Most AI investing happens downstream of the frontier: a capability emerges, a category gets named, and capital rushes in.
But by the time a category earns a clean box on a market map, the best builders have usually been living in the messy version for months.
Agents. Reasoning. RL environments. World models. AI for Science. Recursive self-improvement.
I call this frontier proximity: the ability to see what is becoming possible before it becomes consensus.
My frontier proximity ladder:
L0 Wrapper: uses today’s models.
L1 Reactor: reacts fast to releases, but roadmap is downstream.
L2 Anticipator: builds for where capabilities are going.
L3 Native: depends on a non-obvious frontier bet.
L4 Shaper: helps move the frontier itself.
The point is not that every company needs to train models.
Apps can have high frontier proximity if they understand what models will make possible next.
Infra can have high frontier proximity if it knows what future agents, multimodal systems, robotics stacks, or scientific workflows will need.
That is why we’re launching MoE Capital.
MoE stands for Mixture of Experts.
The idea is simple: build an AI fund around people closest to the frontier: frontier researchers, technical founders, AI-native builders, and seasoned operators.
We don’t want to be another AI fund with a newsletter-level understanding of the frontier.
We want to build the AI fund closest to the frontier.
More in The Information: https://t.co/CXWJAy34zi
🚀Introducing UniRL, an RL infra for unified multimodal models. Together with two new RL algorithms: DRPO and Flow-DPPO.
One RL loop across diffusion/flow matching models, LLMs/VLMs, and unified multimodal models👇
Code: https://t.co/fhKEqqFpc8
(yes — U(you)-ni-(need) RL 😉)
Always back to the basics:
LatentMoE was probably inspired by MLA, which was inspired by LoRA, which was inspired by SVD, which was inspired by eigendecomposition.
This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
So excited to be opening up OpenEnv to the whole community. It will now be owned by @huggingface , Meta-PyTorch, @reflection_ai , @UnslothAI , @modal, @PrimeIntellect , @NVIDIAAI , @mercor_ai , and @fleet_ai .
the reason is: frontier labs train the model and the harness together, so the model is fitted to its harness. that coupling is a chunk of why claude code and codex feel so good.
open source can't do that. you bring whatever harness, whatever model, whatever env, whatever trainer. which is the whole point of open source and also the problem for training.
openenv is the socket in between all of this.
in short: it's a protocol layer, not a reward framework. it does not have opinions about your rewards or your training loop. those live in the libs that are actually good at them.
read more in the blog post. it's early, come break it.
In this blog, we explore new potential directions for the field of AI based on continual interaction and causality:
https://t.co/2qh0OP5l1N
We've been working on this for years. Pedro Ortega pointed out issue much earlier when I was working on General AgenT One: GATO 🐈⬛
https://t.co/ZOM8pwyM8O
We discussed the problem of delusions with LLMs, OMNI models or World Models in a @GoogleDeepMind report:
https://t.co/Ss7hvdvRUl
The theoretical breakthrough was this:
https://t.co/Ux7BN6Mam3
Then it was generalised to back-propagation and neural networks:
https://t.co/R8xUCDNUfl
And to reward learning:
https://t.co/uJSgqGRXAw
Here, we started testing the idea for Q&A datasets, and comparing against ReST and GRPO, to show viability.
What we need now is to implement an agent that browses the web (or any other environment) and whenever it finds a question or challenge with a solution (text, teacher, oracle), it attempts to solve it itself. If it succeeds it continues. If it fails, it looks at the solution, and continues. Importantly, it must NOT learn from its actions but from the consequences of its actions - the blog explains why.
This agent does not learn from sequences or histories of observations. This model learns from interaction and interaction histories. It is of paramount importance to appreciate this distinction.
What matters now is those environments on the right of the picture!
I am grateful to @OpenAI GPT5.5 and Codex, without which this research would have taken weeks if not months longer. Thanks @sama@gdb and team 🙏
❤️ 4 ∀ .ai
In case you didn’t notice: Agent Arena doesn’t have a voting mechanism. So how do we calculate the scores?
