Wait, the company that got the no-bid contract for the reflecting pool is called Greenwater Services? And we're surprised it turned green again? This is Four Seasons Landscaping levels or irony 😂 https://t.co/uBLA7VH8JX
The World Marathon Majors are officially getting bigger, and now, the series is adding a new continent to the map.
The Cape Town Marathon has been added to the series beginning in 2027, making it the eighth World Marathon Major. The 2027 race is scheduled for May 23, and it's the first race in Africa to make it onto the Majors calendar.
https://t.co/S4Xnke2Vhl
how to be good at your job
- realize this one thing is actually made up of two separate things
- realize instead of solving the direct problem you can solve a broader problem
- instead of implementing thing, implement other thing that makes it easier to implement thing
What kind of IC work can you do if you are a manager?
Attended two dinners with dozens of senior Bay Area tech managers last week.
Every single one of them said they were expected to be hands-on building with AI these days. But what to work on?
4 categories emerged:
1. Internal efficiency -- anything to make your team more productive, from communication tools to digital brain to team skills.
2. Quality-of-life improvement -- got something that bugs the heck out of you about the product but you can't convince anyone else to work on it? Just fix it yourself.
3. Celebration story -- artifact (usually video, image narrative, etc) that hypes up the work done by your team.
4. Vision piece -- describes a really freakin' cool future that your team can move towards.
What NOT to do: take on any critical-path product work. (Because then you either do a poor job delivering on that, or managing.)
As agents become the biggest users of software, then all software has to be available in a headless fashion. Agents won’t be using your UI, they’ll be talking to your APIs.
So the question becomes what is the business model of software and this headless approach in the future?
Here are a few thoughts on how everything plays out based on what we’re seeing and doing at Box, but also conversation with other platforms.
1) Seats don’t go away for *people*. Seats are still a convenient and efficient way to have a customer use technology predictably for a set of users within a baseline set of usage. The key, though, is that when the customer pays for a seat, it has to come with a set of usage of APIs on behalf of that user that the agent can use on their behalf.
The user will need to be able to interact with their data and the underlying tool via any agent they work with, and an embedded amount of usage will come with the seat. I would imagine most software -Box included- will enable seats to work with their data at a relatively high volume via systems like ChatGPT, Codex, Claude, Gemini, Cursor, Copilot, Perplexity, Factory, Cogniton, et al. quite seamlessly. If you don’t do this, you’re DOA.
2) Agents may have “seats” if they are doing stateful work in the system, but they will be priced very differently than people. Seats (or the equivalent) can make sense when you have an agent that has its own workspace, stores its own data, needs a different set of permissions compared to the user, and so on.
If a company wants this agent to be around for long period of time, that may very well look like another “user” in the system. Openclaw-style agents highlight what this future could look like.
The only issue on pricing here is that one customer could decide to do all their work in 1 agent, and another might split it into 1,000 agents. So pricing like a human seat is nearly impossible and impractical; each company will have a different approach for this as it gets tricky perfectly trying to capture all the value within an agent seat.
3) The dominant pricing for headless use that goes above the seat allotment, or when an agent is firmly acting on their own, will be a consumption model. Many enterprises software platforms have previously operated like this with PaaS options, and agents will look like another machine user of their system.
In some cases the APIs might get priced just as they did previously, but in other cases there may need to be new types of APIs that represent the work an agent would do in one go -more akin to an outcome- instead of a series of API calls. This is especially germane when the headless software also has an agentic use-case embedded within in, such as orchestrating the process within their own system via AI.
Overall the growth of this usage pattern is effectively unbounded as the use-cases for agents operating on data in these systems will dramatically exceed what people do with their data and tools today. Every platform that goes headless (which will be anyone that wants to take advantage of agents) will need to adopt a model like this. Some may fight it initially but it’s an inevitably as there will always be more and more agents outside your platform than people.
Overall, there’s a lot of really interesting changes left to come in software due to headless use of these systems. Early days.
100% agree and to me this makes the massive investments in inference compute infrastructure and datacenters a super strange bet when more than half of all inference may be done on-device.
Hard to predict of course but when hundreds of B$ are in the balance it's a tough one.
This is a glimpse of big changes ahead of us. If you’re betting on big central models you should think twice.
I run the exact same setup (M5 MacBook, qwen3.6-27B, pi, ollama) and while its not as fast or good as one of the big central models, it’s past the line of “cool demo” into “truly useful.” Kind of where the big frontier models were in late 2025.
In ~24 months we might have local models that are fast and good enough for most tasks.
The scariest finding in this paper: the subjects couldn't tell it was happening.
UPenn ran this study on 48 healthy adults. One group slept 8 hours. Another slept 6. Another slept 4. For 14 straight days. They tested cognitive performance every 2 hours from 7:30am to 11:30pm.
The 6-hour group's reaction times, working memory, and sustained attention deteriorated on a near-linear curve. By day 14 they were performing at the same level as someone who hadn't slept at all in 48 hours. The 4-hour group hit that threshold by day 6.
Here's the part that should unsettle everyone who thinks they "do fine" on 6 hours: the subjects' self-reported sleepiness flatlined after the first few days. Their brains kept getting worse. Their perception of how impaired they were stopped updating. The cognitive decline was invisible to the person experiencing it.
The researchers found a hard threshold. Any wakefulness beyond 15.84 hours in a day produces cumulative neurobiological cost. That cost compounds every single day you exceed it and does not reset with a weekend of sleeping in.
About 35% of American adults sleep less than 7 hours a night. 40% of those get 6 hours or less. In 1942 that number was 11%. We built an entire professional culture around a sleep schedule that this paper says is functionally equivalent to pulling consecutive all-nighters.
