One piece of advice we got during YC was to explain our company using verbs instead of nouns.
Early on, I walked into a meeting and did the opposite:
“We’re building a cloud platform for AI”
No one knew that that meant, their eyes glazed over. Then I started saying this instead:
“We containerize your code and run it on GPUs in the cloud so you don’t have to manage the infra yourself”
That clicked way more. Our brains understand verbs because they’re more concrete. If you describe your company using nouns, you risk people not understanding you.
And no one buys or invests in things they don’t understand.
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
https://t.co/g4Ybfa2kWH
MiniMax Sparse Attention:
https://t.co/HcTlWRotG3
SpaceX has just officially unveiled its AI1 satellite, the first generation of its AI satellite.
Overall Specs:
• 150 kW peak compute payload
• 120 kW average compute payload
• 70 kW per ton
• Compute provider interchangeable
Dimensions:
• Wingspan: 70 meters
• Deployed height: 20 meters
Thermal System:
• 110 m² deployable liquid radiator
• Redundant pumping loops
• Integrated micrometeoroid shielding
• Deployable liquid radiators
Solar Power System:
• 150 kW solar array
• 250 W/m²
• SpaceX-manufactured solar technology from Bastrop, Texas
Architecture:
• Centralized compute module
• Large deployable solar arrays
• Deployable liquid-radiator thermal management system
• AI-focused compute satellite design ("AI1 satellite")
Elon: "The AI satellite is much simpler than a Starlink satellite. The AI satellite is essentially a lot of solar cells, you still need some laser links, but you don't have all of the super complex antennas that you have on a Starlink satellite. The easier one to design for is the AI satellite. It's bigger. A lot of this is technology we've already made with the Starlink V3 satellites."
@elliotarledge Claude code cli via terminal has been my meta and it’s not close vs web apps, cowork, etc. When I switched from vscode/cursor to Zed, it was a massive ux improvement for me (~8-10 months ago). Have been happy since but prob just complacent - how does cmux change this?
Everyone is focusing on the soaring memory cost in the Vera Rubin rack. But the real shocker in this Morgan Stanley slide is actually power, because the industry is now talking about moving from roughly 120kW per rack today toward potentially 600kW per rack by the Vera Rubin Ultra generation in 2027, which is an almost unimaginable escalation in power density within an incredibly short period of time.
To put this into perspective, many traditional enterprise datacenters historically operated at only a few kilowatts per rack, while even modern hyperscale campuses today often consume only tens of megawatts in total facility power draw. But once you begin deploying hundreds or thousands of 600kW AI racks simultaneously, the math becomes almost absurd because a large-scale Vera Rubin Ultra cluster could eventually consume gigawatts of electricity, effectively rivaling the energy demand of a mid-sized city.
And this is where the market still massively underestimates the second-order implications of the AI boom, because the bottleneck is no longer simply semiconductors, GPUs, or memory supply. The bottleneck increasingly becomes electricity itself.
The US power grid can barely keep up with current AI infrastructure demand already, while transmission congestion, transformer shortages, substation constraints, cooling limitations, permitting bottlenecks, and aging grid infrastructure are becoming increasingly visible across major datacenter hubs. Importantly, grid infrastructure cannot scale at semiconductor speed. You can accelerate chip production with enough capital expenditure and engineering talent, but building transmission lines, substations, generation capacity, cooling systems, and interconnection approvals often requires many years due to environmental reviews, local opposition, labor shortages, and physical construction constraints.
This is precisely why we continue believing the AI buildout is not a two-to-three-year investment cycle, but instead a decade-long industrial transformation that increasingly resembles the buildout of railroads, electricity networks, and telecom infrastructure during previous industrial revolutions.
And this is also why energy infrastructure is quietly becoming one of the most important and underappreciated AI trades globally.
The winners are no longer just GPU companies. The winners increasingly include utilities like Constellation Energy and Vistra, nuclear-related plays like Oklo and NuScale Power, gas infrastructure companies like Kinder Morgan and Williams Companies, grid and electrical equipment suppliers like GE Vernova, Eaton, Schneider Electric, and Vertiv, as well as transformer, cooling, and datacenter infrastructure providers that now sit directly inside the physical backbone required to support next-generation compute.
