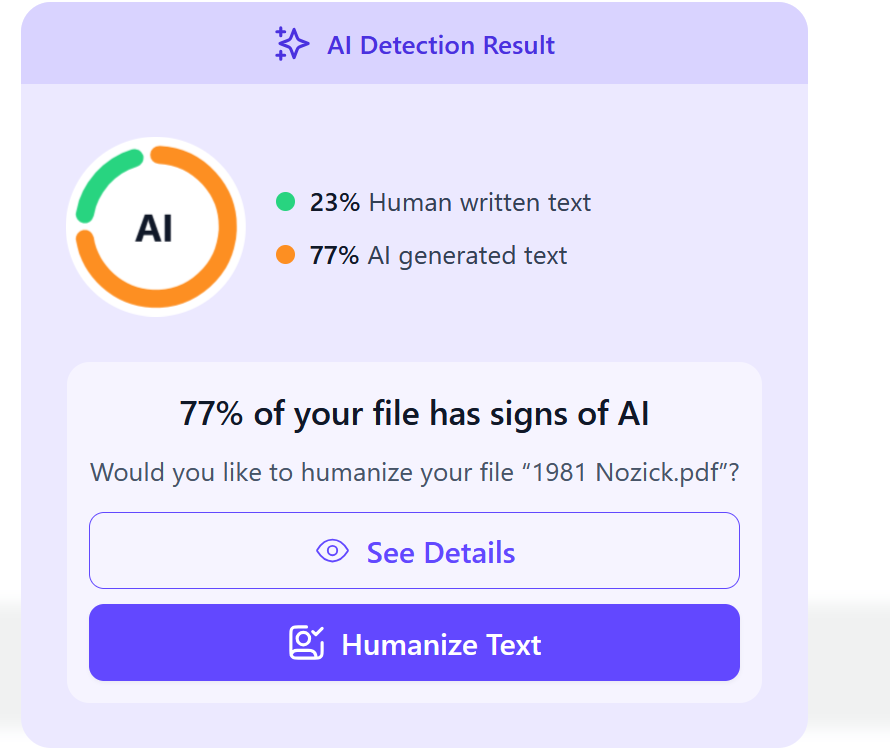
You share 98.8% of your DNA with chimpanzees. A group of 200 of them just tore itself apart in a Ugandan rainforest, and researchers have been watching it happen for a decade.
A study came out yesterday in Science, one of the top research journals in the world. For 30 years, scientists tracked the Ngogo chimps in Uganda's Kibale National Park. This was the largest known chimp group on the planet, around 200 animals all living, hunting, and raising families together. Then around 2015, the group started splitting down the middle. Two clusters, one on the west side of the territory and one in the center, stopped spending time together. Males stopped mating with females from the other side. By 2018, they'd drawn a line through the forest and refused to cross it.
The Western chimps started raiding. Between 2018 and 2024, they killed 7 adult males and 17 babies from the Central group. They ripped infants straight off their mothers' chests. Fourteen more Central males vanished during that stretch, bodies never found, while Western's population climbed from 76 to 108. John Mitani, a University of Michigan researcher who spent over 20 years with these chimps, told NBC he believes the Central group is "doomed." He used the phrase "extinction event."
This almost never happens. DNA evidence suggests chimp communities fracture like this roughly once every 500 years. The only other time anyone saw it was in the 1970s with Jane Goodall's chimps in Tanzania, but researchers questioned that case because Goodall's team had been feeding bananas to the animals for years, which may have warped their natural behavior. Ngogo is the first split observed with zero human interference.
The cause dates back to 2014. Five males died that year, likely from disease. These weren't random chimps. They had close bonds on both sides of the group, the kind of friendships that kept 200 animals functioning as one unit. Once they were gone, a new top male seized control in 2015, a disease swept through and killed 25 more in 2017, and the two sides just kept drifting until there was nothing connecting them anymore.
One part of the paper sat with me. These chimps have no ethnicity. No religion. No political parties. The war started because friendships broke down, cliques solidified, and new group identities replaced years of cooperation. Aaron Sandel, the lead researcher from UT Austin, argued that keeping relationships alive across group lines may be the actual recipe for preventing this kind of collapse. In a species 98.8% identical to us, that recipe failed in under ten years.
Studies have shown that older games with simpler graphics had a much more stimulating effect on a gamer's brain - actively "training" creative skills and imagination, with positive impact on memory building and abstraction skills.
