Time flies - six years ago I began co-organizing the ML in PL Conference, and in the blink of an eye we’ve just wrapped its 9th edition (next year golden anniversary!). What an incredible it’s been watching the event grow, evolve and bring together the ML community in Poland.
We are happy to share our v1 version of the temporal progress leaderboard (https://t.co/wD6s9uhGEf). Visual temporal reasoning is an essential characteristic that VLM/VLA should exhibit natively for proper data curation and adaptation for robotics tasks.
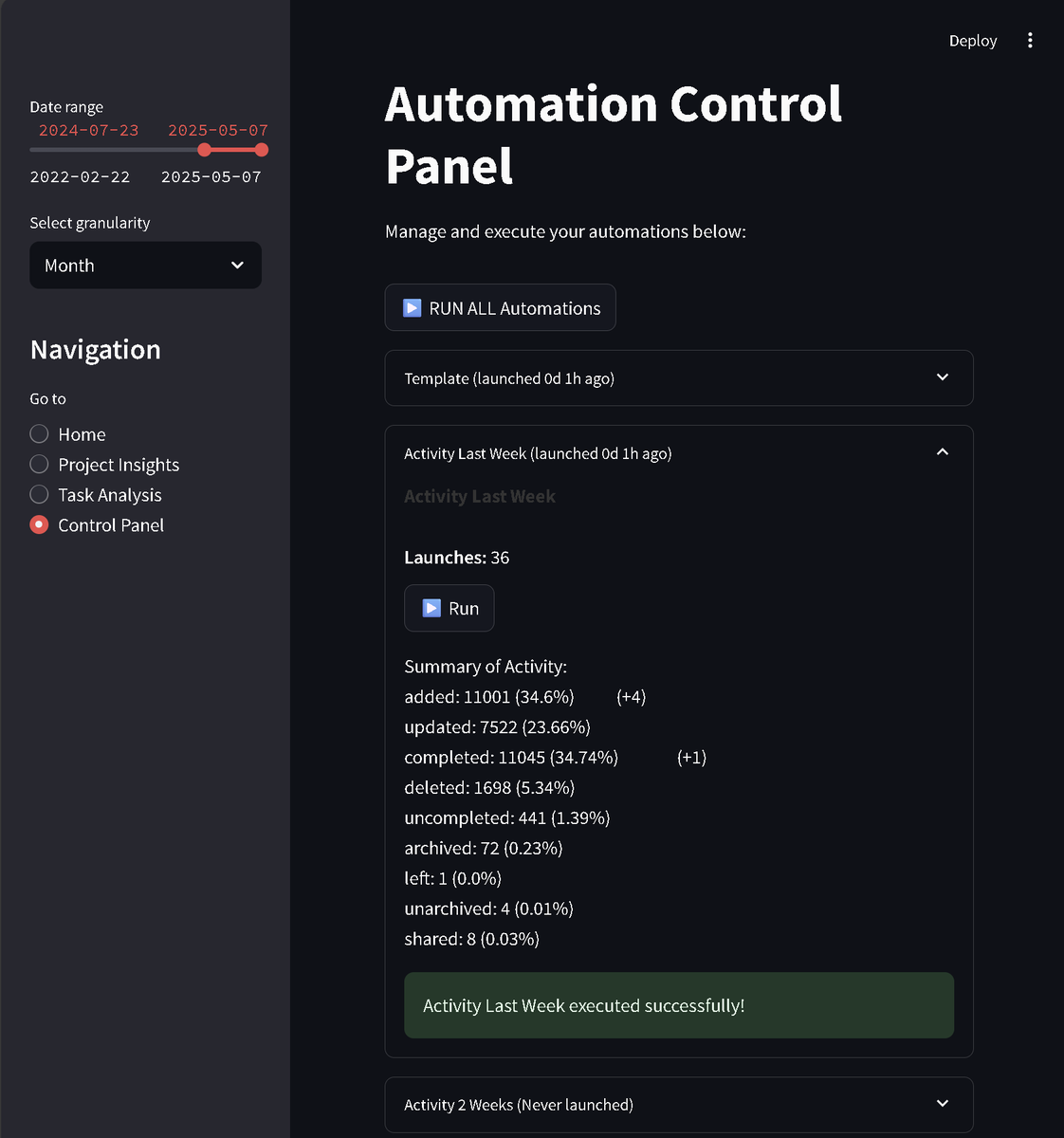
Built something as a hobby project cool for all the @todoist productivity enthusiasts: Todoist Assistant!
- Detailed analytics beyond default 4-week limit
- Automate repetitive tasks
- Python library for managingTodoist data
Screenshots in thread.
https://t.co/BgapEMl7xt
🚨Current scalable RL algos train a policy w/o value func, which is limiting with learning in open-ended, non-stationary, dynamic environments. But, how to scale value-based RL with more data/compute is unclear...
Not anymore: presenting scaling laws for value-based RL https://t.co/HiOIs6wf5P 🧵⬇️
Im więcej wiem na temat procesu wyboru nowego prezesa IDEAS NCBR, tym bardziej uważam, że w interesie publicznym jest transparentne wyjaśnienie kryteriów wyboru nowego prezesa. Poniższy list wysłałem do Premiera Donalda Tuska @donaldtuskEPP
🤖Can robots think through complex tasks step-by-step like language models?
We present Embodied Chain-of-Thought Reasoning (ECoT): enabling robots to reason about plans and actions for better performance🎯, interpretability🧐, and generalization🌎.