Hyperscalers themselves are starting to understand this reality. Companies like Microsoft, Amazon, Alphabet, and Meta are no longer simply software companies buying servers. They are increasingly becoming quasi-energy infrastructure companies because securing long-duration power availability is becoming strategically inseparable from securing compute capacity itself.
That is why nuclear power is quietly returning to the center of the conversation. Hyperscalers may eventually fund or directly partner on nuclear generation projects out of pure necessity because renewable intermittency alone cannot reliably support ultra-high-density AI clusters operating continuously at scale.
In many ways, AI is beginning to collide with physical reality. You cannot run trillion-dollar next-generation compute infrastructure on transmission systems and grid architectures that were largely built decades ago for a completely different industrial era.
The semiconductor story may have started the AI race, but energy infrastructure may ultimately determine who wins it.
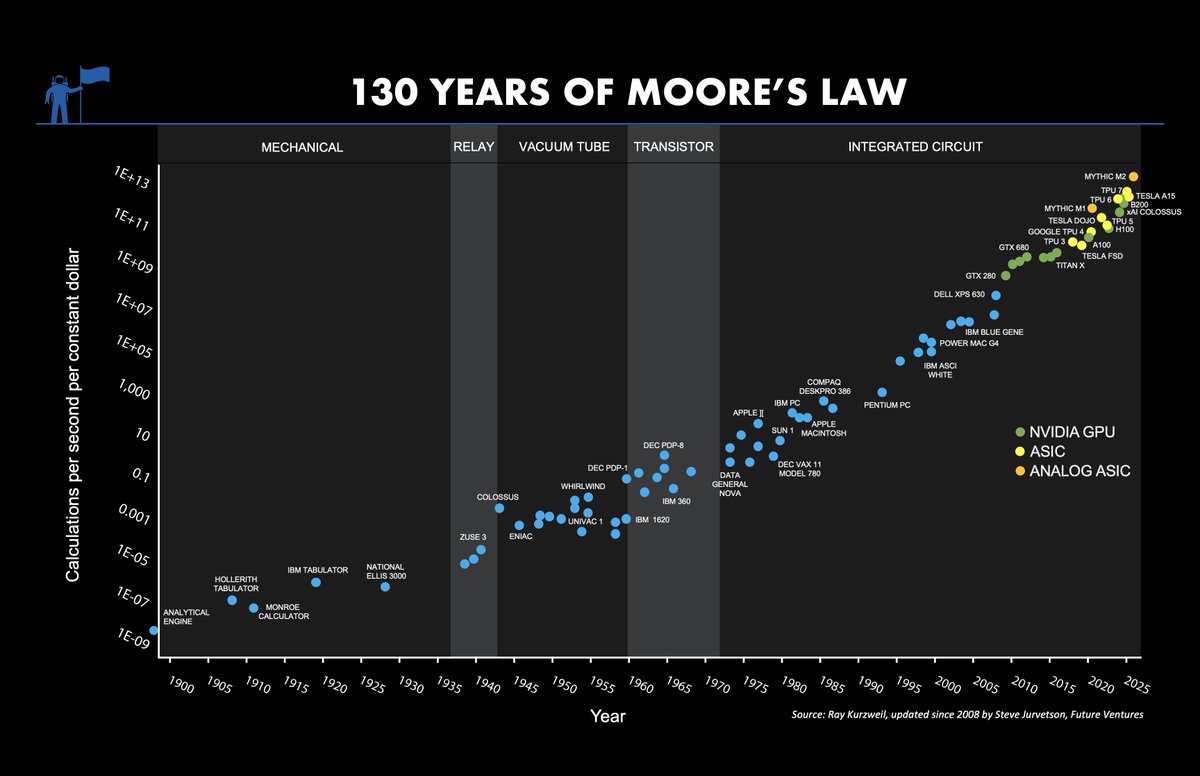
On the silicon side, it's the era of analog inference.