If that sounded to scientific, have a look at the 4 images. The older ones among you will recognize some classic games.
In the first one your brain would turn that into a "Rambo" style scenario, dropped in the jungle fighting against hordes of enemies. Have a closer look at the main character - that's 3 colors and a pile of pixels. Your mind does the rest.
In the second image your brain converts the image into an epic space battle against aliens, with you sitting in a spaceship, fighting wave after wave. Again, have a closer look at the aliens. One (!) color, 2 animation phases. Now look at your "spaceship".
In the third image you are teleported by your creative mind into a fantastic world with heroes, battles, an open world, portals and so on. A magic world, that was created aong the way, by your mind.
The fourth picture turns you into Bruce Lee.
The common thing in all of those examples is your brain "filling in the blanks" - and that's EXACTLY the part that's positively stimulating it.
Now think of hyper-realistic modern games with graphics so good that your brain doesn't need to do any "imagining" anymore... instead it turns into pure consumption mode. Brain waves look entirely different then. No creative areas will fire up.
The reason why many retro gamers have fond memories of old games is not just nostalgia. It is connected to what those games have done to our brains and imaginative minds at the time. They didn't oversaturate us - they merely hinted at the right direction and our brains did the rest.
Old games were similar to books - the world was created by the reader/player. And those worlds looked different for each and everyone of us.
🚨 OpenAI, 700 milyon insanın ChatGPT'yi nasıl kullandığına dair devasa bir araştırma yayınladı.
Sonuçlar, yapay zekanın benimsenmesiyle ilgili tüm varsayımları alt üst ediyor... İşte bilmeniz gereken her şey:
Birincisi, verimlilik devrimi bir efsane.
ChatGPT kullanımının sadece %27'si işle ilgili. %73'ü kişisel. İnsanlar onu sadece görevleri otomatikleştirmek için kullanmıyorlar. Hayatlarını yönlendirmek için kullanıyorlar.
İkincisi, kodlama çılgınlığı bir balon.
Herkes size programcıların modasının geçtiğini söyledi. Ancak veriler, ChatGPT mesajlarının sadece %4,2'sinin programlama içerdiğini gösteriyor.
Bunu Claude'daki %33 ile karşılaştırın (ki bu daha çok teknoloji kullanıcılarına yöneliktir). Kodlama devrimi gerçek ama abartıdan daha küçük.
Üçüncüsü, yapay zeka bir editör, bir yaratıcı değil.
İş mesajlarının %40'ı yazmayla ilgili olsa da, bu isteklerin üçte ikisi sadece mevcut metni düzenlemekten ibaret. İnsanlar sıfırdan içerik üretmiyorlar.
Onlar bunu süper güçlü bir Grammarly gibi kullanıyorlar.
Ama işte her şeyi değiştiren bulgu:
OpenAI, insanların modelle etkileşim biçimlerinde büyük bir ayrım buldu:
- Yapma (%40)
- Yapay zekadan belirli bir görevi tamamlamasını isteme.
- Sorma (%49)
- Tavsiye arama, seçenekleri analiz etme ve karar verme.
"Sorma" kategorisi daha hızlı büyüyor ve önemli ölçüde daha yüksek memnuniyet puanları alıyor.
İnsanlar angarya işleri yapacak bir yapay zeka stajyeri istemiyorlar. Düşünmelerine yardımcı olacak bir yapay zeka danışmanı istiyorlar.
Ve işte kimsenin bahsetmediği tuzak:
Veriler, ne kadar eğitimliyseniz, iş için yapay zekayı kullanma olasılığınızın o kadar yüksek olduğunu kanıtlıyor.
Zaten nüfuz sahibi olan insanlar, daha fazla nüfuz elde etmek için yapay zekayı kullanıyorlar.
İnsanlık tarihinin en hızlı teknoloji yayılımı, iş gücünü değiştirmiyor.
Sadece doğru soruları nasıl soracağını bilen insanları, bilmeyenlerden ayırıyor.
An average picture that you save on your phone or PC has a size of around 400 kilobytes. It doesn't do anything, it's just a static image.
Now divide that by the factor 10, so you drop to 40 kilobytes. That's the size of The Last Ninja, developed by System 3 and published in 1987.
I still struggle to comprehend, even in the slightest, how programmers back then did what they did - and the worlds they created with the limitations they had to work with.
I was simply blown away by the graphics (isometric on the C64 with such an amazing level of detail - simply gorgeous) and absolutely mesmerized by the kickass sound. What Ben Daglish and Anthony Lees conjured up musically will forever be part of gaming history - an iconic masterpiece.
