🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
If you are pi-curious but don't have the time to set everything up I made https://t.co/lO7oUyKgvF for you. It's a curated starting point that gets you to an exciting, useful experience immediately, without the research and configuration tax.
GEPA learnings: optimize instructions, freeze facts
A few months ago I bumped into GEPA. Was overjoyed because it helped me tag close to a million PDF pages accurately with a low cost LLM. So I pushed data set on psxGPT, a version worked, got to a 1,000 users.
But then my serious users started asking for structured data and ability to model more easily. I added those, hand crafted some rules to handle routing complexity, worked for a while but reliability sucked so I reverted to older commit.
As I started debugging and re creating my backend in a single Jupyter notebook and re running evals, gaps became clearer. Signature boundaries weren’t tightly defined. As I closed those one question remained:
What should GEPA optimize and what should it leave alone?
Where i ended: freeze facts, optimize all else.
Previously I never touched Signature docstring. But I notice letting GEPA change docstring is super effective (DSPy Signatures have a little docstring instruction in addition to input and output). For me what vs how distinction isn’t helpful. Fact vs instruction is clearer.
So schema is fact, column name fact, ticker set fact, list of canonical fact.
Everything else: instruction and therefore should be optimized. This has also led to me designing my context folder by Signature and separated by schema.md (which I don’t optimize) and a bunch of others which I do.
This process has raised another important question
When is the right time to run GEPA?
Only when signature boundaries are super tight and you’re very sure no obvious instruction is left out. Meaning whatever error is arising is just model drift and not a function of your own instruction sloppiness.
So for instance: if a stage requires inserting canonical names of a bank’s balance sheet and you didn’t insert those only to see model getting lost, fix that first.
Writing the spec, tests, defining signature boundaries, manually checking code blocks in Jupyter notebook is tedious yes but essential. I like to rebuild until cognitive load vanishes. That’s when I know that I actually “know”. Otherwise I’m winging it and that feels unsettling.
GEPA now has an API which is very easy to use. I prefer it over using the DSPy library. There are some similar optimizers out there too. I don’t understand the underlying genetic Pareto stuff well enough but this API works very well for me. Swapping DeepSeek V3.2 for Gemini 3.1 flash lite was a breeze.
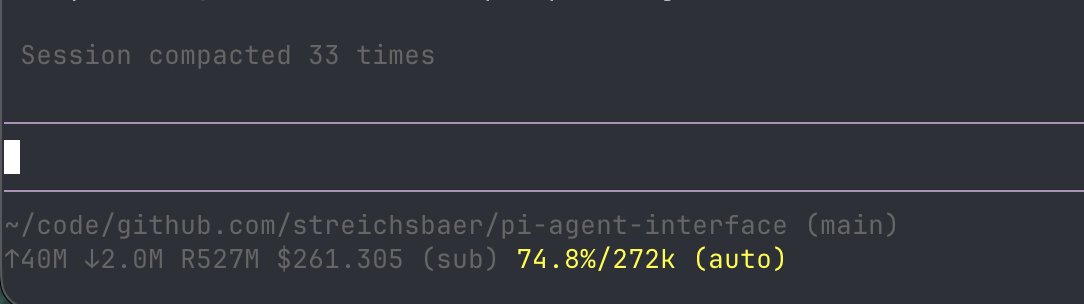
In case people are wondering whether compaction works well in Pi.
I've been using the same session for a couple of days now and just kept compacting it. 33 times to be exact.
The crazy thing is that it still seems to remember all the key details. I've used /tree a lot, jumped all over, but it's not a problem.
The jsonl of this session is 200MB and everything is snappy on my old mac.
Thanks @badlogicgames! I really appreciate your dedication to focused, non-slop software.
Someone in the Pi discord noticed that @opencode describes tool calls much more proactively than Pi. To include that same behavior in Pi, simply drop this into your AGENTS.md:
<tool_call_behavior>
- Before a meaningful tool call, send one concise sentence describing the immediate action.
- Always do this before edits and verification commands.
- Skip it for routine reads, obvious follow-up searches, and repetitive low-signal tool calls.
- When you preface a tool call, make that tool call in the same turn.
</tool_call_behavior>
We're delighted to announce that MiniMax M2.7 is now officially open source.
With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%).
You can find it on Hugging Face now. Enjoy!🤗
huggingface:https://t.co/ApWrahIl3o
Blog: https://t.co/gAxeFsNdW4
MiniMax API: https://t.co/1dgbMx0Q7K
In celebration of Omarchy 3.5 being the first distro to ship with complete Linux compatibility for the new XPS Panther Lake laptops, @Dell made me a special unit with super + omarchy keys instead of Windows and Copilot. So damn cool!
