TokenWeave – Efficient Compute-Communication Overlap for Distributed LLM Inference.
Why? Even with highspeed NVLink on H100 DGX, communication overhead for distributed LLM inference can be > 20 %! Can we recover this overhead? (1/10)
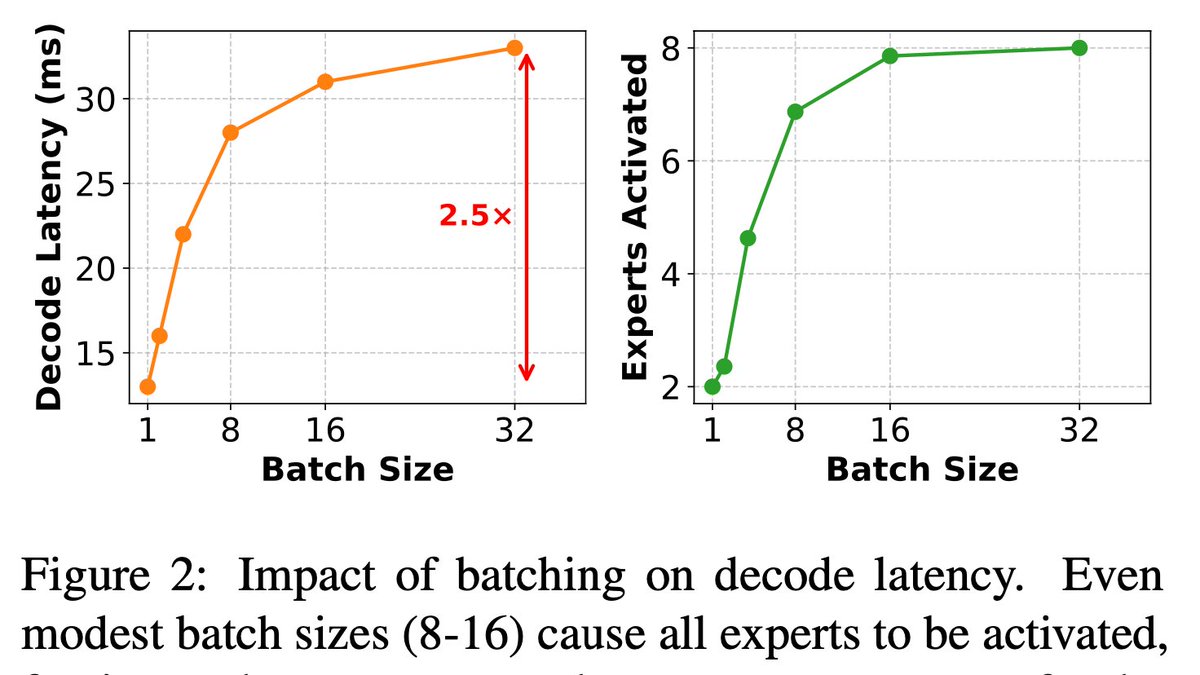
1/7 🧵 MoEs: A tale of expectation vs reality
Marketing: "Only compute the expert parameters you need!"
Reality: Batch 16 requests → ALL experts activate
At serving time (vLLM/TGI), arithmetic intensity:
AI ≈ (num_tokens * top_k) / total_experts
In simpler terms: Your decode arithmetic intensity scales inversely with expert count 🤔
#MoE #LLMs #ChatGPT #Claude #vllm #AI #ML
@Google has silently but surely developed an edge over @OpenAI. Long context processing seems to be the key to Google's AI strategy. NotebookLM is a prime example of what long context processing can unlock. In our latest paper, we talk about how systems can be built to support multi-million context length matching Google's capabilities. In case you missed the paper, here is the NotebookLM generated podcast!
Podcast: https://t.co/pnQfxV914S
Arxiv: https://t.co/i75NEz7h5F
Are you getting the performance you paid for from your LLM provider?
Benchmark it using Metron. It is one our biggest learning while working on LLM Inference for the last year at @MSFTResearch and @gtcomputing when we shipped Chunked Prefill at OSDI'24 and Vidur @MLSysConf.