40 kilobytes man...
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Unpopular opinion'larım;
- Skills meselesi fazla abartılıyor, pratikte ne kadar işe yaradığı meçhul
- AI araçlarının nasıl kullanıldığı manasız bir hype yaratıyor, kimse ne çıktığına bakmıyor, AI tool'unun nasıl kullanıldığı çıktı kalitesini ne kadar etkiliyor meçhul
- Çıkan birçok yeniliğin pratikte faydası = 0
- AI firmaları her gün milletin shiny object sendromunu tetikleyip hype yaratma peşinde
- Efendi gibi chat arayüzüyle, dümdüz dille yazdığın şeyler daha iyi ve daha hızlı sonuç veriyor çoğu zaman
- Prompt yazma tekniklerinin %90'ı falan boş iş, 2 dakikada yazıp bitireceğin işi boş yere uzatmış oluyorsun
- "Bu nasıl kullanılır" diye kafa yormaktansa, "bunu nasıl üretiriz" diye düşünmek lazım
- Her gün her şeye hype'lanan insanların güvenilirliği zaman içinde yok olup gidecek, bir noktada kimse bu insanları ciddiye almayacak
- Çoğu insan için AI'yi çok iyi derecede bilmek bir fark yaratmıyor ve yaratmayacak da
- Asıl önemli olan şey çok tool bilmek ve kullanabilmek değil; en az tool'la, en az friction'la çıktıya ulaşmak olacak, 38 farklı tool'la workflow kurmanın esprisi pek yok (SaaS'a ya da kolay kurulup kullanılan bir şeye filan dönüşürse başka tabi)
- Her gün 100 farklı işlem yerine AI sayesinde 10,000 farklı işlem yapabilmenin gelire etkisi 0 veya 0'ın altında olabilir
- Yapılan işlemin artışı, her zaman üretkenlik artışı değildir
- Üretkenlik artışı her zaman doğrudan gelir getirmez, her zaman faydalı da olmayabilir
- Satın alacak müşteri yoksa, üretilen çılgın işlerin değeri çoğu zaman sıfırdır
- İnsanlar kendileri için de başkaları için de gereksz gürültü yaratıyor çoğu zaman, bu kadar odaksızlık ve hype iyi değil
Every time you message an AI chatbot, the model stores your entire conversation in temporary memory called a KV cache (a cheat sheet so it doesn’t re-read everything from scratch). On a large model like Llama 70B running a long conversation, that cache alone eats 40GB of GPU space, often more than the AI model itself.
That’s half a $30,000 GPU chip consumed by one user’s memory.
Google just published TurboQuant, a compression algorithm that shrinks this cache by 6x, down to just 3 bits per value, with zero accuracy loss across every benchmark tested. No retraining. No fine-tuning. Drop-in replacement.
AI inference (running models for actual users, not training them) now makes up 55% of all AI compute spending. Hyperscalers are pouring nearly $700 billion into AI infrastructure in 2026. The KV cache is the single biggest memory bottleneck in that stack. When GPU cache memory fills up, the system can’t take more users.
6x compression means the same hardware handles roughly 6x more simultaneous conversations, or 6x longer context windows, or some mix of both. At cloud rates of $2-3/hour per H100 GPU, that’s the difference between profitable and unprofitable AI deployment.
TurboQuant randomly rotates data to simplify its structure, applies a compressor, then adds a 1-bit error correction step to catch errors before they compound. On H100 GPUs it delivers up to 8x speedup over uncompressed computation. Google tested it across five long-context benchmarks on Llama, Gemma, and Mistral models. Perfect scores on needle-in-a-haystack (finding one specific fact buried in massive text). Being presented at ICLR 2026.
It also outperforms existing methods for vector search, the technology that powers how search engines find similar results across billions of entries. Google runs billions of these searches daily.