The answer is causal inference. Agents are multi-stage systems where the orchestrator and harness work together to produce the end result. We developed a method called causal tracing that looks at each possible orchestrator and harness component as a treatment, and evaluate the treatment effect with respect to a randomized baseline on all the signals mined from traces. This allows us to independently evaluate each subcomponent, track how the effects change as new options are added, and combine many signals into one coherent leaderboard.
The leaderboard you see is the net effect of the orchestrator as a treatment when looking across a basket of implicit and explicit success signals, including:
- Confirmed success: user marks task as success or failure.
- User affirmation: user praises or complains about agent output.
- Steerability: agent responds correctly to user requests.
- Bash recovery: time taken to recover from making an error in bash.
- Tool hallucination: agent hallucinates tool that does not exist.
Human preference is now only one of the many signals that Arena can measure. All signals based on real-world usage by a huge population of 10s of M of users.
vLLM is built by an amazing community, not by me😁
I’m still surprised that a screenshot of my GitHub profile can get this many views on X. If there’s anything worth paying attention to, it’s the incredible work being done by the @vllm_project community and the team at @inferact.
Also just updated my GitHub profile🙂
And yes — both vLLM and Inferact are always looking for strong engineers and researchers. Come build with us💪
Identifiability is what it means to learn the right latent space, the Gaussian is why LeJEPA works, and it's what makes planning transfer.
I think identifiability is the right definition of what it means to learn a World Model 🌍
The natural next step for the theory: add action conditioning, like in LeWorldModel (@lucasmaes_ et al.),
w/ @randall_balestr@ylecun 🔬🤖
Paper: https://t.co/tcj4ZTwfJS
Code: https://t.co/cu8nxO15mb
What does JEPA actually learn? We can finally prove it 🌍
So excited to share our theory of identifiable World Models: LeJEPA recovers the latent variables of the world.
Plan in the learned World Model as if it were real, same shortest path.
📄: https://t.co/lC9KK1AxVd
Interested in learning how to run RL at scale? Here are the best resources to read…
Research on Scaling RL
1. The Art of Scaling RL compute for LLMs: https://t.co/PGjI6Gwgv0
2. Scaling Behaviors of LLM RL Post-Training: https://t.co/2u2saB3C0h
3. Optimally Scaling Sampling Compute for LLM RL: https://t.co/rUSdUvJyNH
4. Scaling up RL: https://t.co/O8vV6z8ymx
5. ProRL V2 - Prolonged Training Validates RL Scaling Laws: https://t.co/vu72juvRW4
6. Polaris - A Recipe for Scaling RL with Reasoning Models: https://t.co/rMibSAeJbg
RL Frameworks
1. Hybrid Flow (early outline of the verl framework): https://t.co/GnWXx131uD
a. More up-to-date info can be found here: https://t.co/j801HcJmPP
2. AReal - Large-Scale Async RL: https://t.co/qhOvsQK09N
3. PipelineRL - Fast On-Policy RL: https://t.co/iRM7KzySXe
4. AsyncFlow - Async Streaming RL: https://t.co/YwmzFtiU2q
RL for Agents
1. DeepSWE - Open Coding Agent Trained w/ RL: https://t.co/GHQHcmtE6F
2. AutoForge - Environment Synthesis for Agentic RL: https://t.co/mr3WDIL5vq
3. Agent-R1 - Training Agents w/ End-to-End RL: https://t.co/xpfQJGgzEv
4. AgentRL - Scaling RL for Multi-Turn, Multi-Task Agents: https://t.co/7fbVl0RWXG
5. The Landscape of Agentic RL: https://t.co/OMnSV4rgdW
6. Training SWE Agents with RL: https://t.co/YqMqySbyXS
Case Studies & Tech Reports
1. Kimi tech reports:
a. Kimi K2 - Open Agentic Intelligence: https://t.co/aAw17SXrIw
b. Kimi End-to-end Agentic RL: https://t.co/ProBpOPIiI
c. Kimi K1.5 - Scaling RL for LLMs: https://t.co/kRGOxY9Jvp
2. Composer series from Cursor:
a. Composer 2: https://t.co/K0v8rNCE6Z
b. Composer 2.5: https://t.co/D9PYimfOMU
3. Olmo 3 (also has open code / data): https://t.co/khetJFvp6N
4. MiniMax tech reports:
a. MiniMax-M2: https://t.co/HApb0OB80S
b. MiniMax-M1: https://t.co/mZj9UQsrnC
5. Nemotron 3 (NVIDIA): https://t.co/lCpE1GzxSi
New blog! Is frontier asynchronous RL solved?
