@deepseek_ai@AlibabaGroup@crystalsssup Okay okay, due to reasonable feedback we added:
@cohere for their non commercial models
@ServiceNow with Apriel, I like folks there (and pipeline rl)
Motif
@tngtech as a shout out for awesome hacks and merges of big MoEs
This is DEFINITELY right, no take backs
G1PO, our @UnitreeRobotics humanoid robot, was in a playful showrace against the Munich @Motorworld_de's #GT3RS. Of course, he still got helping hands from his human friends to steer him and thus the kart. @Porsche cars and TNG managers narrowly escaped, and the oil drums got only slightly bumped (yt link in reply ;-).
News from the Aider discord regarding DeepSeek-TNG R1T2 Chimera's performance in the Aider Polyglot benchmark, courtesy of benchmark wizard neolithic5452 and the magic @UnslothAI quantizations:
- 2 bit UD-IQ2_M: 60.0%
- 4 bit Q4_K_XL: 62.7%
- 8 bit: 64.4%
This seems to be the second highest open-weights result, after @deepseek_ai's R1-0528 which scored 71.4%. It appears to be before Kimi K2 (59.1%) and also @Alibaba_Qwen's Coder-480B, which scored 60.9% in the 4 bit UD-Q4_K_XL version.
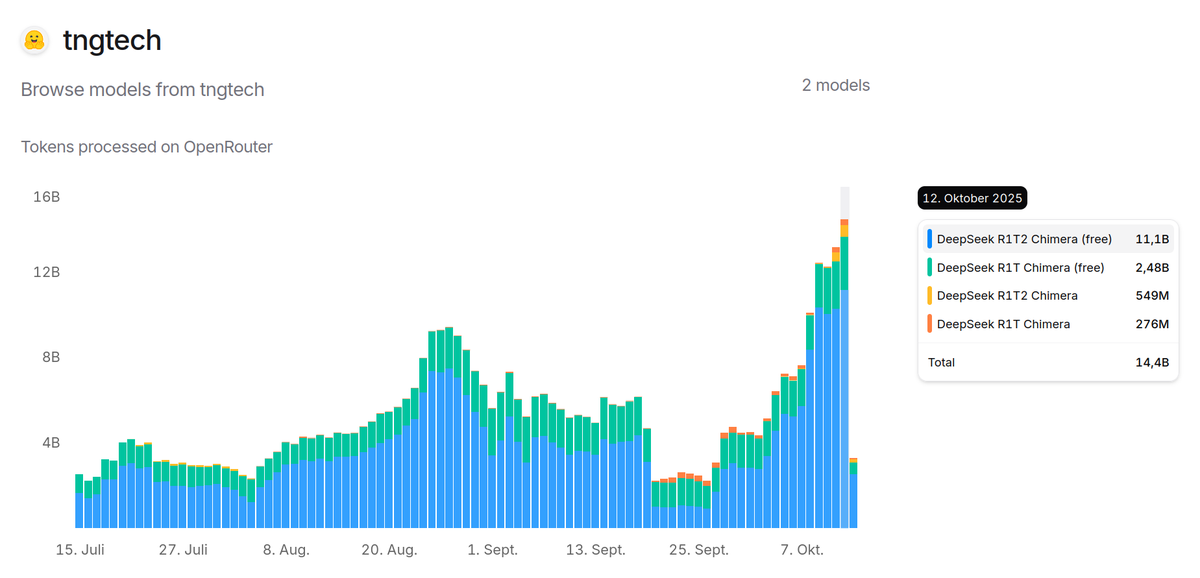
