Jane Street rejected this vibe-coder at $385K/year because he refused to use Claude Code
32-min of vibe coding RIGHT during an interview at a Tier 1 fund
you watch the entire process: live coding, pressure questions, the moment they realize his stack doesn't match theirs
every Tier-1 fund is now filtering candidates by tool stack. Claude Code is the new compliance
Bookmark & Watch tonight
Finally able to talk about what I've been heads-down on for 6 months at @nvidia 🦀⚡
We just open-sourced cuda-oxide — an experimental rustc backend that lets you write CUDA kernels in pure Rust.
No DSLs. No FFI. No source-to-source step. Single source.
Short🧵👇
Introducing Mirage, a unified virtual filesystem for AI agents!
6 weeks. 1.1M+ lines of code. We rewrote bash from the ground up so cat, grep, head, and pipes work across heterogeneous services. S3, Google Drive, Slack, Gmail, GitHub, Linear, Notion, Postgres, MongoDB, SSH, and more, all mounted side-by-side as one filesystem.
Bash that AI agents already know works on every format! cat, grep, head, and wc parse .parquet, .csv, .json, .h5, even .wav! One pipe can stitch S3, Drive, GitHub, Slack, and Linear together, same Unix semantics throughout.
Workspaces are versioned too. Snapshot, clone, and roll back the whole thing with one API call. A two-layer cache turns repeated reads into local lookups, so agent loops stay fast and cheap.
Drop a Workspace into FastAPI, Express, or a browser app. Wire it into OpenAI Agents SDK, Vercel AI SDK, LangChain, Mastra, or Pi. Run it alongside Claude Code and Codex.
Site: https://t.co/zo1orc2wA9
GitHub: https://t.co/zeRAKri7I9
#AIAgents #OpenSource #AgenticAI #Strukto #Filesystem #VFS
Every major AI shift started with a new kind of world model.
Language. Vision. Code.
The next one is physics.
@saucentoss and I published a paper today defining what a real foundation model for physics has to be and why it enables Continuous Physics Reasoning.
If AI is going to help build the physical world, the bar has to be much higher.
Link to full paper: https://t.co/koNrDxrQPU
Narrative violations abound:
- Demand for software engineers is rising
- Software devs are rising as a share of new jobs
- AI exposed industries are seeing above-trend wage growth
- Open PM jobs haven't been higher since 2022
More from a16z's David George on the "AI job apocalypse" myth: https://t.co/7sbadmEElG
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
Built clawsweeper, which runs 50 codex in parallel around the clock, scans issues/prs deep and closes what is already implemented or what makes no sense.
Closed around 4000 issues today, a few thousand are in the pipeline. (rate limits are rough) https://t.co/AiNNDcvGke
This 15-minute talk by the creator of Pydantic on how to correctly use MCPs will
teach you more about making your AI tools actually work together than everything you've scrolled past this year.
Bookmark this & watch, no matter what.
Then read the guide below by @eng_khairallah1
THIS IS HUGE. Bitcoin is Quantum-Safe TODAY.
Even if a quantum computer appeared, one that breaks the conventional Bitcion signatures, it shows a practical way to create safe Bitcoin transactions. WITH NO CHANGE TO BITCOIN PROTOCOL!!!
Most enterprise blockchain platforms plateau at 150 transactions per second. Cosmos ledgers sustain 1,900+ TPS and can be optimized to 10,000+.
We broke down how Cosmos and Hyperledger Fabric compare across performance, architecture, and use cases.
Read more below ⬇️
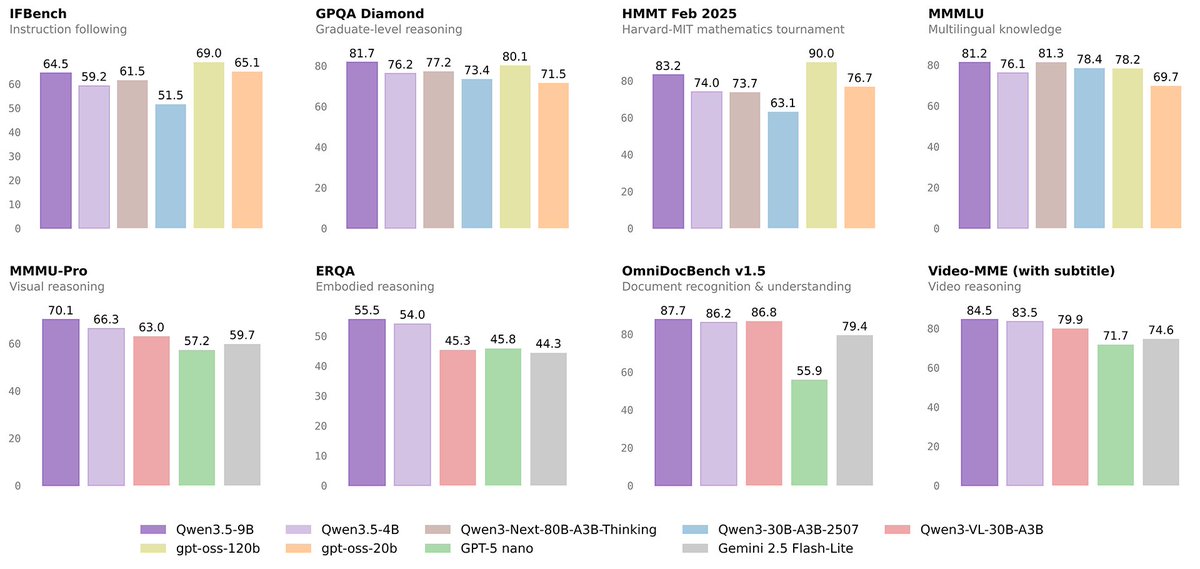
🚀 Introducing the Qwen 3.5 Small Model Series
Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
✨ More intelligence, less compute.
These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL:
• 0.8B / 2B → tiny, fast, great for edge device
• 4B → a surprisingly strong multimodal base for lightweight agents
• 9B → compact, but already closing the gap with much larger models
And yes — we’re also releasing the Base models as well.
We hope this better supports research, experimentation, and real-world industrial innovation.
Hugging Face: https://t.co/wFMdX5pDjU
ModelScope: https://t.co/9NGXcIdCWI
About 1/3 of the top technical CEOs are completely AGI pilled by coding again. I am one of them. Highly recommend.
Totally exhilarating to be back shipping new products and software again
Introducing EVMbench—a new benchmark that measures how well AI agents can detect, exploit, and patch high-severity smart contract vulnerabilities. https://t.co/op5zufgAGH
CLAUDE CODE but for HACKING
its called shannon, you point it at website and it just... tries to break in... fully autonomous with no human needed
i pointed it at a test app and it stole the entire user database, created admin accounts, and bypassed login, all by itself, in 90 minutes