Three bits. Zero loss. 6x compression on the biggest memory bottleneck in a $700 billion infrastructure buildout.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
this right here is the reason China stays quiet on Iran
everyone losing their mind asking where is Beijing while the US & Israel are bombing a major chinese energy partner and the answer is so brutal in its simplicity that most analysts miss it completely, the empire is eating itself alive and China is already building the replacementt
America just dragged the entire Middle East into a war for Israel & now Saudi arabia, UAE, kuwait & qatar are sitting in a room discussing pulling out of US contracts & canceling investment commitments
the Gulf states, the literal foundation of the petrodollar, the system that has kept the US dollar as world reserve currency since 1974 actively discussing the exit and Beijing did absolutely nothing to make that happen…Washington did it to itself
but here's what people miss: china saw this coming years ago and already laid the tracks, literally the belt & road Initiative has quietly wired 150 countries into c’hinese infrastructure, ports, railways, highways, fiber optic cables, power grids…while the western media barely covered it
Saudi Arabia started selling oil to China in yuan in 2023, that alone should have been front page news for a month, the BRICS just expanded to include Saudi arabia UAE and Iran in the samea bloc, China built CIPS as a direct alternative to SWIFT so the entire non western world can settle trade without ever touching the dollar, every single one of these moves was made before a single bomb fell on Iran
and then there's Africa…the youngest continent on earth, median age 19, projected to reach 2.5 billion people by 2050, the largest workforce the planet has ever seen & China understood 20y ago that whoever builds Africa's infrastructure owns the 21st century, while the US was spending 4 trillion dollars destroying Iraq & Afghanistan China was building railways in Kenya, dams in Ethiopia, ports in Djibouti, highways in Nigeria, tech hubs in Rwanda, stadiums, hospitals, government buildings, telecom networks powered by Huawei across the entire continent.. & they did it without firing a single bullet, no regime change, no sanctions, no lectures on democracy, just concrete steel, fiber optic and longterm contracts
so when people ask why China stays silent on Iran the answer is that silence is the strategy, every war America fights for Israel costs trillions, destabilizes energy markets, alienates Gulf partners and pushes the entire Global South closer to a system Beijing spent two decades building
the gulf states pivoting right now has zero to do with ideology, Washington turned their entire neighborhood into a warzone to serve Tel Aviv's regional strategy & then asked them to keep buying treasury bonds with a straight face….the math just stopped working and when the math stops working loyalty stops too
beijing's silencee on Iran is the most patient & most devastating move on the board, China is watching america dismantle its own hegemony in real time while quietly inheriting every alliance washington burns, it just has to keep building & keep quiet
Napoleon said nver interrupt your enemy when he is making a mistake, Xi turned that into a 50y doctrine & right now it's paying off faster than even beijing expected
@HasanKhxnx I am not suicidal. I eat healthy food. The brakes on my car and truck are in good shape. I practice good trigger discipline and never point a gun at anyone, including myself. There are no deep pools of water on my farm and I’m a pretty good swimmer.
Kaygı Bozukluğu Olanların Endişelerinin %91.4'ü Asla Gerçekleşmiyor!
Yapılan büyük bir araştırma (Penn State Üniversitesi, 2023-2025 verileriyle güncellenmiş meta-analizler):
Kaygılı kişilerde ortaya çıkan endişelerin:
- %91.4'ü hiç gerçekleşmiyor!
- Geriye kalan %8.6'sından bile çoğu, korkulduğu kadar kötü olmuyor.
Yani beynimiz "en kötü senaryo" üretmekte usta, ama gerçek hayatta bunlar nadiren oluyor.
Kaygı, geleceği öngörmek değil, geleceği abartmak demek.
Bu istatistik size ne hissettirdi?
- Biraz rahatlattı mı?
- Hâlâ zorlanıyor musunuz?
Kendinize şunu hatırlatın:
"Bu da büyük ihtimalle o %91.4'ün içinde."
Nefes alın, şu an güvendesiniz. 🌿
#Kaygı #Anksiyete #Endişe #MentalSağlık #Psikoloji #Bilim
Yes, I know. Nothing I can do about it. YouTube refuses to take these deep fakes down. And even if they do, they spring up faster than I can shut them down. I suppose we must all learn to doubt all we see and hear. Perhaps this is the beginning of social media's self-immolation...
“Toplumsal memnuniyetsizlik kesinlikle oyun dünyasının alternatif gerçekliklerinin doğasında vardır ve fantezi senaryoları genellikle çağdaş sorunlara atıfta bulunur. Örneğin ünlü Ultima oyunları kesinlikle liberal bir gündeme sahiptir ve kirlilik, uyuşturucu bağımlılığı, …
Bu oyunların ardındaki hırs yeni bir dünya yaratmak ve bu kez bunu doğru yapmak, gerçeklikten çok daha iyi, çok daha kötü ya da en azından daha az sıkıcı bir şey yapmaktır. Senaryo ütopik olmaktan çok distopiktir ama en azından distopya sıkıcı değildir…