The blog covers Async RL theory and infrastructure, surveying 8 open-weight frontier labs for the algorithmic techniques and systems fixes to handle train-inference mismatch. Also answered: why do current methods still fail at high policy lag? Which methods scale with horizon and compute?
Excited to release 🌟Polar🌟, our Agent RL rollout infra for real-world harnesses. Be it Codex, Claude Code, OpenClaw, Hermes, or your self-made ones 🔥 -- Polar takes your harnesses directly as training environments without code change.
Find a problem, design the harness, and train your own agents! 🧵
🦀 The Rust frontend is officially merged into vLLM!
As GPUs get faster, the frontend has become a real share of CPU time. The new Rust frontend is a drop-in alternative to the Python API server — same engine, same ZMQ boundary. Opt in with VLLM_USE_RUST_FRONTEND=1.
Early numbers: on a preprocess-heavy workload, ~837 req/s vs ~162 req/s for default Python — ~5x in a single process.
A few design choices we're excited about:
• Layered crates with clear boundaries
• Stream-native pipeline — non-streaming for free
• Builds on stable Rust
Huge thanks to @BugenZhao from @inferact for introducing the work at @PyTorch Meetup Singapore.
https://t.co/Tw8PoIjbH9
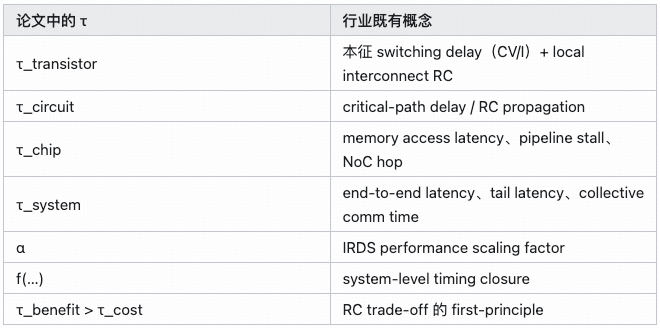
Huawei’s “Tao / τ Law”: Tech Paper, White Paper, or Strategic Manifesto? 🧠🚀
🌟Insights from Zhihu contributor 无我梦中
Huawei’s new paper, “A Time Scaling Theory for Multi-Layer Electronic Systems” by Tingbo He, is better read as a semi-technical white paper + strategic declaration, not as a pure theoretical research paper.
The core idea is powerful:
Replace “transistor size in nm” with “time constant τ” as the unified progress metric for semiconductors.
In plain English:
The future of chips is not only about making transistors smaller. It is about making the whole system wait less.
📌 What the Paper Is Really Saying
The paper’s logic can be summarized like this:
1️⃣ Moore’s Law was never just about space.
Smaller transistors mattered because they reduced time: faster switching, shorter wires, fewer boundaries, lower system delay.
2️⃣ After 7nm, geometric scaling gets weaker.
Intrinsic device delay no longer improves as easily. Local interconnect RC delay becomes more important. EUV depreciation, mask cost, verification, and design cost rise sharply. The cost-per-transistor curve is flattening or even turning upward.
3️⃣ So the industry should scale time directly.