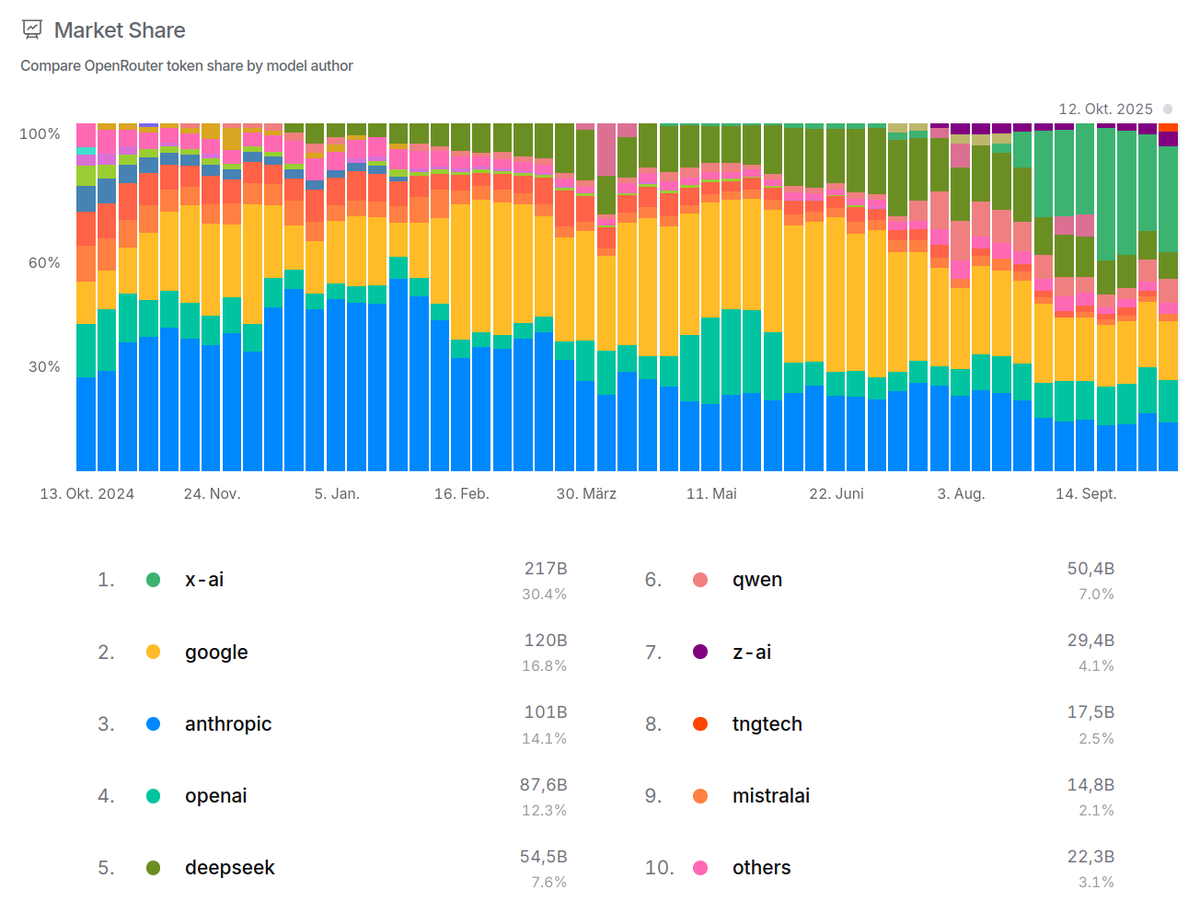
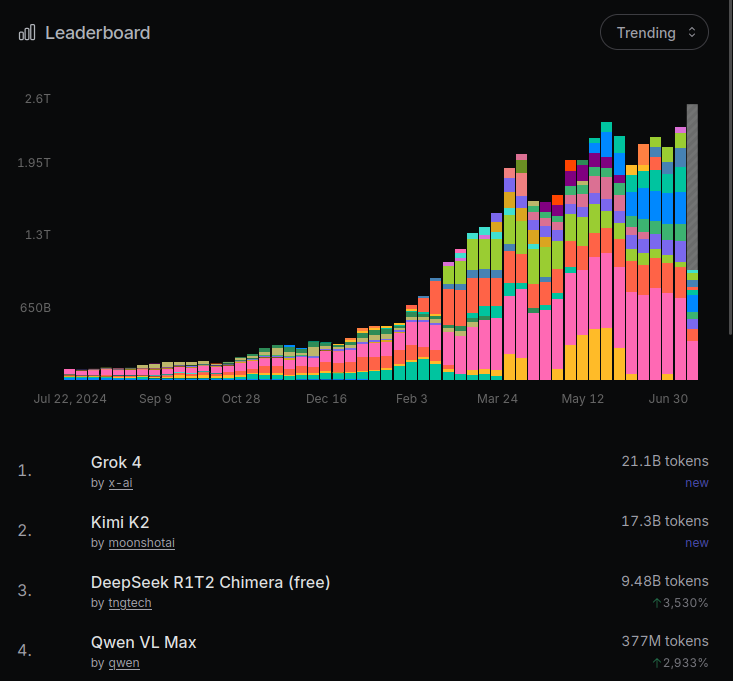
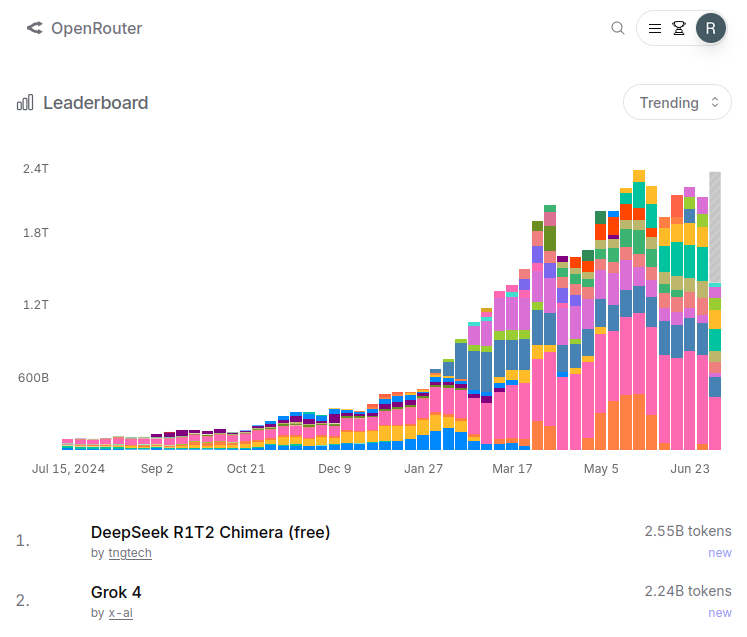
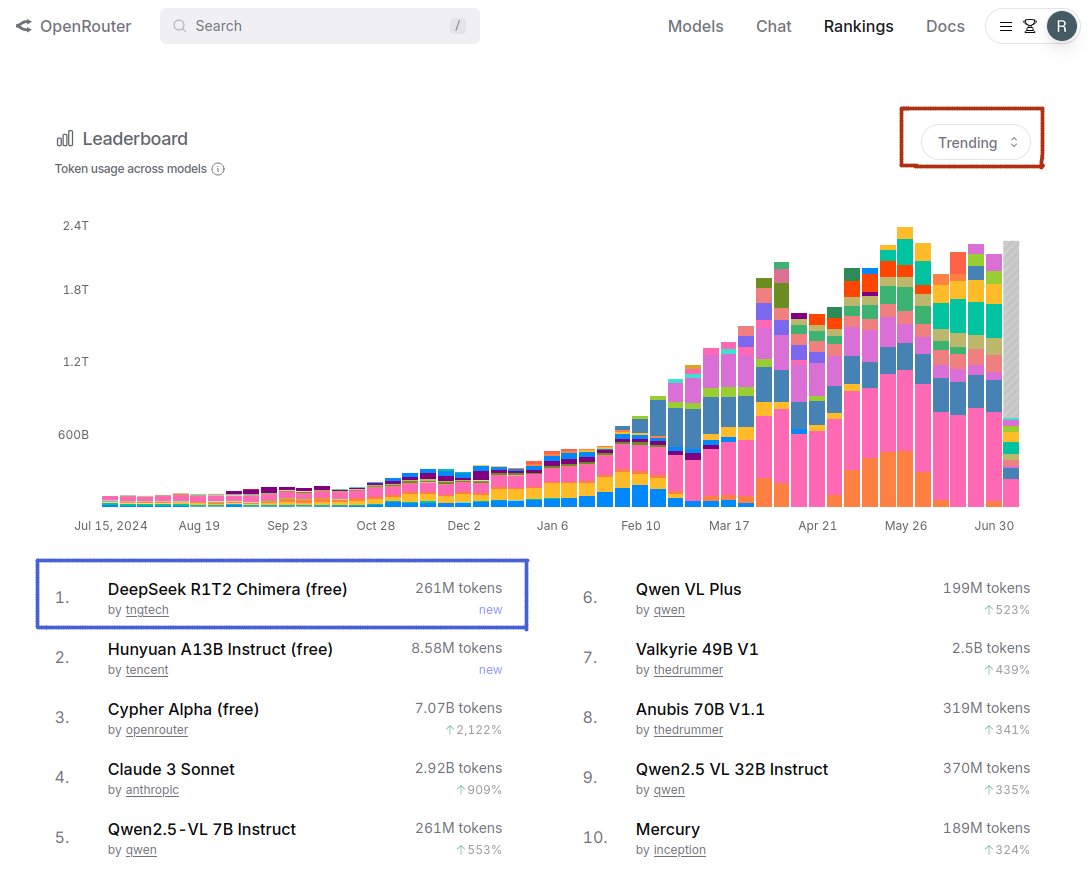
On @openrouter, R1T2 currently is the 11th most popular model for Aider. Over all applications, R1T2 processed 3.12B tokens yesterday on OR. On @chutes_ai, as of today is the tenth-most popular model.
Today we release DeepSeek-TNG R1T2 Chimera.
This new Chimera is a Tri-Mind Assembly-of-Experts model with three parents, namely R1-0528, R1 and V3-0324.
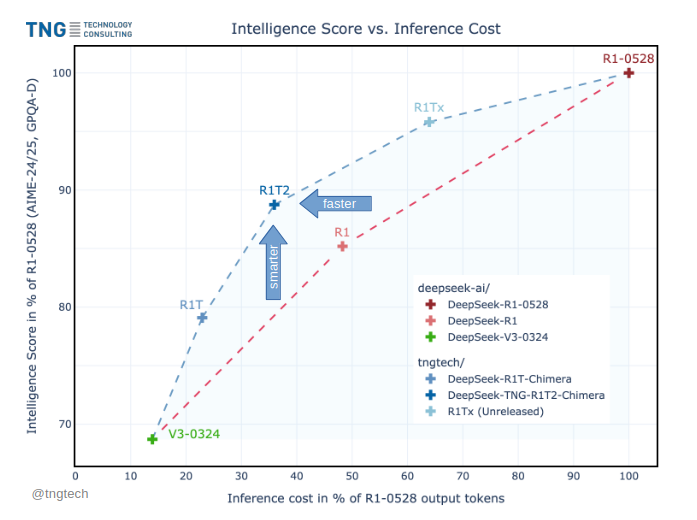
R1T2 operates at a sweet spot in intelligence vs. output token length. It appears to be...
* about 20% faster than R1, and more than twice as fast as R1-0528
* significantly more intelligent than R1 in benchmarks such as GPQA Diamond and AIME-24/25, albeit not quite on R1-0528 level
* much more intelligent than our first R1T Chimera, and also think-token consistent, which is a major improvement
We perceive it as generally well-behaved and a nice persona to talk to. The weights are on @huggingface under the MIT licence. We are looking forward to your experiments and feedback!
