Two Anthropic engineers spent 24 minutes exposing every Claude Code feature you didn't know existed.
Most people will scroll past this. Don't be most people.
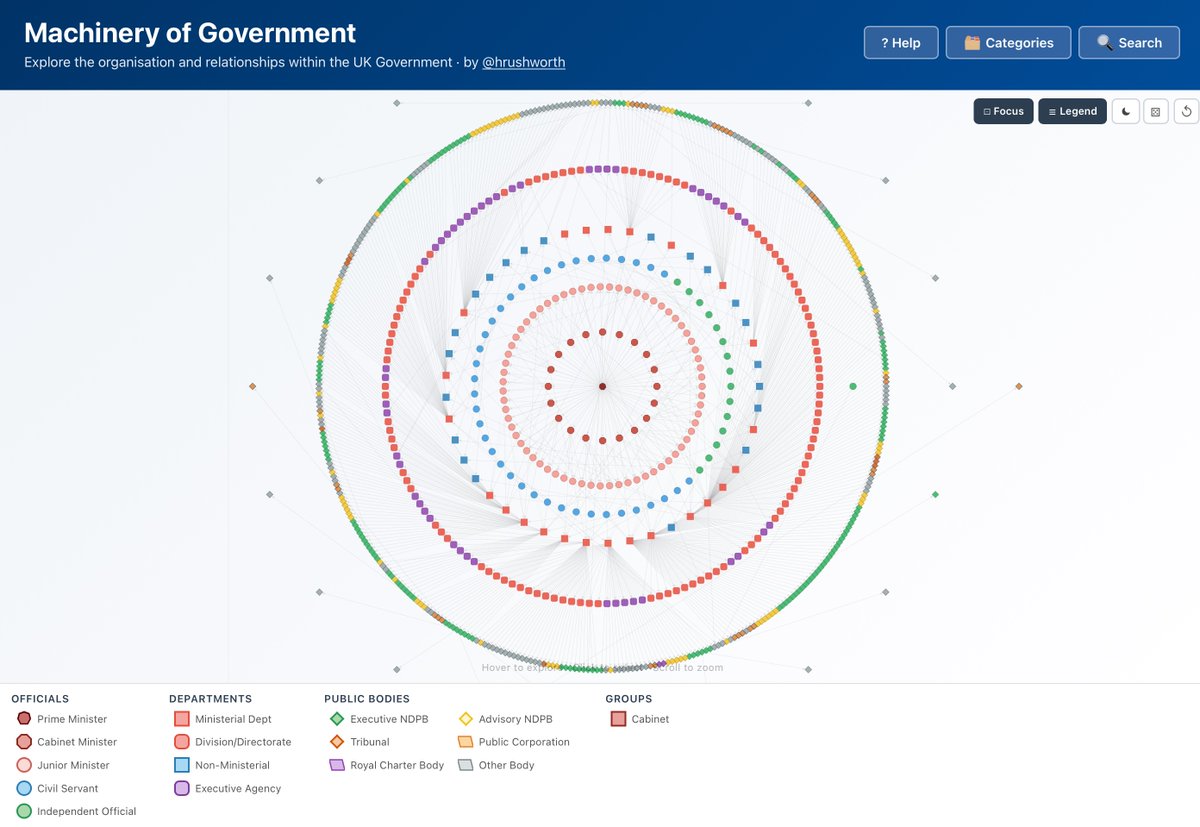
The British Government is a complicated beast. Dozens of departments, hundreds of public bodies, more corporations than one can count...
Such is its complexity that there isn't an org chart for it.
Well, there wasn't...
Introducing ⚙️Machinery of Government⚙️
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
1st high definition shots of VT-BWV now christened 'The Flying Canvas' featuring India’s first contemporary art aircraft wrap, created by Osheen Siva for @AirIndiaX.
It is part of a collaboration with the Kochi Biennale taking Indian contemporary art to the skies.
#AvGeek
I spent the last phase of my work exploring the 4 Vedas visually: Rigved, Samved, Yajurved, Atharvaved. I discovered that these are the source code to everything that grows into the Indian culture.
I didn’t expect covering the 4 Vedas to become its own visual universe, but it did. I welcome you to dive into that universe.
Defence startups working on national security technologies can apply to join an off-the-record discussion on tech, indigenisation, procurement, and deployment.
Apply here: https://t.co/cDUHktrQwV
Invitation only. Shortlisted startups will be contacted.
#PPPF2026
We are thrilled to share significant progress on our ambitious Artificial Intelligence (AI) and Large Language Model (LLM) development program for Sanskrit, which was officially inaugurated on Vijayadasami day this year.
