@simonw Yes, but does it really accomplish teach junior devs the core skill of software engineering or just prompt engineering? Most of the stuff the agent does will no doubt be hidden.
Maybe that's all that matters in the future...but it's not the intention Tobi stated as motivation.
@tobi What I'd still worry is happening that employees (especially more junior ones) are learning prompt engineering vs the skills to debug an issue sans-agent.
Maybe we're racing to the day where that's more important anyway...but does still feel like we're losing something.
@garrytan Tough to say whether MCP wins long term. ❤️ an open protocol + really ❤️ that Anthropic added "embedded apps" vs the OpenAI closed-ecosystem approach. Open standards often have a way of winning.
That said, https://t.co/mrLTVakAjj has solved auth and ctx w/ MCP via search 😎
@linear I just lost 2hrs of work preparing a project with milestones. Hit save and an API error nuked everything. Please tell me you have a way to fix this.
This is notable: Opus 4.5 is ~60% more expensive than Sonnet ($25/million output compared to $15/million) but if it can use 76% fewer output reasoning tokens for the same complex task it may end up cheaper!
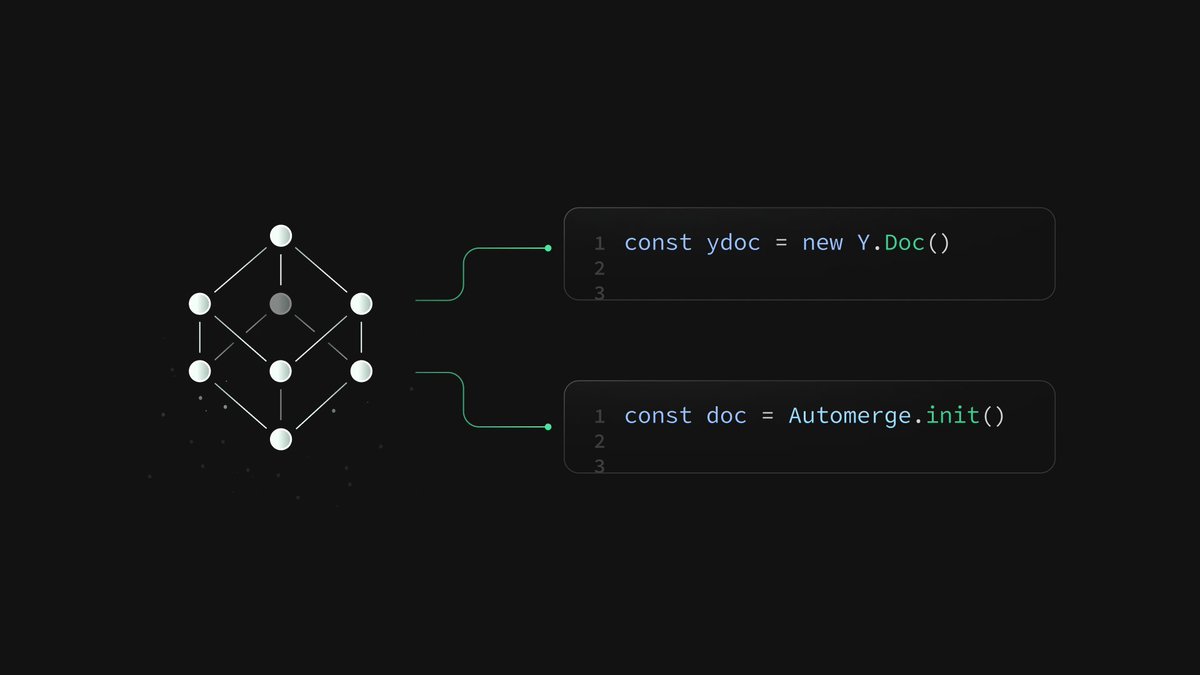
we've released a CRDT extension for Postgres (experimental and open source)
why? A CRDT is a special data type used for collaboration - think of a Google Doc. The changes are merged even as people are typing simultaneously
these CRDTs are then serialized on a server and then stored in a database.
with a Postgres extension, we give the database a more "native" experience - they can be merged on the database, indexed, and searched.
In the future you should be able to do something like this:
create table blog_posts (
id uuid primary key,
title text,
body crdt default '{}'
);
then you can post the changes to the database and it will merge automatically (rather than overwriting eachother's changes)
you can use websockets (like our Realtime server) for very rapid changes between users, batching the changes to your database
@mitsuhiko We're users of LangGraph on the backend and Vercel AI SDK on the frontend. There's a surprising amount of glue still needed when you get into the most complex interaction patterns (e.g. human-in-the-loop, streaming cancellation/resumption, message forking, etc.)
Observing some people close to me with chronic health conditions, it's striking how useful Reddit frequently ends up being. I think a core reason is because trials aren’t run for a lot of things, and Reddit provides a kind of emergent intelligence that sits between that which any single physician can marshal and the full rigor of clinical trials.
