A Meat-Flavour Entrepreneur, Creative Technologist & UI+UX+Software Engineer 🦄🤤🥩🏳️🌈 Compulsive Autodidact: ML + FinTech // AI + Generative Art + NFT + 3D
In LLM pre training, curating and preparing data is perhaps the most impactful step. NeMo data curator is now open source with lots of features you will need. We used it to curate trillions of tokens for our own models training. https://t.co/vjuhtA2Rsy
Introducing SIMA: the first generalist AI agent to follow natural-language instructions in a broad range of 3D virtual environments and video games. 🕹️
It can complete tasks similar to a human, and outperforms an agent trained in just one setting. 🧵 https://t.co/qz3IxzUpto
Do you want to keep your humanity in the onslaught of AI's exponential progress? Immerse yourself in paradox because every time we break the symmetry of a paradox, we transcend to a new meaning. Recognize the awe that is everywhere.
Meta presents SpiRit-LM
Interleaved Spoken and Written Language Model
paper page: https://t.co/ESqeR4BzYu
introduce SPIRIT-LM, a foundation multimodal language model that freely mixes text and speech. Our model is based on a pretrained text language model that we extend to the speech modality by continuously training it on text and speech units. Speech and text sequences are concatenated as a single set of tokens, and trained with a word-level interleaving method using a small automatically-curated speech-text parallel corpus. SPIRIT-LM comes in two versions: a BASE version that uses speech semantic units and an EXPRESSIVE version that models expressivity using pitch and style units in addition to the semantic units. For both versions, the text is encoded with subword BPE tokens. The resulting model displays both the semantic abilities of text models and the expressive abilities of speech models. Additionally, we demonstrate that SPIRIT-LM is able to learn new tasks in a few-shot fashion across modalities (i.e. ASR, TTS, Speech Classification).
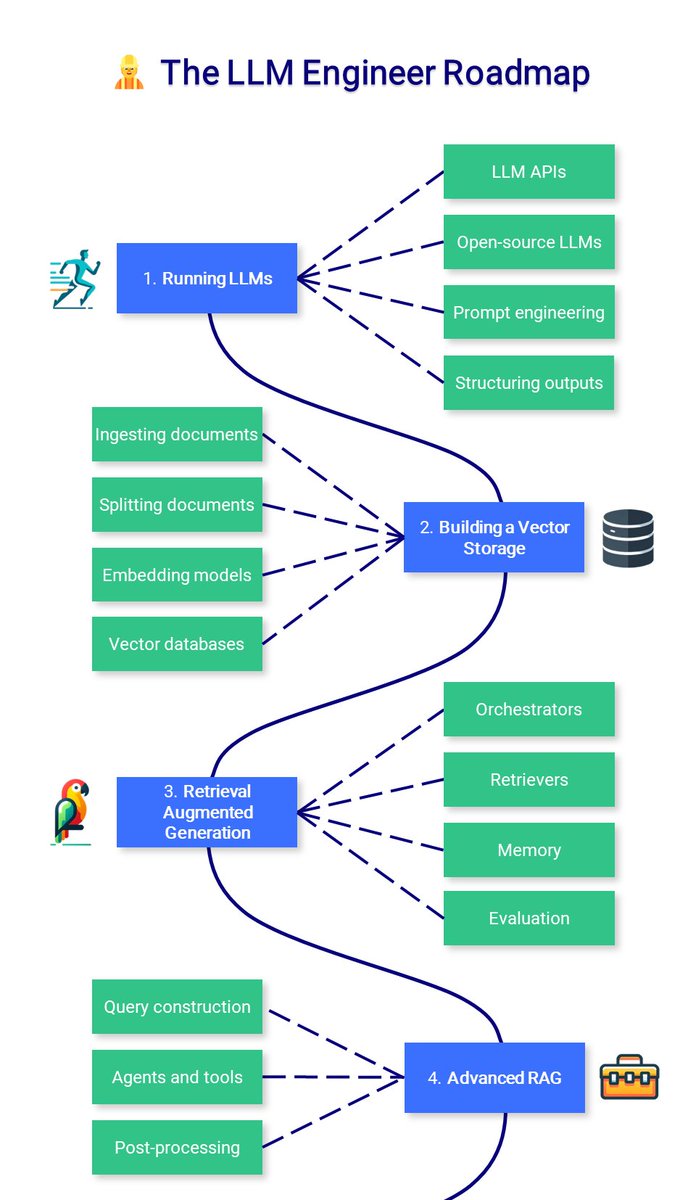
🧑🔬👷 The LLM Course is now complete!
I added the LLM Engineer Roadmap, a list of high-quality resources to build LLM-powered applications and deploy them.
💻 LLM Course: https://t.co/hsdjIpgJ0R
Kinara Ara-2 Processor: Upcoming game-changer in Edge AI acceleration. Unmatched performance, cost-effectiveness, and efficiency for Generative AI and transformer-based models.
Potential to supplant higher-cost and power-intensive GPUs.
https://t.co/M6HGJ2odi4
PrivateGPT is a production-ready service offering Contextual Generative AI primitives like document ingestion and contextual completions through a new API that extends OpenAI’s standard.
Talk to your documents privately using the default UI and RAG pipeline or integrate your own.
Meet StreamingLLM! Use LLMs for infinite input streams without losing efficiency and performance.
Now, you can build a ChatBot that persistently works on your recent chats!
📄 Paper: https://t.co/XOXN5o9YJL
🔧 Code: https://t.co/u67QTC3rzh
Tomorrow I'll be presenting Instruct-NeRF2NeRF at #ICCV2023! Come watch the talk tomorrow at 4:30 in Paris Sud or come by the poster (#164) to chat at 2:30 in Foyer Sud!
https://t.co/F7Tf3n3p8S
We enable instruction-based editing of NeRFs via 2d diffusion models!
🚀 LLaVA-1.5 is out! Achieving SoTA on 11 benchmarks, with simple mods to original LLaVA! Utilizes merely 1.2M public data, trains in ~1 day on a single 8-A100 node, and surpasses methods that use billion-scale data.
🔗https://t.co/y0kG0WZBVa
🧵1/5
Releasing Yarn-Llama-2-13b-128k, a Llama-2 model, trained for 128k context length using YaRN scaling. The model was trained in collaboration with u/bloc97 and @theemozilla of @NousResearch and @Void13950782 of @AiEleuther.
@github Zenith Z-158 with Amber Monitor. I had Math Rabbit and Reader Rabbit on wizard disks!
...that's about all I knew how to do with it since I was too young to understand how to buy software; it would be years before I understood consumerism.