I spent the last few weeks building a fantasy football projection tool that does something most projection sites won't: tells you when your decision is a coin flip.
https://t.co/70hec5L9zh — thread on how it works and what I found 🧵/1
New Content Alert:
Linear regression says one subgroup's "Very Satisfied" share fell by 8pp.
The actual data show it rose by 7pp.
Sign flipped — and the model was properly specified.
This is how linear routinely breaks on Likert outcomes. 🧵(+ two posts & a shiny app!)
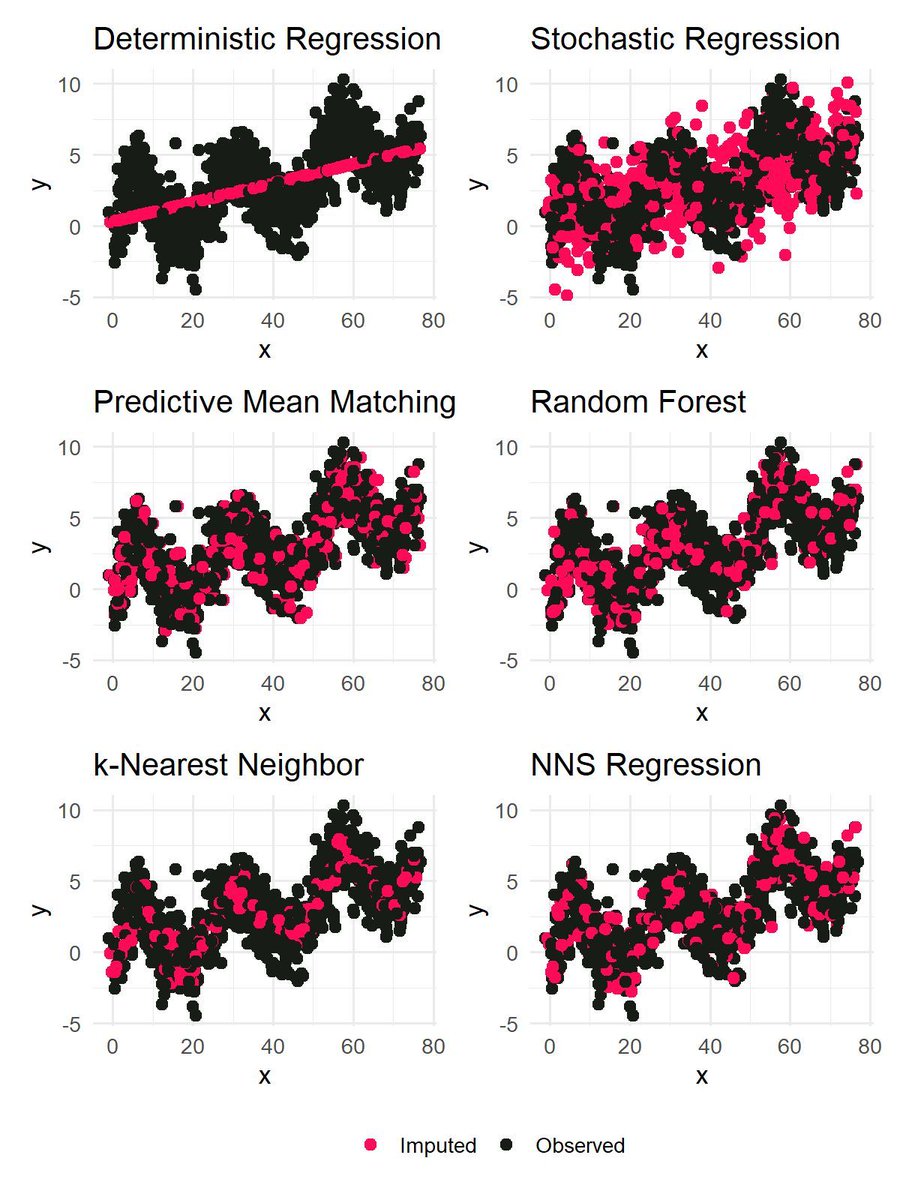
The mice package is often considered the gold standard for missing data imputation in R. It provides a flexible and well-established framework for multiple imputation and is widely used in practice. That said, there are many other packages and methods available that may also be worth a closer look.
Two approaches that regularly come up in discussions are Nonlinear Nonparametric Statistics (NNS) imputation and k-Nearest Neighbor (kNN) imputation.