Huawei defines τ across 12 orders of magnitude — from transistor picoseconds to data-center seconds — as a shared optimization target.
4️⃣ Huawei gives three major proof points:
• LogicFolding on Kirin 2026: +55% density, +41% energy efficiency, +13% frequency at the same node
• Unified Bus for AI data centers: remote access latency from tens of μs to ~100 ns
• Hi-ONE optical I/O + 3D Folding: solve the 2.5D packaging “N² vs N” bottleneck
5️⃣ Long-term roadmap:
• by 2031: “equivalent 1.4nm” density, 400+ MTr/mm²
• by 2035: 100× AI hardware integration
The direction is meaningful. But the details need careful reading.
1️⃣ The End of the Geometric Era
The paper starts with a familiar claim: geometric scaling is reaching its limit.
This is mostly true.
Cost-per-transistor no longer reliably falls. EUV depreciation eats a large share of wafer cost. High-end chip design budgets can approach or exceed $1B. IRDS, Hennessy & Patterson, and Horowitz have all made similar arguments.
For a company like Huawei, restricted by advanced lithography access, this wall arrives earlier and hits harder.
But here the paper mixes two things:
• the global slowdown of Moore-style economics
• Huawei’s own manufacturing constraints
TSMC N3/N2, Intel 18A, and Samsung GAA are still improving transistor density. The physical path is not fully broken. What is broken is the old economic contract: new node = better + cheaper.
So the paper’s framing is selective.
It uses an industry consensus to make Huawei’s own solution look like the inevitable path forward.
That is understandable as strategy. But as pure industry analysis, it goes a bit too far.
2️⃣ Time, Not Space ⏱️
This is the most philosophical part of the paper.
Huawei argues that Moore’s Law benefited users not because chips became “smaller,” but because systems became faster.
So metrics like:
• frequency
• latency
• bandwidth
• throughput
are all treated as different expressions of τ at different layers.
This framing is useful. It gives process, circuit, architecture, system, and software teams a shared language.
But academically, it is not completely new.
Hennessy & Patterson’s “A New Golden Age for Computer Architecture,” Horowitz’s energy-per-operation work, and IRDS “More than Moore” roadmaps have all pushed the same direction: transistor shrinking alone is not enough; system-level optimization matters.
So τ scaling is more like a new name for an old system-level idea, not a new physical discovery.
There is also some looseness in the math.
Bandwidth is not a time constant. It is bits per time. Throughput is not simply 1/τ either; it should be closer to:
throughput = 1 / τ_per_op × parallelism
Parallelism gets quietly absorbed.
For management narrative, that simplification is fine.
For a paper claiming a Dennard-level full-stack target, it feels light.
The real value of this section is not theory. It is language. It gives the whole industry stack one number to talk about: time.
3️⃣ LogicFolding: The Most Concrete Part 🏗️
This is the section most likely to go viral.
Huawei uses Kirin 2026 as proof that LogicFolding can deliver big gains without changing the process node:
• transistor density: 155 → 238 MTr/mm²
• performance-core energy efficiency: +41%
• peak frequency: +13%
• SRAM frequency: +40%+
• clock buffers: -50%+
• clock skew: -25%
• wire length: -30%
On paper, this looks almost like gaining a full process generation.
The engineering details are also specific:
• hybrid bonding pitch: 1.5 μm
• overlay: under 0.5 μm
• TSV CD / KOZ: under 1.5 μm
• TSV pitch: under 6 μm
• failure rate: under 100 ppm
�� with repair, yield close to 100%
None of these numbers are impossible. But each sits close to today’s hybrid-bonding limits.
The bigger issue is methodology.
The paper does not provide:
• die photos
• SEM images
• wafer-level yield curves
• clear PPA baselines
• workload details for energy efficiency
• test corner / voltage / temperature conditions
So the headline numbers are attractive, but hard to independently verify.
There is also an important density caveat.