"I'm fine on 6 hours" is the most common response to sleep research. The first thing chronic sleep debt destroys is your ability to notice chronic sleep debt.
Parenting is like a never ending Easter egg hunt, but with cheerios.
I think my MTBC (mean time between cheerios) has averaged under 15min today. They just keep popping up everywhere 😆
As OpenAI and Anthropic continue to eat up the software development ecosystem, the next step will be for them to acquire and own where+how those applications are hosted.
We’re excited to share that Traversal has expanded its leadership team with six senior hires across go-to-market and engineering.
Over the past two years, Traversal has moved through three phases: research → validation → production proof.
What began as an applied AI research effort is now running inside some of the most demanding Fortune 100 environments in the world — including Pepsi, Amex, and DigitalOcean — investigating real incidents across petabyte-scale telemetry.
As adoption accelerated, it became clear it was time to scale the team.
Collectively, these leaders bring experience from companies that helped define the observability ecosystem — including Cribl, AppDynamics, Splunk, Google, and Redis.
They’ve seen firsthand how complexity and telemetry are outpacing human operability — and why reliability increasingly requires a rigorous AI-first approach. That conviction is what brought them to Traversal.
We’re excited for this next phase of scaling together.
Read more about the expanded leadership team: https://t.co/9KciL7Di9B
What F1 needs are the sounds of F3 and the drama of F2. We'll see how the season unfolds but onboards are even more boring to watch than ever with the new regs.
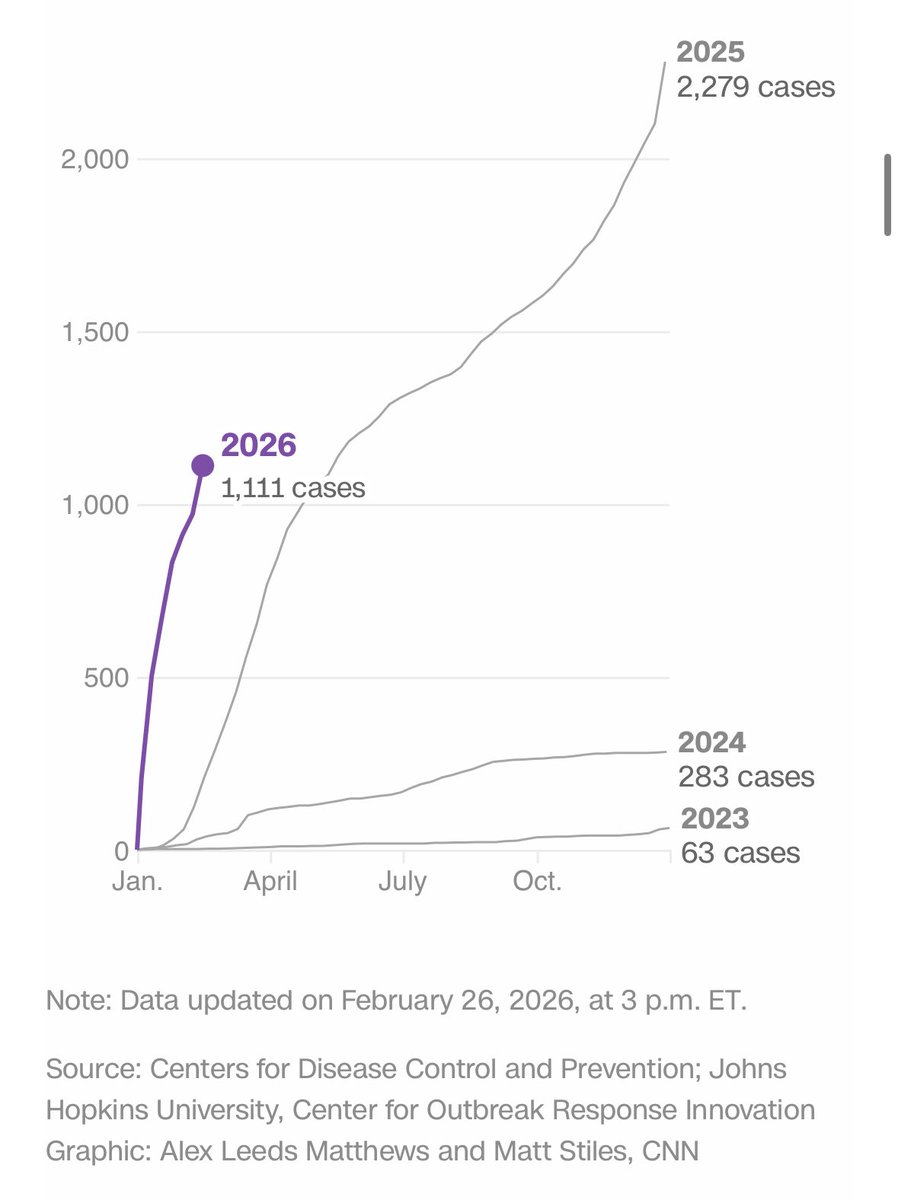
We are now at 1136 new measles cases - in just the first 8 weeks of this year alone.
A preventable disease resurging.
This is an abject policy failure.
👇🏼 The speed and scale at which this happened - it wasn't working before December, and now it's basically the default way to work - is part of what makes it the most exciting times in our careers. And if AI is expected to accelerate many things even further, ... 🤯
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
Everything we're doing to make codebases "agent-ready" (better docs, less dead code, smaller surfaces) engineers always needed too. Agents just have zero tolerance for the entropy humans learned to work around. They can't "just know" a file is outdated or a code path is dead. They take your codebase at face value, which means it finally has to be worth taking at face value.