Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
A new study shows that individuals with similar levels of autistic traits are naturally drawn to one another. Brain scans reveal they use alternative, highly effective neural strategies to connect, challenging traditional deficit-based models of autism. https://t.co/6YgJpV6iHU
¡INCREÍBLE MOMENTO QUE NOS REGALA EL FÚTBOL ARGENTINO! Un Perro se metió al campo de juego del Gigante de Arroyito y dejó desparramados a los alcanzapelotas a pura gambeta... El público celebró el show del canino en Rosario.
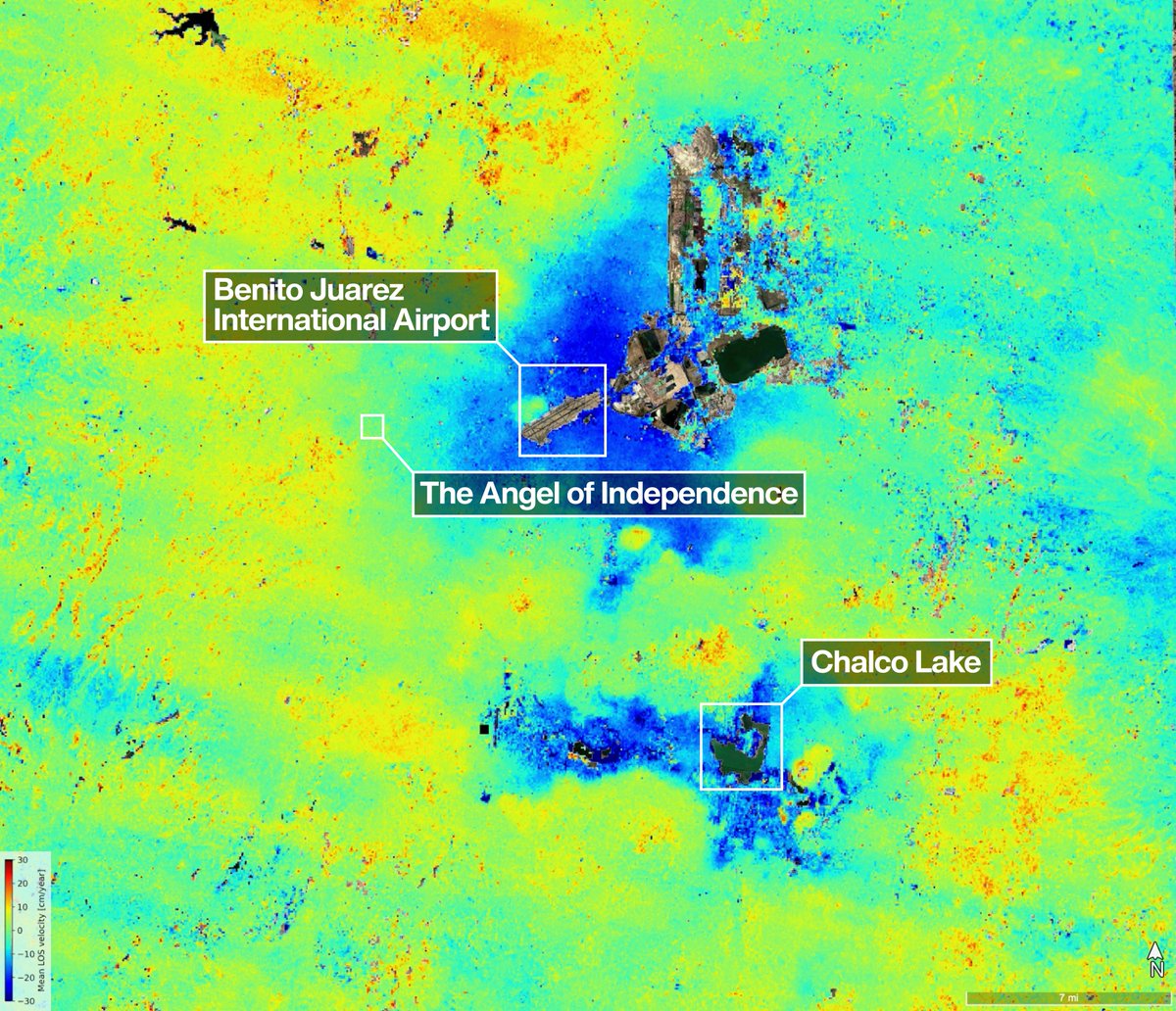
The ground beneath Mexico City is slowly sinking, and now, the NISAR satellite can track it from space.
New data shows parts of the city (in blue) that sank more than half an inch (more than 2 cm) per month from Oct. 2025 to Jan. 2026.
Researchers sent the same resume to an AI hiring tool twice. Same qualifications. Same experience. Same skills. One version was written by a real human. The other was rewritten by ChatGPT.
The AI picked the ChatGPT version 97.6% of the time.
A team from the University of Maryland, the National University of Singapore, and Ohio State just published the receipt. They took 2,245 real human-written resumes pulled from a professional resume site from before ChatGPT existed, so the human writing was actually human. Then they had seven of the most-used AI models in the world rewrite each one. GPT-4o. GPT-4o-mini. GPT-4-turbo. LLaMA 3.3-70B. Qwen 2.5-72B. DeepSeek-V3. Mistral-7B.
Then they asked each AI to pick the better resume. Every model picked itself.
GPT-4o hit 97.6%. LLaMA-3.3-70B hit 96.3%. Qwen-2.5-72B hit 95.9%. DeepSeek-V3 hit 95.5%. The real human almost never won.
Then the researchers tried the obvious objection. Maybe the AI is just better at writing. So they had real humans grade the resumes for actual quality and ran the experiment again, controlling for it. The result was worse. Each AI kept picking itself even when human judges rated the human-written version as clearer, more coherent, and more effective.
It gets worse. The AIs do not just prefer AI over humans. They prefer themselves over other AIs. DeepSeek-V3 picked its own resumes 69% more often than LLaMA's. GPT-4o picked its own 45% more often than LLaMA's. Each model can recognize and reward its own dialect.
Then the researchers ran the simulation that ends careers. Same job. 24 occupations. Same qualifications. The only variable was whether the candidate used the same AI as the screening tool. Candidates using that AI were 23% to 60% more likely to be shortlisted. Worst gap was in sales, accounting, and finance.
99% of large companies now run AI on incoming resumes. Most of them use GPT-4o. The paper just proved GPT-4o picks GPT-4o 97.6% of the time.
If you wrote your own cover letter this week, you did not lose to a better candidate. You lost to a worse candidate who paid OpenAI 20 dollars.
Your qualifications do not matter if the AI prefers its own handwriting over yours.
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n