Thanks to @deepseek_ai for giving their models to the world, to @chutes_ai and @openrouter for hosting R1T, to @WolframRvnwlf for benchmarking it, to @xlr8harder for beta-testing the new Chimera, and to @natolambert for constructive discussions at @aiDotEngineer.
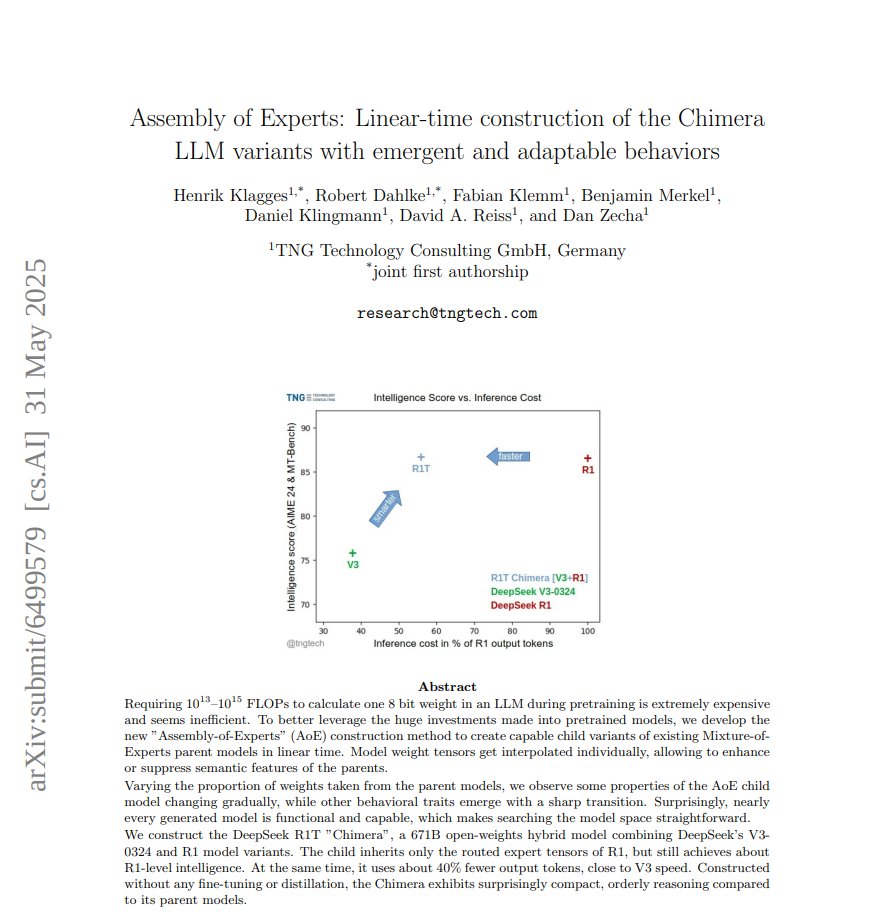
We post our new paper "Assembly of Experts: Linear-time construction of the Chimera LLM variants with emergent and adaptable behaviors" on @huggingface, while waiting for @arxiv.
We explain how we constructed the 671B R1T Chimera child model from the great @deepseek_ai V3-0324 and R1 parent models (谢谢!) in less than one hour of CPU time.
The Chimera research prototype is currently the 4th most-popular LLM on @chutes_ai with about 3.5B tokens/day, 0.9-1.0B of which flow through @openrouter. Over 160B tokens have been processed since release on April 26th.
Assembly of Experts: Our linear-time 671B Chimera LLM construction paper should soon appear on https://t.co/dVojsu26Pb.
We are at the @aiDotEngineer fair in SFO until tomorrow, so for a chat -> DM ;-)
More evidence for the effectiveness of the Chimera construction method:
Taking DeepSeek's R1-0528 release, we started benchmarking new Chimera variants on AIME-24 and SimpleQA.