The formula counts both active tiers into one footprint. So 238 MTr/mm² is package-footprint density, not true silicon-area density.
That is normal in 3D integration. It is not deception. But readers must understand what “density” means here.
It measures how efficiently packaging uses 3D space, not how small the transistor is.
What is LogicFolding really?
It is not just process innovation.
It is not just packaging innovation.
It is not a brand-new theory either.
It is a combined design methodology:
sub-2 μm hybrid bonding + cross-die logic partitioning + custom EDA flow
The direction is physically sound: shorten critical interconnects, improve density, frequency, and efficiency.
But before third-party measurement appears, it is safer to discount the exact numbers.
Believe Huawei probably built something real.
Do not treat every number like audited silicon data yet.
4️⃣ AI Data Centers: Unified Bus, Hi-ONE, 3D Folding 🌐
The paper then moves from one chip to AI clusters.
Unified Bus
Unified Bus tries to collapse today’s complex data-center communication stack.
Traditional AI clusters rely on layers like:
• PCIe
• NVLink or private fabrics
• Ethernet / InfiniBand
• RDMA software stack
• DMA buffers and handshakes
Every layer adds latency and copying.
Huawei’s Unified Bus wants to expose memory semantics across chassis, with hardware-managed consistency. The paper claims remote access latency improves from tens of microseconds to about 100 ns, or roughly 500× τ reduction.
This number needs caution.
“Tens of μs” sounds like a TCP/IP baseline. But modern AI clusters using RoCEv2 or InfiniBand already reach the 1–3 μs range across racks, and NVLink can go below 1 μs inside a rack.
So the chosen baseline is favorable.
The “~100 ns” claim is also unclear.
If it refers to on-package or rack-local fabric protocol latency, it may be reasonable. But if it refers to cross-rack physical distance, it violates basic propagation delay. Light in fiber needs about 500 ns one-way for 100 meters.
So the most reasonable reading is:
100 ns refers to rack-local fabric/protocol latency, not full cross-rack physical latency.
The paper does not clarify this enough.
Hi-ONE Optical I/O
Hi-ONE is Huawei’s near-package optical engine.
The paper mentions:
• 8 Tb/s per module
• electrical SerDes distance reduced from 100 cm to 5 cm
• optical path extended from under 1 m to 100 m
Technically, this direction is credible.
Broadcom CPO, TSMC COUPE, Ayar Labs, Lightmatter, and others are all moving in the 4–8 Tb/s range around this timeline.
Huawei’s choice of near-package optics is also practical. It is less aggressive than full co-packaged optics, but likely easier to engineer.
The missing pieces are key parameters:
• BER target
• pJ/bit
• thermal reliability
• laser MTBF
• single-mode vs multi-mode fiber
• cost structure
So the direction is industry-aligned. It is not obviously behind, but not clearly ahead either.
3D Folding and the N² vs N Problem
This is one of the strongest arguments in the paper.
In a traditional 2.5D AI chip:
• logic die sits in the center
• HBM, SerDes, and power delivery enter from the edge
If die side length is N:
Compute ∝ N²
because compute grows with area.
But:
Bandwidth / I/O / Power ∝ N
because they enter from the perimeter.
That creates a topology deficit. Compute grows faster than the ability to feed it.
This is not a Huawei-only observation. NVIDIA Blackwell, Marvell, TSMC, Apple, and others are all dealing with the same bottleneck. But Huawei explains it very clearly.
The 3D Folding solution is natural:
Move constrained resources from the edge to the surface:
• backside power
• integrated voltage regulation
• hybrid-bonded memory
• near-package optical I/O
• 3D stacking
Then bandwidth, I/O, and power can scale more like area.
I fully agree with the direction.
But the paper underplays the cost.
Stacking active tiers creates hard problems:
• lower-tier heat removal
• bond yield × known-good-die yield × bond yield
• hard post-bond fault diagnosis
• limited repairability
• hybrid bonding equipment cost
• CTE mismatch reliability
• TSV stress affecting channels
The paper lists these challenges later, but treats them optimistically. Thermal, yield, and test remain the hardest parts.
