To make the most out of LLM-powered systems or products today, never go with the mindset that it should replace anything. You will be greatly disappointed if you do so.
The best approach is to use it as a tool to augment a workflow or process. Even the most advanced tools like ChatGPT require careful customization, personalization, and steering for a lot of useful real-world tasks like code debugging or research assistants. Your expertise matters a lot.
Don't be surprised, this is exactly how these systems are meant to be used. They are not meant to be used as autonomous agents that complete tasks while you sit back and relax. Not yet as far I know. They are like copilots and work best when you can figure out how to best integrate your expertise/knowledge and collaborate with them.
Need to take this in account, because the cost of host a model vs let process our data by openAI. Maybe if the quantity of tokens related to CPU and memory metrics do not consume so much tokens like the logs. The is faster to use openai for vectorize them
Exploring LLM Pricing
With so many new LLMs, how do API costs compare?
I delved into cost comparisons of models that I would use in production.
Main takeaways:
• cohere leads with cost-effective model
• gpt-3.5 remains excellent value
• mistral cost higher than anticipated
• gemini 1.0 pro is pleasant surprise
• gpt-4 is very expensive
Models are ranked by input cost, asc.
This is interesting, because some data i dumped from metrics is on tabular format. Also want to analyze some other data like list of resources from AWS.
LLMs on Tabular Data
An overview of LLMs for tabular data tasks including key techniques, metrics, datasets, models, and optimization approaches.
Also covers limitations and unexplored ideas with insights for future research directions.
I highly recommend @_nerdai_'s notebooks and diagrams for any RAG developer, whether you're a beginner or expert.
This notebook is a comprehensive introduction to RAG for those just getting into the space 👇
In naive RAG, the vector db is primarily used for unstructured data. Yet most use cases involve both unstructured and structured data - you want a RAG architecture that can query both data and store it in the same db!
Excited to feature this new blog post by @ClickHouseDB which outlines a RAG architecture over structured/unstructured data.
✅ It uses @llama_index query capabilities combining both structured (StackOverflow) and unstructured (HN) data (SQLAutoVectorQueryEngine)
✅ It uses @ClickHouseDB as a single storage layer for both structured tables and unstructured text chunks.
Check it out!
Blog: https://t.co/GoMVZlsCoB
Different types of queries require different retrieval parameters. For instance, in hybrid search, the optimal alpha value for a user entering keywords would be close to 0, while the optimal alpha value for a user asking natural language questions would be close to 1.
A cool idea here is you can create a dynamic query interface by having the LLM pick the optimal alpha parameter for hybrid search depending on the query!
Check out our Koda Retriever pack for more details: https://t.co/qP2fdbd34h
What state representation should robots have? 🤖 I’m thrilled to present an Any-point Trajectory Model (ATM), which models physical motions from videos without additional assumptions and shows significant positive transfer from cross-embodiment human and robot videos! 🧵👇
What happens when RAG models are provided with documents that have conflicting information?
In our new paper, we study how LLMs answer subjective, contentious, and conflicting queries in real-world retrieval-augmented situations.
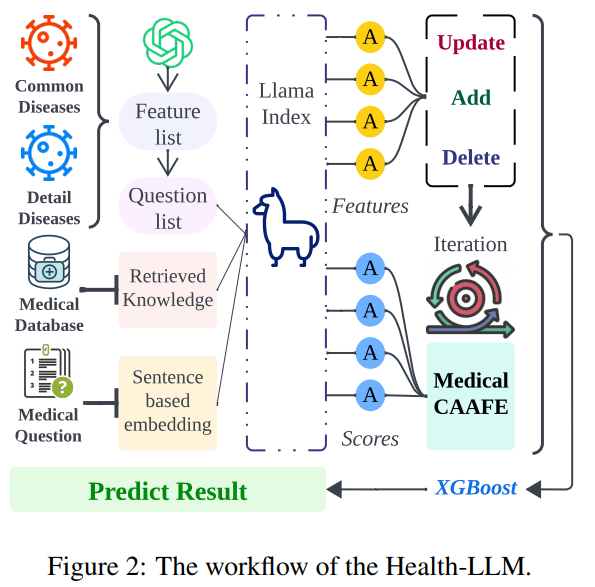
Health-LLM: Personalized Retrieval-Augmented Disease Prediction Model
Proposes a framework integrating LLMs and medical expertise to enhance exploitation of health reports for disease prediction and preventative care.
📝https://t.co/FeFimU3rxz
👨🏽💻https://t.co/lQDElymqmd
Accelerating the Science of Language Models
This is huge!