This company combo will deliver the first hybrid AI platform with 100x more compute per watt than the best GPUs.
How? Mythic performs the core AI operation (8-bit multiply & add) in a single flash memory transistor. Compare this to ~3,000 transistors in a digital circuit, the kind every other AI chip uses.
· Mythic acquires Videantis news today: https://t.co/UH5NYqTHLo
· Company: https://t.co/sDWw2pJ4cE
Semianalysis published a table last night that does more for the demand side narrative than 6 months of analyst commentary lol.
Token cost vs human labor cost on 9 real internal workflows. and EVERY SINGLE ONE had ROI over 10x (most landed between 60 and 90x)
The workflow that stuck was an initiation note on $HPE, covering roadmap, balance sheet, and capex sustainability. The cost in tokens was 21,33$.
The cost in analyst time, at 20 hours and 50 dollars an hour, was 2k dollars (so ROI of 93x)
You can argue about how generalizable a single workflow is but it's hard to argue with the moment the analyst sees the receipt. The workflow does not go back. The senior analyst will not return to a process that costs 90 times more, and the junior will not be allowed to.
The reason this is not cyclical demand is the reason the cotton gin did not roll back. Once the labor cost of a task drops by 90 plus percent, the unit of work changes.
The old workflow is not slow, its gone.
The buyers of intelligence at every desk in finance, law, consulting, and biotech are about to spend the next 2 years rediscovering that they have been paying 100x more than the new floor for the same answer.
The other line in the SemiAnalysis post that stuck out was that banks are not using this yet. Most enterprises are not. The token bill of the next 24 months is going to be funded by people who saw a 21 dollar receipt and could not unsee it.
The demand curve does not bend until the supply curve does
This is my sixth conversation with @GavinSBaker.
As always with Gavin, the conversation covers a lot of ground, but we spend the most time on watts and wafers.
We discuss:
- Why the wafer shortage may prevent an AI bubble
- Data centers in space (reframed)
- Elon's Terafab and the new chip companies challenging Nvidia
- Usage-based pricing
- The disaggregation of GPUs
- DRAM, frontier tokens, and open source
Enjoy!
Timestamps:
0:00 Intro
7:55 Anthropic and OpenAI Valuations
12:58 Watts, Wafers, and Infrastructure
14:39 Orbital Compute and Data Centers in Space
22:49 Avoiding the AI Bubble
28:26 Terafab and the Future of US Manufacturing
32:16 Returns to the Frontier
37:23 Continual Learning
42:03 New Chip Companies
48:52 Extending GPU Lifespans and Private Credit
51:22 The Application Layer
57:32 The Token Path and Open-Source Dynamics
1:01:37 Cybersecurity
1:05:46 Diversity Breakdown
1:11:59 Assessing the Big Tech Players in AI
1:19:02 Geopolitics, Personal Safety, and the AI Horizon
From @ttunguz on how Anthropic is borrowing from Google's early strategy:
"If you have a really good business, what you want to do is look at all the people who have businesses around you, and make all of those products free so that more people end up using your product.
That’s called "commoditizing the complements". You commoditize everything that’s complementary to you.
Let’s make this concrete. If you’re Google and you make money when people click on search ads, you want to make it so that people click on as many ads as possible.
What did they make free? Well, it used to be you paid for email. Okay, email was now free. And then it used to be that you paid for video hosting, because video hosting was really expensive. But then they bought YouTube and made that free.
And it used to be that you would pay a license to have an operating system on a mobile phone. Then they bought Android, and then they made that free. And then it used to be that you would buy a dedicated GPS device to navigate your car from one place to another, and then they ended up buying Keyhole and making Google Maps and Google Earth free.
And then they bought all these books and scanned all of them and put them in the index. So it was just driving more and more searches. Google Docs, same thing.
So you’re just using the internet more. By virtue of the fact that you’re using the internet more, and it was free, so there was less friction, you would go to Google more. And then you would get more ads, and Google would make more money.
If you’re Anthropic, you can run a very similar strategy. Anthropic is selling inference. They are selling a prediction of an AI system.