5️⃣ Logic and Memory Re-Fusion 🧠
This section is more industrial than academic.
For decades, logic and memory were deliberately separated. CPU focused on compute. DRAM focused on storage. Standard buses connected the two.
That worked well in the PC era.
But AI changes everything.
Model parameters, KV Cache, activations, and gradients make data movement as important as compute. HBM, hybrid bonding, 3D SRAM, near-memory compute, and in-memory compute all point to the same trend:
logic and memory must get closer again.
This is not new. AMD 3D V-Cache is already in production. HBM4 is coming. CXL explores memory pooling. Samsung, SK Hynix, Sony, and others are all moving in related directions.
The paper does not add much academic novelty here.
But the strategic message is strong.
When the paper says long-term success belongs to those who can fuse logic and memory technologically and economically, it is effectively calling upstream partners:
• CXMT
• YMTC
• Hua Hong
• SMIC
• Huawei’s own packaging ecosystem
The message is:
AI hardware winners must integrate logic, memory, packaging, and economics together. No one can optimize alone anymore.
6️⃣ Open Challenges: The Best Section ⚠️
This is the most credible part of the paper because it openly admits what is not solved.
EDA is the first bottleneck
Current EDA tools optimize area, timing, and power mostly in 2D.
LogicFolding needs tools that treat stacked dies as one continuous 3D design object:
• cell-level cross-die partitioning
• 3D placement
• cross-die timing closure
• vertical interconnect parasitics
• KOZ modeling
• wafer-to-wafer process variation
Traditional 2D EDA cannot handle this well.
The paper says Huawei has preliminary internal tools, but also clearly implies:
τ-native EDA may be the single most important investment of the next decade.
Cross-wafer variation is hard
LogicFolding may bond wafers from different lots or nodes. Vth, drive current, and interconnect RC can vary more between wafers than inside one die.
Clock distribution and hold margins are hit first.
Adaptive compensation and τ-aware signoff may help, but this is engineering, not theory.
Vertical interconnect has its own τ cost
Every hybrid bond and TSV has R and C. TSV KOZ also pushes standard cells away.
So folding cannot be blind.
It must satisfy:
τ_benefit > τ_cost
This is a healthy self-constraint. The paper admits the threshold depends on workload and bonding pitch.
Energy is separate
τ is a time law, not a joule law.
If a super-node runs 10× faster but also consumes 10× power, τ scaling itself does not object — but the power grid will.
So τ optimization must be paired with:
• memory-semantic fabrics
• CPO / NPO
• backside power
• near-memory compute
• data-center DVFS
The paper also makes a useful point: τ headroom can be traded back into energy savings, just like smartphones used performance headroom to improve battery life.
Benchmarks must change
Linpack, MLPerf, and SPEC come from a world of single scalar scores.
τ scaling needs a τ-profile: a vector showing dominant τ and remaining headroom at each layer.
This is a good idea, but benchmark standardization requires industry cooperation. One company cannot do it alone.
The irony is clear:
The paper is honest in Section 6.
But this honesty also weakens the certainty of earlier claims.
If EDA, cross-wafer variation, energy, and benchmark standards are not mature yet, then numbers like +41%, 500×, 100×, and 1.4nm equivalent should be read with caution.
7️⃣ Roadmap and Future Claims 🗺️
This section is clearly a roadmap, not a research conclusion.
It projects:
• density from 155 MTr/mm² to 400+ MTr/mm² by 2031
• Kirin performance-core frequency to 4 GHz by 2029
• AI hardware integration up 100× by 2035
• “the next dollar should follow τ, not nodes”
The message is strong. But the evidence varies.