Why aren’t trials run for a lot of things? Well, they’re of course slow and expensive (median cost of $19M for a pivotal trial in 2015[1]; after adjusting for inflation and other phases, maybe that corresponds to a total of $40M today?). But they’re also hard to fund when the intervention in question lacks IP protection since the ensuing knowledge can’t be monetized. As such, trials for diet, over-the-counter supplements, and lifestyle interventions are under-pursued. To give one prosaic example, lots of people think that magnesium improves sleep, but, as far as I know, no trial has ever been run assessing its ability to improve sleep in non-elderly adults without sleep disorders.
So, Reddit — in a pretty unstructured way — makes a limited kind of “compounding knowledge” possible. Best practices can be noticed and can imperfectly start to accumulate. For people with chronic health problems, this is a big deal, and I’ve heard lots of stories between “I found something that made my condition much more manageable” all the way to “I found a permanent cure in a weird comment buried deep in a thread”. (Of course, one also sees this outside of medical conditions. I’ve enjoyed the recommended routine in the BodyWeightFitness subreddit, as a comparable kind of distilled practical wisdom[2].)
An interesting and somewhat more formalized example of this approach was recently used for long COVID and published earlier this year[3]. After surveying 3,900 individuals, the paper analyzes patient-reported outcomes for 150 different treatments, yielding the figure reproduced below. There are evidently no silver bullets, but it is striking that, say, about half of people find that antihistamines are helpful. I know a number of people who found the learnings from this study to be impactful in improving their daily quality-of-life.
Seeing this paper and the Reddit experience makes me wonder whether the approach could somehow be scaled: is there a kind of observational, self-reported clinical trial that could sit between Reddit and these manual approaches? Should there be a platform that covers all major chronic conditions, administers ongoing surveys, and tracks longitudinal outcomes?
I don’t really know what the best way to go about this would be, but it feels to me that there could be something important here. There’s a lot of latent data in patients’ subjective experiences that is not today being properly gathered or analyzed.
@sama If we're close to AGI, why is OpenAI:
1. Releasing fine-tuned models that are good at domain-specific tasks (Canvas, Creative Writing, etc.) vs better at general purpose.
2. Releasing new models (GPT 4.5) that are no where near 10x better than previous models






















![patrickc's tweet photo. Observing some people close to me with chronic health conditions, it's striking how useful Reddit frequently ends up being. I think a core reason is because trials aren’t run for a lot of things, and Reddit provides a kind of emergent intelligence that sits between that which any single physician can marshal and the full rigor of clinical trials.
Why aren’t trials run for a lot of things? Well, they’re of course slow and expensive (median cost of $19M for a pivotal trial in 2015[1]; after adjusting for inflation and other phases, maybe that corresponds to a total of $40M today?). But they’re also hard to fund when the intervention in question lacks IP protection since the ensuing knowledge can’t be monetized. As such, trials for diet, over-the-counter supplements, and lifestyle interventions are under-pursued. To give one prosaic example, lots of people think that magnesium improves sleep, but, as far as I know, no trial has ever been run assessing its ability to improve sleep in non-elderly adults without sleep disorders.
So, Reddit — in a pretty unstructured way — makes a limited kind of “compounding knowledge” possible. Best practices can be noticed and can imperfectly start to accumulate. For people with chronic health problems, this is a big deal, and I’ve heard lots of stories between “I found something that made my condition much more manageable” all the way to “I found a permanent cure in a weird comment buried deep in a thread”. (Of course, one also sees this outside of medical conditions. I’ve enjoyed the recommended routine in the BodyWeightFitness subreddit, as a comparable kind of distilled practical wisdom[2].)
An interesting and somewhat more formalized example of this approach was recently used for long COVID and published earlier this year[3]. After surveying 3,900 individuals, the paper analyzes patient-reported outcomes for 150 different treatments, yielding the figure reproduced below. There are evidently no silver bullets, but it is striking that, say, about half of people find that antihistamines are helpful. I know a number of people who found the learnings from this study to be impactful in improving their daily quality-of-life.
Seeing this paper and the Reddit experience makes me wonder whether the approach could somehow be scaled: is there a kind of observational, self-reported clinical trial that could sit between Reddit and these manual approaches? Should there be a platform that covers all major chronic conditions, administers ongoing surveys, and tracks longitudinal outcomes?
I don’t really know what the best way to go about this would be, but it feels to me that there could be something important here. There’s a lot of latent data in patients’ subjective experiences that is not today being properly gathered or analyzed.](https://pbs.twimg.com/media/G01qjOOawAAvKZw.jpg)






