The Core Mission and Team
A dedicated core group of professionals spanning IT, Data Science, and Sanskrit Studies is driving this effort to create the country's first truly capable Sanskrit LLM. Our foundational strategy is centered on developing a comprehensive, high-quality Sanskrit corpus.
Massive Data Corpus Development
Our initial focus has been on leveraging our institutional assets. Our combined libraries (College and KSRI) hold over 110,000 texts, scriptures (Śāstras), and several thousand manuscripts.
Initial Focus: We commenced the digitization process by converting scanned images of rare books and manuscripts into digital text.
Technological Breakthrough: Our in-house scholars successfully developed proprietary software to automate the conversion of PDF image data into editable text.
Proof of Concept Success: We successfully converted 180 volumes of the now discontinued 'Chandamama' magazine in Sanskrit, proving the efficiency of our automated workflow.
Scaling Up: Building on this success, we rapidly converted over 1,000 books into text in less than 24 hours, dramatically accelerating the corpus creation phase.
The Path Ahead: Curation and Modeling
We are now moving into the crucial validation and modeling stages:
Data Curation & Quality Control: We are actively recruiting part-time Sanskrit scholars to meticulously edit and curate the newly converted texts, ensuring accuracy and correcting any errors generated during the automated process. This step is vital for the model's performance.
Next Phase: The curated and verified data will then be prepared—through tokenization—and fed into our proprietary AI model for training.
🤝 Join Us in Making History
This is a massive, pioneering effort, and we invite skilled individuals to contribute. If you have expertise in Sanskrit, Linguistics, and/or Data Science, we welcome you to join our team.
DM us today to become part of this unique exercise. Together, we aim to make history by developing the first comprehensive AI-LLM for Sanskrit in the country, unlocking the potential of this ancient language for the digital age.
@dpradhanbjp@SanjeevSanskrit@MaharishiAazaad@sain57356@SanskritChannel
#SanskritDiwas
@davidfrawleyved@sanskritiias
@TheSanskriti_
@kalyan97@annamalai_k@yajnadevam@Rtam86418021@SanjeevSanskrit@Kar_Sas123@subhash_kak@AGeorge56445@AkhilKumarSaho8@vikramsampath@DeepakChopra@jsaideepak@itisatp@BjpSashi@PMOIndia@DrManishKumar1@ARanganathan72@sanjeevsanyal@kalyan97@dushyanthsridar@RajVedam1@mmpandit@periyanatt96807@Ugrashravas
‘Bhairav’ the Indian community dog , a street dog walked 5 states alongside the Ayyappa devotees. 🙏
He walked a 1000 kilometres and completed the Maha Padayatra. 🙏
From Telengana to Kerala.
These Indian street dogs have always been part of our religion , our culture.
They have been a part of the landscape as much as we are.
Let’s do better by them by controlling their population through well-run & efficient Animal Birth Control programs , by adopting them , by feeding and taking care of them on the streets even.
They deserve to exist in dignity , to be loved & cared for, to be homed @RSSorg@narendramodi@myogiadityanath.
This world is not for the humans alone & those shelters are nothing but DEATH TRAPS Honourable Supreme Court of India.
🚨Question the humans too who leave their children alone on the streets , a 1000 go missing a day , 1 child every 8 seconds in India never to be found again.
https://t.co/LzfN3WuCPr
@yadavnarender85@joedelhi@sanjay_daddy@ShrijeetNair06@avc_201@Seekr_of_Truth@Dr_Vee_20@JesudossAsher@PercyBillimoria
Additional "Christmath Trees," to enjoy the holiday spirit.
By Daniel Mentrard, @dment37, Used with permission, https://t.co/wmBJkivd3z [math, maths, mathematics]
These are just 2 Keyframes.
#AI did the rest.
@cascadeur3d just released an impressive update that adds to the AI interpolation features that run locally on your PC 🤯.
I am not an animator but creating a walk cycle took me literally 20 seconds... and the majority of that time was spent understanding how to add a new keyframe.







































![pickover's tweet photo. Additional "Christmath Trees," to enjoy the holiday spirit.
By Daniel Mentrard, @dment37, Used with permission, https://t.co/wmBJkivd3z [math, maths, mathematics] https://t.co/Wv1Mq6aFiN](https://pbs.twimg.com/media/G75Nc3MWoAA9CYA.jpg)



