@RajaPatnaik@LakshyAAAgrawal I always end up to spend more than 20$ api cost for the optimizer, and it run very slow, not sure what I am missing or configure incorrectly
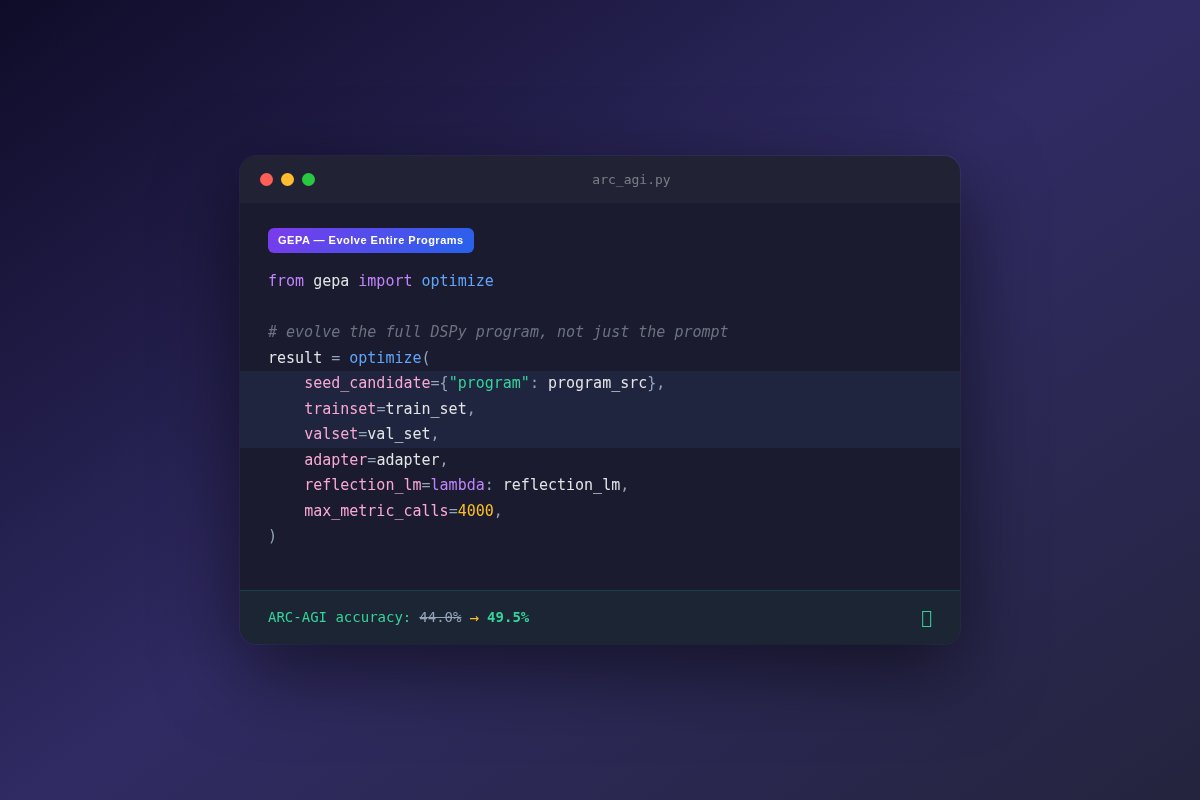
GEPA can evolve entire DSPy programs — not just prompts.
Here's how it improved Gemini-2.5-Pro's ARC-AGI score from 44% → 49.5% by discovering a multi-step reasoning agent on its own:
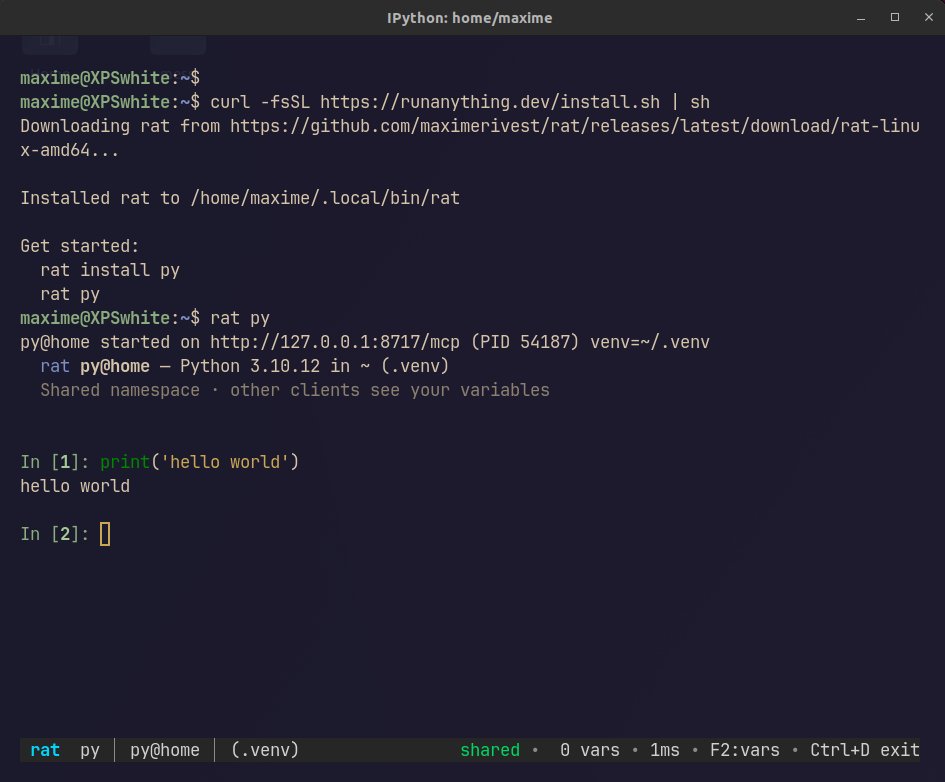
This is the beginning of rat.
RAT is an easy way to make your Python and R REPLs (and more) accessible to "all" clients/frontends.
I made rat because I needed something similar to Jupyter kernels for my markdown notebooks that run code cells and inject the results in the notebook. But rat is also complete enough to turn any coding agent into an RLM (more demos coming on that). If you stretch the concept of what is a REPL, you make rat a great management tool for coding agent windows and even Slack! Think about it — the Python REPL, the coding agent, the AI chat conversation and a Slack messaging channel are all pretty much the same. In RAT, I generalize them all under one interface, which is usable as a CLI and an API (that API happens to be in the right shape to be what we call an MCP server).
I have tested it on Ubuntu and Windows. Consider this the alpha release.
It's open source, it's free.
I don't think there is anything better out there to share your REPL with AI (so it can just come and run code with you in your Python, interacting with whatever you have cooked up in there).
links below