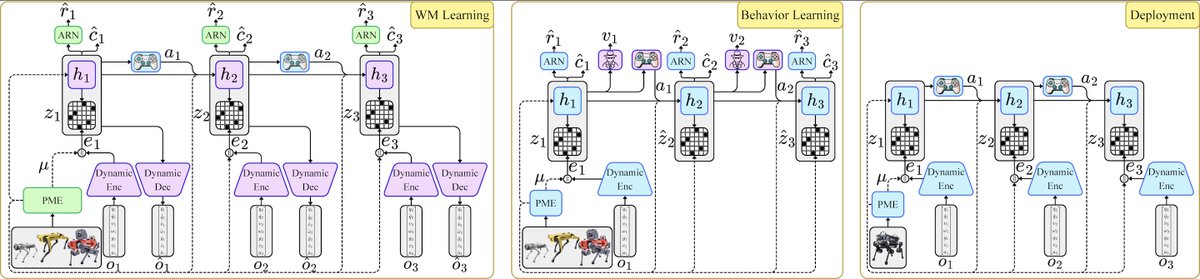
📢 New paper out!
We introduce QWM: a single locomotion world model trained across 8 quadrupeds and deployed zero-shot on robots it had never seen by conditioning on their morphology specs: ANYmal-D and Unitree Go1 🦾
No fine-tuning, no warm-up, no retraining from scratch.
The key insight: robot morphology isn't a latent variable to infer from motion history, it's a known engineering spec sitting in the USD (or URDF) file. So we just use it directly.
The absolute peak of doing science is witnessing, for the first time, something that the world hasn't seen before.
Happened to me today. Can't wait to tell you more about it.
@KyleStachowicz@ChongZzZhang In other words, theoretically, if the underlying MDP has bounded actions, parameterizing PPO with an unbounded Gaussian creates a support mismatch. Wouldn't a natively bounded distribution be strictly cleaner?
The code is now available! 🚀
DriftQL learns a one-step Q-guided actor corrected by a learned drift field. We beat baselines with no denoising, solvers, auxiliary actors, or distillation.
💻 Code:
https://t.co/oPOysnlYFh
The code is now available! 🚀
DriftQL learns a one-step Q-guided actor corrected by a learned drift field. We beat baselines with no denoising, solvers, auxiliary actors, or distillation.
💻 Code:
https://t.co/oPOysnlYFh
Excited to share DriftQL☄️, a new paradigm for offline RL.
Instead of fitting a behavior prior, DriftQL learns a one-step Q-guided actor whose samples are corrected by a drift field.
Simple. SOTA on OGBench/D4RL. No denoising. No solvers. No auxiliary actor. No distillation.
With my co-authors @mo_danesh, Amin Abyaneh, Scott Fujimoto, Hsiu-Chin Lin, David Meger
🌐 https://t.co/RFfvUiAlW9
🧵
AutoEval appears to be paused and may potentially be discontinued. For my research, I've trained on the BridgeData V2 and need a remote setup for real-world evaluation.
Are there any alternative remote evaluation platforms, shared testbeds, or labs that support Bridge-style setups and allow external researchers to deploy policies remotely?
Excited to share DriftQL☄️, a new paradigm for offline RL.
Instead of fitting a behavior prior, DriftQL learns a one-step Q-guided actor whose samples are corrected by a drift field.
Simple. SOTA on OGBench/D4RL. No denoising. No solvers. No auxiliary actor. No distillation.
With my co-authors @mo_danesh, Amin Abyaneh, Scott Fujimoto, Hsiu-Chin Lin, David Meger
🌐 https://t.co/RFfvUiAlW9
🧵
Excited to announce Michael Rabbat (Co-Founder & VP World Models - AMI labs @amilabs) as a new speaker joining our stellar lineup ✨
🌐 https://t.co/wMmrTZdfB0
📢 Call for Papers! #RLC2026 🇨🇦
🌎 We are now inviting contributions to the Workshop on Model-based RL in the Era of Generative World Models at @RL_Conference in Montreal, Canada! 🇨🇦
🔗 Webpage
https://t.co/y5rdTdnJ07
📄 Submit paper now!
https://t.co/NDYAXYdjyd
🧵Format
World models are becoming a powerful approach for making the most of available data, but how do we create them to help build better agents? Come check out this workshop at @RL_Conference and submit related ideas!
This is what made QWM possible 🏗️
Training 8 different quadrupeds simultaneously in one sim was a prerequisite for learning a policy (or a world model if you will) that generalizes across morphologies.
Full blog post: https://t.co/3cBFOWp58K
I trained a single PPO policy across 8 quadrupeds simultaneously: Spot, ANYmal (B, C, D), Unitree (Go1, Go2, A1, B2). 🤖
Same weights. Same compute as training on 1 robot. No core Isaac Lab changes.
Here's how we broke Isaac Lab's homogeneity assumption to make it work. 🧵👇 https://t.co/5IgcOWbhaD
I trained a single PPO policy across 8 quadrupeds simultaneously: Spot, ANYmal (B, C, D), Unitree (Go1, Go2, A1, B2). 🤖
Same weights. Same compute as training on 1 robot. No core Isaac Lab changes.
Here's how we broke Isaac Lab's homogeneity assumption to make it work. 🧵👇 https://t.co/5IgcOWbhaD
📢 New paper out!
We introduce QWM: a single locomotion world model trained across 8 quadrupeds and deployed zero-shot on robots it had never seen by conditioning on their morphology specs: ANYmal-D and Unitree Go1 🦾
No fine-tuning, no warm-up, no retraining from scratch.
The key insight: robot morphology isn't a latent variable to infer from motion history, it's a known engineering spec sitting in the USD (or URDF) file. So we just use it directly.
The trick: stop treating morphology as a mystery to infer, and start treating it as what it actually is a known engineering spec 📐
We read the robot's USD file, encode its kinematics, mass & actuation, and inject that into the world model's dynamics at every step. No adaptation lag. No warm-up. No dangerous trial-and-error on a real robot 🤖