@allen_ai just released its first Open Language Model (OLMo), a 7B parameter model.
It includes open training code, open data, full model weights, evaluation code, and fine-tuning code.
It shows strong performance on many generative tasks.
There is also a smaller version of it, OLMo 1B.
I will be writing a complete prompting guide for this. Stay tuned!
This is brilliant work and will ignite even more research opportunities for the AI community.
Adding Agentic Layers to RAG
Here’s an in-depth presentation showing you how to add agentic layers to your RAG pipeline - better understand/intuit how using increasingly more tokens leads to increasingly higher QA performance! 🪜
Helps you better plan for your use case vs. just plopping in a pre-built agent implementation.
We gave this talk at the AI User Conference yesterday, and we’re making it available with full @llama_index guides in each section. Check it out 👇
https://t.co/O6Q1f5LAyd
Check out this awesome architecture by @Otmane404 on how to spin up a fully local RAG API - serving all your edge device/data privacy needs 🔥
Stack: @llama_index, @qdrant_engine, @ollama, @FastAPI
Blog: https://t.co/htVmO7DLZB
Repo: https://t.co/Yy2mMbwT4e
Because we need to load data from prometheus for the server metrics, decided to create a prometheus reader for llamahub, to be able to load the data with llamaindex, already sent my PR:
https://t.co/nRc4TXiYH3
Hoping gets approved soon.
As many of you know, over the past few months I have been sharing Prompt Engineering resources in different forms. I have now compiled them all into a cohesive publication and uploaded to arxiv: https://t.co/7TZgGF67lj
Some nerd stuff! 🤓
- If you want a very simple way to play with it, check out our Github repo: https://t.co/zgMT0C2g4q
- You'll need a TON of VRAM to this fast. We've found doing AWQ quantizations a really good to keep accuracy high while keeping latency and VRAM low. Would recommend!
- Larger models have so much more "intelligence" than smaller ones. This had a very similar dataset as our 34B model, but performs significantly better. It does have some know flaws and weirdly trips up on certain words (like "domain", strangely) – but we'll fix that soon
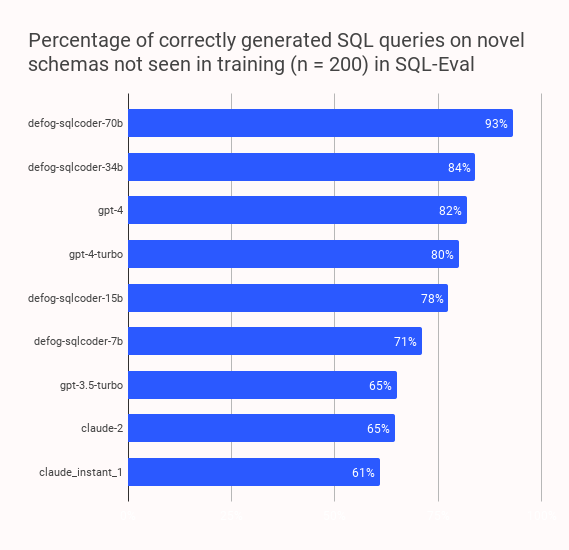
We just opened sourced SQLCoder-70B! It outperforms all publicly accessible LLMs for Postgres text-to-SQL generation by a very wide margin.
SQLCoder is finetuned on @AIatMeta's CodeLlama-70B model that was released yesterday on less than 20,000 hand-curated prompt completion pairs.
You can find it on @huggingface at https://t.co/abHsKzWYGW. This follows our 15B, 7B, and 34B models – and is the most capable of them all.
The model has a cc-by-sa-4 license, which means that you are free to use it as is for any use (including commercial) as long as you also open-source any changes to you make to it (i.e., if you fine-tune it further).
Interested in making your bipedal robots to be athletes? We summarized our RL work to create robust & adaptive controllers for general bipedal skills. 400m-dash, running over terrains/against perturbations, targeted jumping, compliant walking, not a problem for bipeds now.🧵👇
Let's build RAG-powered stuff that's not chatbots 🔥
We're excited to partner with @DataStax to host an in-person "Beyond Chatbots" RAG hackathon this weekend.
Huge shoutout to @DataStax to offering their office space, and big thanks to our sponsors and partners as well! @bentomlai@nvidia@DistylAI@vectara@render@diffbot@AIMakerspace@reconifycom
If you're there, we might have a special announcement for you :)
https://t.co/jlpdJQqzxo