See https://t.co/jRkwpRZswZ.
Scaling has done wonders for deep learning, but for a long time it failed in on-policy RL... until now! We show that when done appropriately, scaling leads to state-of-the-art results in a variety of continuous control tasks🔥
Introducing BRO: Bigger, Regularized, Optimistic! 🧵
Our work on hierarchical search is in the ICLR workshop! Come chat with us at our poster session this Saturday on Generative Models for Decision Making workshop #ICLR2024
🚀Excited to share our latest work on fine-tuning RL models! By integrating fine-tuning with knowledge retention methods, we've achieved SOTA🔥in NetHack🎮, with scores surpassing 10K points, doubling the previous record. A detailed thread coming soon! ✨
🚀 Breaking News from Deepflare 🚀
Thrilled to highlight Deepflare's latest leap in cancer research using AI! Our innovative approach in immunotherapy is a step closer to a cancer-free world. 🌍
#CancerResearch#AIInHealthcare#Deepflare#Oncology
https://t.co/zBUykNj3MK
✨Announcing LongLLaMA-Code 7B!✨
Have you wondered how GPT3.5 obtained its capability?
Are base models of code better reasoners? 🤔
We continue pre-training CodeLLaMA on text & code to improve reasoning 🧠
Bonus: 3x faster inference @ 16K context, using Focused Transformer 🎯
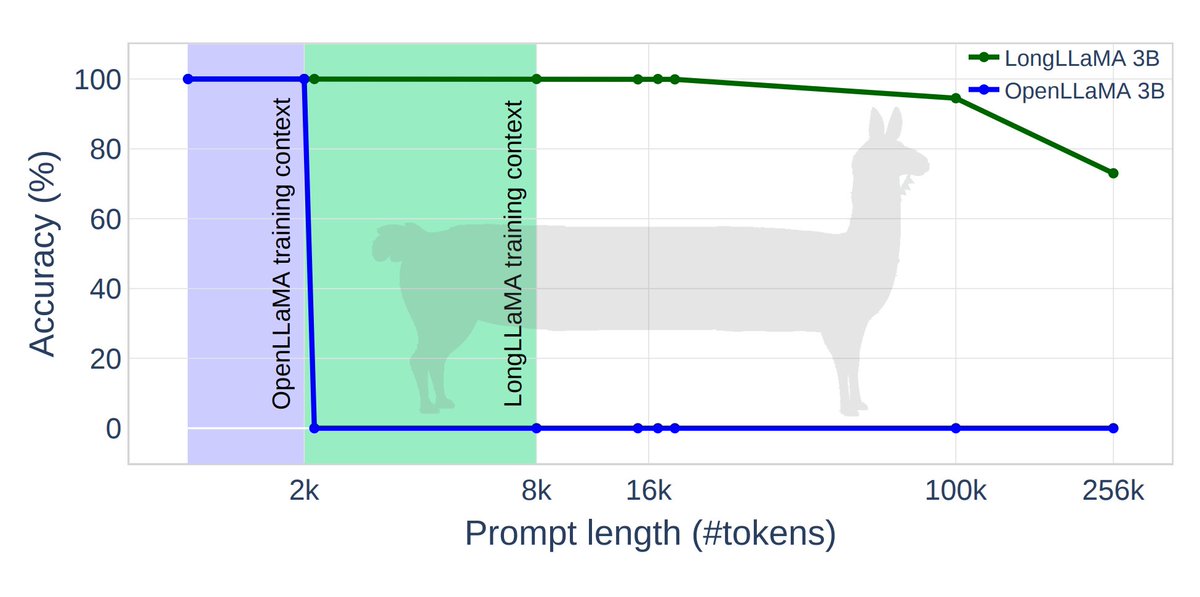
Introducing LongLLaMA 🦙, an unlimited-context version of OpenLLaMA fine-tuned at 8k & capable of extrapolating to 256k tokens!
We train it using our new Focused Transformer 🎯 technique (FoT). No degradation on short context, drop-in compatibility & Apache 2.0 license 🔥🔥
🧵
🎇Introducing *nanoT5 v2*🎇
Inspired by @karpathy 's #nanoGPT, we improve the repo for pre-training T5 model in PyTorch.
In ~16 hours on a single GPU, we achieve 40.7 RougeL on the SNI benchmark, compared to 40.9 RougeL of the original model pre-trained on 150x more data!
What is the best way to quickly learn to tell apart complex classes that are encountered one after the other?
@Michal_Zajac_ found the best approach might just be learning a random mapping for each class!👇
https://t.co/nNQ6q3hZzF
[MATH-AI influencer mode on]
Decomposing the Enigma: Subgoal-based Demonstration Learning for Formal Theorem Proving
https://t.co/GkvZCuGZWu
New miniF2F SoTA test: 45.5%
The paper seems to follow Draft, Sketch, and Prove but they found a better way to do formal sketches!



























![AlbertQJiang's tweet photo. [MATH-AI influencer mode on]
Decomposing the Enigma: Subgoal-based Demonstration Learning for Formal Theorem Proving
https://t.co/GkvZCuGZWu
New miniF2F SoTA test: 45.5%
The paper seems to follow Draft, Sketch, and Prove but they found a better way to do formal sketches! https://t.co/SaLw0ORaOU](https://pbs.twimg.com/media/FxWYZY6acAIlCBy.jpg)





























