fp8 training?". I find that in *many* cases, library docs can be spotty and outdated and bad, but directly asking questions to the code via DeepWiki works very well. The code is the source of truth and LLMs are increasingly able to understand it.
But then I realized that in many cases it's even a lot more powerful not being the direct (human) consumer of this information/functionality, but giving your agent access to DeepWiki via MCP. So e.g. yesterday I faced some annoyances with using torchao library for fp8 training and I had the suspicion that the whole thing really shouldn't be that complicated (wait shouldn't this be a Function like Linear except with a few extra casts and 3 calls to torch._scaled_mm?) so I tried:
"Use DeepWiki MCP and Github CLI to look at how torchao implements fp8 training. Is it possible to 'rip out' the functionality? Implement nanochat/fp8.py that has identical API but is fully self-contained"
Claude went off for 5 minutes and came back with 150 lines of clean code that worked out of the box, with tests proving equivalent results, which allowed me to delete torchao as repo dependency, and for some reason I still don't fully understand (I think it has to do with internals of torch compile) - this simple version runs 3% faster. The agent also found a lot of tiny implementation details that actually do matter, that I may have naively missed otherwise and that would have been very hard for maintainers to keep docs about. Tricks around numerics, dtypes, autocast, meta device, torch compile interactions so I learned a lot from the process too. So this is now the default fp8 training implementation for nanochat
https://t.co/3i5cv6grWm
Anyway TLDR I find this combo of DeepWiki MCP + GitHub CLI is quite powerful to "rip out" any specific functionality from any github repo and target it for the very specific use case that you have in mind, and it actually kind of works now in some cases. Maybe you don't download, configure and take dependency on a giant monolithic library, maybe you point your agent at it and rip out the exact part you need. Maybe this informs how we write software more generally to actively encourage this workflow - e.g. building more "bacterial code", code that is less tangled, more self-contained, more dependency-free, more stateless, much easier to rip out from the repo (https://t.co/iKJUoHiIpl)
There's obvious downsides and risks to this, but it is fundamentally a new option that was not possible or economical before (it would have cost too much time) but now with agents, it is. Software might become a lot more fluid and malleable. "Libraries are over, LLMs are the new compiler" :). And does your project really need its 100MB of dependencies?
Heuristics for lab robotics, and where its future may go
(8.4k words, 38 minutes reading time)
https://t.co/tZe1sEnCI8
this is the longest article i have ever written. in it, i discuss the three ideologies of lab robotics progress, why they may all converge on the same business model, whether any of it will be actually helpful for the problems that plague drug discovery the most, and more
this article involved discussions with sixteen people over the course of three weeks, and i am very grateful to them for answering the many questions i had about a field that i had long considered alien
finally: this is a complicated field that is really still being birthed, so please let me know if i got anything wrong
Fuck it, a bit early but here goes:
Monty: a new python implementation, from scratch, in rust, for LLMs to run code without host access.
Startup time measured in single digit microseconds, not seconds.
@mitsuhiko here's another sandbox/not-sandbox to be snarky about 😜
Thanks @threepointone@dsp_ (inadvertently) for the idea.
https://t.co/UuCYneMQ9j