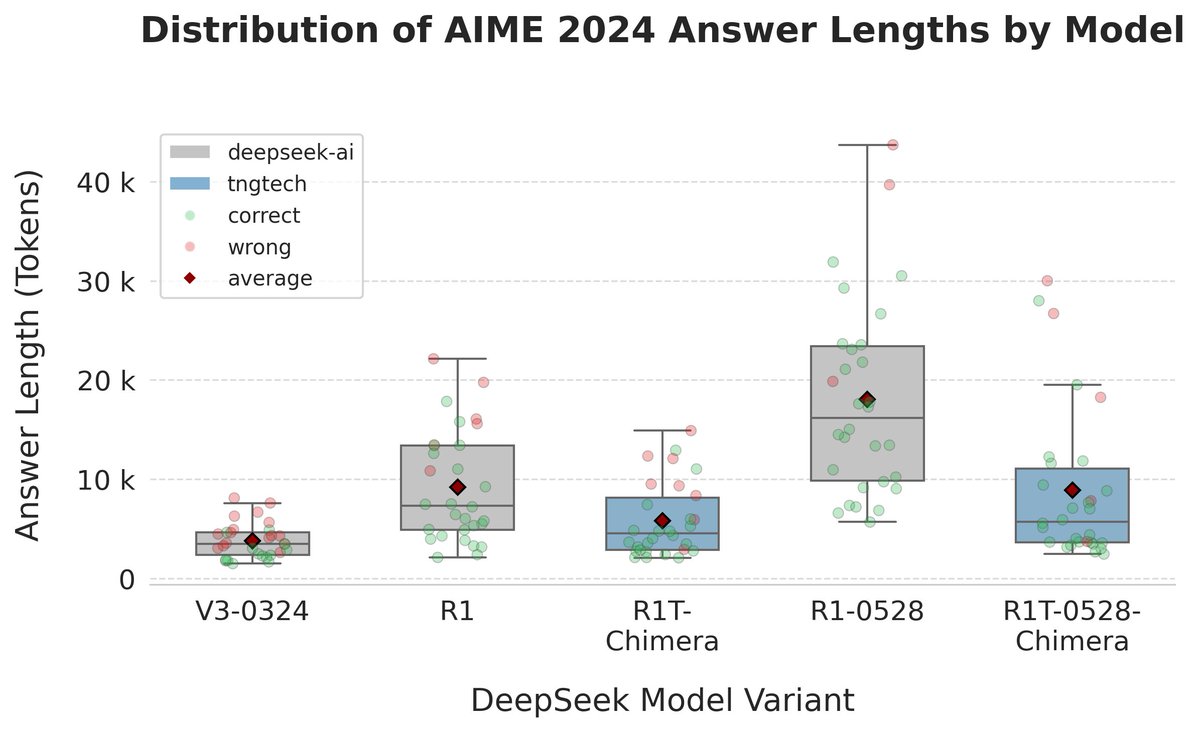
R1-0528 significantly improves AIME performance from 79.8 to 91.4 while doubling the amount of output tokens compared to R1. It appears to be a great model overall.
Our R1-0528-Chimera variants of R1-0528 and V3-0324 seem to improve math performance too, with results up to 83.3. Positive aspect: more compact reasoning with output-token count below that of R1. This could be an interesting trade-off for real-world applications.
On SimpleQA R1T-0528-Chimera is close to the V3-0328 results and seems to fare better than R1-0528.
Caveat: these numbers are just a preliminary indicator, since they stem from single benchmark runs and are subject to statistical fluctuation.
We'll continue searching for variants with interesting features and beneficial behavior combinations
Having a blast in beautiful Estes Park, CO. It was a real pleasure sharing my perspective on how LLMs are transforming software engineering, and why running your own GPU stack can be a game-changer. Thanks to everyone who came with smart questions and big ideas! #LambdaConf2025