There was all this workflow software in the previous decade. Maybe it’s legal software, or finance software, or accounting. I’m just picking categories at random.
But you don’t to charge per seat anymore. That’s silly, because the amount of money people will pay per seat is maybe $500 per month, compared to the amount of inference they’ll buy, at $2,000 a month.
Just give away the $500 seat, and have them buy more inference. You’ll make a whole lot more money, and you'll also have less competition.
I’m just observing from the outside, but that’s a very game theoretical optimal way of maximizing when you have a really phenomenal business.
Anthropic wants to make sure everything else is free, so there are as many inference queries on their products as possible."
The arms race of quant funds making vids about water cooling AI data centres is unreal.
Hudson River Trading uses one in Norway cooled by fjord seawater. It’s piped into a former mountain-side mineral mine now hosting GPU racks.
Heated water sent to a land-based salmon farm nearby and the farm produces 15,000 tonnes of salmon a year. Salmon are very sensitive to water temperature and the data center water (that came in cold from the fjord) is now heated to a salmon-friendly 20°C.
When is the RenTech data centres water optimization video dropping?
I read a lot of Peter Lynch. Met him once. The one rule I carry into tech investing is the most boring one he ever wrote, know what you own, down to the physics if the position demands it. For me that has meant living inside NVIDIA's stack for years, and pulling apart the alternatives next to it, Trainium, the TPU, every serious accelerator someone is willing to tape out against Jensen. I was also an early investor in Mellanox, the networking company NVIDIA bought to own the switched fabric the entire scale up era now runs on. So when the conversation turns to networking as the real moat, this is not theory to me. It is a position I watched become the thesis. You do not understand what you own until you understand what could take it.
@GavinSBaker at @SohnIdeaContest just gave the most physically grounded read on AI infrastructure I have heard this cycle, and it is a Lynch lesson in disguise. The reframe that matters:
The last terrestrial mega data center may already be on someone's drawing board.
Everything else follows from two constraints, watts and wafers, and Gavin walks both down to first principles. That is the work. Most people are pricing the narrative. Lynch would have asked what the thing actually is.
1. TSMC is the global rate limiter
Jensen reportedly visits every quarter asking to double or triple leading edge capacity. TSMC expands at roughly 5 percent. A handful of disciplined operators in Taiwan are the physical governor on the entire AI buildout.
This is the part the bubble crowd misses. The constraint is not demand and it is not capital. It is one fab's deliberate refusal to overbuild. That stretches the cycle longer and smoother instead of bubble and bust. It reads like the mid 1990s capacity cycle, not a standard 25 year memory peak where a 60 to 70 percent price spike would be your signal to cut the weed and walk.
I have held NVIDIA since 2016 for exactly this reason. Owning it meant understanding it. The thesis was never the chip. It was the chokepoint.
2. The most underestimated silicon is Trainium
Consensus is still pricing a one horse race. Gavin's sharpest non NVIDIA call is AWS Trainium, specifically Trainium 3 ramping in the back half of 2026. Here is the part that took me a while to internalize from studying these architectures side by side. As frontier models go fully Mixture of Experts, inference stops being a matmul problem and becomes a networking problem. You need a switched scale up fabric, not just fast chips. Today two organizations on earth have a working one. NVIDIA and Amazon. NVIDIA's came from Mellanox, which is the whole reason I sized that position the way I did years ago, the bet was always that networking would decide this, not raw flops. The TPU is formidable in its own lane, but the scale up fabric is the moat people are not modeling, and it is why I track every accelerator, not just the one I own.
3. The neocloud moat is operational, not arbitrage
The lazy take is that CoreWeave and Crusoe are just renting hyperscaler slack. Gavin's counter is that running dense GPU clusters is like driving an F1 car. Looks easy until you try it. Top tier neoclouds run 2 to 3x the hardware utilization per hour of lower tier providers. That is an execution and inventory moat, and it compounds.
4. The structural short nobody is pricing
Watts and wafers eventually force the buildout off the planet. Gavin expects orbital data infrastructure to prove technical and economic viability within roughly two years and take meaningful share by the end of the decade. Space solves power with unattenuated solar and solves cooling with massive radiators in the satellite's own shadow. Dense single rack nodes stitched together with lasers into a virtual hyperscale cluster in orbit.