NNS imputation is based on nonparametric regression ideas. It relies on local neighborhoods in the data and is designed to capture nonlinear relationships without strong distributional assumptions. Because of its data-driven nature, it can perform well when classical model assumptions are violated.
kNN imputation is a donor-based method. Missing values are filled in using information from the k most similar observations, based on a distance measure computed from the observed variables. It is conceptually simple and often intuitive, especially in settings with strong local structure in the data.
The figure below compares these approaches with several mice-based methods. Deterministic regression produces overly smooth imputations, while stochastic regression adds noise but may still miss local structure. Predictive mean matching and random forest generally preserve the observed distribution well. kNN and NNS focus on local similarity and can reproduce nonlinear patterns more closely. However, kNN does not properly reflect variability in the data. In contrast, NNS performs close to the well-established approaches predictive mean matching and random forest.
In my currently running course on Missing Data Imputation in R, I have just added two bonus modules that explain NNS and kNN imputation in more detail. Both modules include theory, reproducible R code, and direct comparisons with mice-based methods.
If you are interested, you can check out the course here: https://t.co/i99PuXw3TZ
All course content is still available, and by registering you get lifetime access.
Talk to you soon,
Joachim
#rstats #statistics #datascience #statisticalanalysis
I gave a talk at @CarnegieMellon today about human #morality in the anthropocene
Although much of human morality evolved in an environment of small group living, the primary source of moral content for over 5 billion people now comes from social media. I argue that this technological transformation has created an entirely new moral ecosystem--driven by the attention economy--that is often mismatched with our evolved adaptations for social living.
One means by which individuals and groups can capture attention and drive engagement on these platforms is by sharing moral-emotional and divisive content. Therefore, social media often acts as an accelerant for existing moral dynamics, amplifying outrage, status seeking, and polarization. This has serious implications for our epistemic environment and social institutions.
For each additional moral–emotional word in a social media post, the expected number of shares is 13% greater.
Our new meta-analysis in @PNASNexus finds robust evidence of moral contagion (N = 4,821,006; 5 labs, 27 studies).
The moral contagion effect is even stronger in larger, pre-registered studies (a 17% increase).
Our paper was led by @william__brady@steverathje2 and @laura_k_globig
📢 Call for Papers 📢
We’re looking for original research that pushes boundaries, challenges assumptions, and contributes to key debates in criminology and criminal justice.
🖊️ Submit your work: https://t.co/h00sKkexhn
#Criminology#CriminalJustice
A huge win for the R community & kudos to the #tidyverse team! I'm super excited to try purrr 1.1.0 first thing in the morning 😻
https://t.co/60JaJeoW5o
@RealJonBrauer@lonecrim Just packed that up in a moving box last night and thought “Man, I gotta read this soon” 😁! Interested in the micro-macro (and perhaps reciprocal) links the authors hopefully make.
@lonecrim@RealJonBrauer Interesting that other philosophers- Sam Harris and Dan Dennett also seem to support a kind of deterministic model, though Dennett makes explicit room for the need for corrective action and “blame.” Makes me always circle back to bounded agency/rationality.
@lonecrim I’ll have to give your paper a read! @RealJonBrauer and I had some conversations about this after both reading (listening) to Sapolsky’s “Determined” book. Jon then listened to “Free Agents” by Kevin Mitchell and he shared some critical takes on Sapolsky’s argument.
Social scientists today do their work in silos, surrounded only by those who share their assumptions and intuitions.
Adversarial collaborations, therefore, may play a key role in stimulating our collective creativity and scientific innovation.
New in Theory and Society: "Reflections on adversarial collaboration from the adversaries: was it worth it?" Check out the article here (open access!): https://t.co/HdIvfPy6k5
(Written by the always fascinating @PTetlock@ImHardcory and Calvin Isch)
Yeah. Don't do this. History helps us avoid falling into the same mistakes over and over again. The sooner we distance ourselves from the narcissism of the present the better off we'll be.
Finally got around to incorporating all Github feedback on my open access textbook, making around 20 minor improvements, and updating some references. 17 chapters of state of the art stats and methods education, freely available for any course you teach. https://t.co/FdQIS63fVd
New preprint! Do crime projections = behavior? We test congruence & dynamics using panel (🇧🇩) & cross-sectional (🇷🇸🇧🇦) data. Projections predict, but...
https://t.co/IzKPW8tgW2
#criminology#crime 1/n
Check out my first preprint! In it, @Jake_Day4 & I encourage ordinal modeling for analyzing ordinal outcomes. We show how to quantify effect magnitudes w/greater accuracy & precision, helping us move us beyond just interpreting stat significance & broad directional statements.