🚀 Introducing Metron: Redefining LLM Serving Benchmarks! 📊
Tired of misleading metrics for LLM performance? Our new paper introduces a holistic framework that captures what really matters - the user experience! 🧠💬
https://t.co/Q02Fj0IUKa
#LLM#AI#Benchmark
Did you ever feel that @chatgpt is done generating your response and then suddenly a burst of tokens show up? This happens when the serving system is prioritizing someone else’s request before generating your response. But why? well to reduce cost. 🧵
[LG] Vidur: A Large-Scale Simulation Framework For LLM Inference
https://t.co/c3dKpGLDue
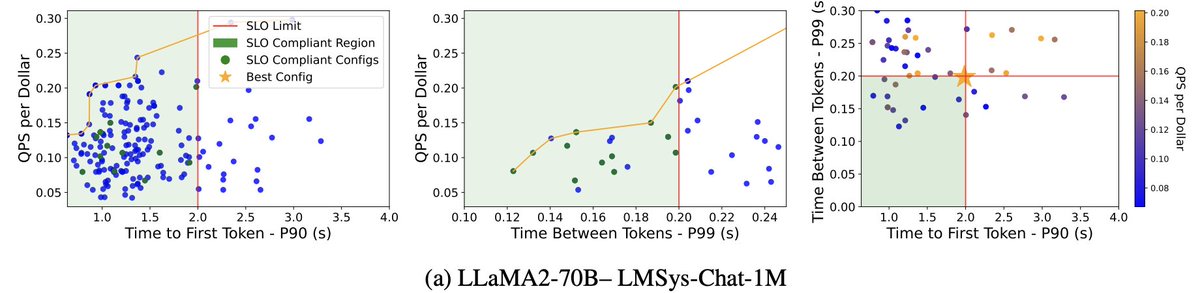
- This paper presents Vidur, a high fidelity and easily extensible simulator for large language model (LLM) inference, along with a benchmark and search suite.
- Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates end-to-end inference performance for different workloads.
- It estimates metrics like latency, throughput, model FLOPs utilization, memory utilization, etc. with high accuracy.
- Vidur addresses challenges unique to simulating LLM inference like finer time granularity, varying iteration times, and cascading errors.
- It uses insights like architectural uniformity of LLMs, operator triaging, and automated profiling for parallelism strategies to achieve fidelity.
- Vidur-Search uses Vidur to automatically identify optimal cost-effective deployment configurations meeting performance constraints.
We at @MSFTResearch and @GeorgiaTech believe that running LLM's shouldn't be so expensive 💵
So, we built a tool 🛠️ that will enable you to run it cheaper, make it cheaper.
Introducing Vidur👳🏽, the first LLM Inference System simulator.
#mlsys#vllm#llm#llama#gpt
Vidur is a tool 🛠️. Use it how you want!
We need your contributions to add more devices (@AMD GPUs anyone) and more models and architectures (go MoE @mistalai).
Code: https://t.co/64diEczBR2 (n/n)
1/ LLM inference systems are like high-performance engines ⚙️—complex, powerful, and full of intricate settings. Efficiently deploying them to maximize GPU performance is a challenge typically tackled by experts at orgs like @OpenAI and @AIatMeta 🚀. 🧵





![fly51fly's tweet photo. [LG] Vidur: A Large-Scale Simulation Framework For LLM Inference
https://t.co/c3dKpGLDue
- This paper presents Vidur, a high fidelity and easily extensible simulator for large language model (LLM) inference, along with a benchmark and search suite.
- Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates end-to-end inference performance for different workloads.
- It estimates metrics like latency, throughput, model FLOPs utilization, memory utilization, etc. with high accuracy.
- Vidur addresses challenges unique to simulating LLM inference like finer time granularity, varying iteration times, and cascading errors.
- It uses insights like architectural uniformity of LLMs, operator triaging, and automated profiling for parallelism strategies to achieve fidelity.
- Vidur-Search uses Vidur to automatically identify optimal cost-effective deployment configurations meeting performance constraints.](https://pbs.twimg.com/media/GNQBMNbbcAMQMfI.jpg)
![fly51fly's tweet photo. [LG] Vidur: A Large-Scale Simulation Framework For LLM Inference
https://t.co/c3dKpGLDue
- This paper presents Vidur, a high fidelity and easily extensible simulator for large language model (LLM) inference, along with a benchmark and search suite.
- Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates end-to-end inference performance for different workloads.
- It estimates metrics like latency, throughput, model FLOPs utilization, memory utilization, etc. with high accuracy.
- Vidur addresses challenges unique to simulating LLM inference like finer time granularity, varying iteration times, and cascading errors.
- It uses insights like architectural uniformity of LLMs, operator triaging, and automated profiling for parallelism strategies to achieve fidelity.
- Vidur-Search uses Vidur to automatically identify optimal cost-effective deployment configurations meeting performance constraints.](https://pbs.twimg.com/media/GNQBMNbacAEaNix.jpg)



![fly51fly's tweet photo. [LG] Vidur: A Large-Scale Simulation Framework For LLM Inference
https://t.co/c3dKpGLDue
- This paper presents Vidur, a high fidelity and easily extensible simulator for large language model (LLM) inference, along with a benchmark and search suite.
- Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates end-to-end inference performance for different workloads.
- It estimates metrics like latency, throughput, model FLOPs utilization, memory utilization, etc. with high accuracy.
- Vidur addresses challenges unique to simulating LLM inference like finer time granularity, varying iteration times, and cascading errors.
- It uses insights like architectural uniformity of LLMs, operator triaging, and automated profiling for parallelism strategies to achieve fidelity.
- Vidur-Search uses Vidur to automatically identify optimal cost-effective deployment configurations meeting performance constraints.](https://pbs.twimg.com/media/GNQBMl8bcAA5YAZ.jpg)






