The unpriced risk is everything that over expanded to serve a terrestrial buildout. Cooling, power, industrial equipment names sized for a curve that may bend down within seven years.
The whole interview is a lesson in pattern recognition over narrative. Lynch built a career on retail investors knowing their companies better than Wall Street did. The same edge exists in AI infrastructure right now, it just requires you to understand watts and wafers instead of same store sales. If you are not modeling the physical boundaries of the stack through the lens of history, you are not underwriting the position. You are following it.
$CBRS Part 2: 30m shares @ 155 mid point
Feedback has been its a PIG PILE with all the major funds fighting for an allocation = more shares + higher pricing. People dont want to miss a CRWV or ARM like post ipo move is the sentiment... "only free alpha left" as we have discussed
I talked to a couple deep specialists who saw them in NY ... everyone wants in... and L/S guys want to short it after the pop.. if they can get a borrow, is a whole other story
A RUNAWAY ipo is bad news for a book runner... so expect them to keep upsizing shares + price (or both) into the pricing... I did a whole long post on IPO pricing and outcomes, this could be a case study, we shall see
Prices Wednesday and Trades Thursday likely early afternoon (as of now)
Play with your own forecast numbers below... remember that share count... Good Luck
Researchers found a way to make LLMs 8.5x faster!
(without compromising accuracy)
Speculative decoding is quite an effective way to address the single-token bottleneck in traditional LLM inference.
A small "draft" model first generates the next several tokens, then the large model verifies all of them at once in a single forward pass.
If a token at any position is wrong, you keep everything before it and restart from there. This never does worse than normal decoding.
But current drafters in Speculative decoding still guess one token at a time. That makes the drafting step itself a bottleneck, capping real-world speedups at 2-3x.
DFlash is a new technique that swaps the autoregressive drafter with a lightweight block diffusion model that guesses all tokens in one parallel shot.
Drafting cost stays flat no matter how many tokens you speculate.
On top of that, the drafter is conditioned on hidden features pulled from multiple layers of the target model and injected into every draft layer, so it makes significantly better guesses than a drafter working from scratch.
In the side-by-side demo below, vanilla decoding runs at 48.5 tokens/sec. DFlash hits 415 tokens/sec on the same model, with zero quality loss.
It's already integrated with vLLM, SGLang, and Transformers, with draft models on HuggingFace for several models like Qwen3, Qwen3.5, Llama 3.1, Kimi-K2.5, gpt-oss, and many more.
I have shared the GitHub repo in the replies!
KV caching is another must-know technique to boost LLM inference. I recently wrote an article about it. Read it below.
👉 Over to you: What use case are you working on that can benefit from this new technique?
We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity.
This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
“You can’t leisure yourself to meaning.”
— LucasArts & Epic Games President Paul Meegan, reflecting on six months of attempted retirement before reenlisting the core Fortnite team to pursue a new learning-tech startup with the mission to help every person maximize their potential and live a life of meaning.
Fortnite is the compelling collaborative game that grew to 250 million users and $6.3B in revenue in its first year. “AWS told us Fortnite is their #2 customer, second only to the CIA.”
The new company is in stealth mode for now but has found a deep reservoir of motivation and meaning in their pursuit of a meaningful mission. Not just for two billion children but lifelong learning and reskilling for adults as well: “60 million American adults are functionally illiterate and innumerate.”
In contrast, companies like “OnlyFans, Affirm, Klarna and DraftKings democratize exploitation of the user.”
Interviewed by the intrepid Brendan McCord, founder of Cosmos Institute — the academy for philosopher-builders: https://t.co/i44fqpdwh4
One of the most substantive classes with @ChaseLochmiller at Stanford. We went deep on economics of the datacenter:
- Where is the ~$650B of AI infra capex actually going this year?
- Who's capturing the margin, who's getting squeezed?
- How the bottleneck has moved from GPUs to power, and where it goes next
- The economics of neoclouds