The frequency table is eye-catching:
• Kirin 9000s: 2.6 GHz
• Kirin 9020: 2.65 GHz
• Kirin 9030 Pro: 2.75 GHz
• Kirin 2026 with LogicFolding: 3.1 GHz
• 2028: 3.71 GHz
• 2029: 4.0 GHz
But later rows are marked Pre-silicon, likely from STA simulation and experience-based extrapolation, not measured silicon.
Putting pre-silicon estimates next to mass-product data is common in corporate roadmaps, but academically it is weak.
The “2031 equivalent 1.4nm” phrase is also easy to misread.
It means density equivalent by package footprint, not true process-node equivalence.
It does not mean:
• equal frequency
• equal energy efficiency
• equal cost
• Huawei catches TSMC N1.4 in all dimensions
Media translating it as “Huawei catches TSMC by 2031” would be wrong.
The “100× by 2035” claim is the loosest. The baseline and unit are unclear: bandwidth? transistors? FLOPS? HBM capacity? rack-scale compute?
Without a clear unit, it is vision language, not engineering data.
The most important sentence is:
“The next dollar should follow τ, not nodes.”
This is not a technical proof. It is positioning for investors, regulators, and supply-chain partners.
It says: advanced packaging, memory bandwidth, fabrics, and system design now deserve the strategic weight that advanced lithography once monopolized.
τ Scaling Itself: Useful, But Overpackaged
τ scaling does not introduce a new physical quantity.
Every item maps to existing concepts.
Its real value is the unified scale.
That is useful. It lets process, circuit, architecture, system, and software teams talk about one shared optimization target.
But it is not Dennard scaling.
Dennard gave a stronger quantitative framework. τ scaling is closer to a cross-layer engineering KPI.
Useful? Yes.
A new law of physics? No.
Final Assessment 🧾
As an academic paper, it is not top-tier.
τ lacks a strict mathematical definition. The function:
τ = f(τ_transistor, τ_circuit, τ_chip, τ_system)
is more diagram than formula. The paper does not define whether f is additive, max-based, path-based, or something else.
The generational formula:
τᵢ₊₁ = τᵢ / α
looks like Dennard scaling, but α is empirical, not derived from physics.
Key numbers also lack methodology:
• +55% density
• +41% energy efficiency
• +13% frequency
• 500× τ reduction
• 100× integration
There is no die photo, SEM, third-party test, or full baseline.
As a research-track paper at ISCA or ISSCC, it would likely struggle. As an IEEE Micro perspective or CACM-style viewpoint, it makes more sense.
As an engineering roadmap, it is much stronger.
LogicFolding gives concrete parameters. The N² vs N packaging argument is clean and powerful. Section 6 is unusually honest about EDA, variation, vertical interconnect cost, energy, and benchmarks.
As an industrial strategy paper, it is excellent.
It connects process, packaging, interconnect, AI, and SoC into one story. It speaks to supply chains, capital markets, regulators, and partners at the same time.
Its message is clear:
Huawei’s next decade is not only about catching up on nodes. It is about building a full-stack system path around τ.
As an external communication text, it is almost perfect.
“τ, not nm” is a slogan that can last ten years.
“1.4nm equivalent” is a media hook.
“100× by 2035” creates imagination space.
LogicFolding, Unified Bus, and Hi-ONE are product names that can each become a story.
The biggest value of this paper is that it puts:
advanced packaging + design methodology + optical interconnect + system fabric
into one unified framework, and gives China’s semiconductor industry a public methodology for moving forward even under EUV constraints.
The biggest weakness is overpackaging.
τ scaling is not mathematically as strong as Dennard scaling, but the paper places it in that role. The “100 ns remote access” claim is ambiguous. Key numbers are not third-party verified. Pre-silicon estimates enter the conclusion. “1.4nm equivalent” is easy to misinterpret if the equivalence dimension is not clarified.
So the right reading is:
not a pure theory paper, not just marketing, but a strategic engineering manifesto with real technical direction and unverified headline numbers.
It is worth taking seriously.
But not worth reading like a final verdict.
🔗 read more: https://t.co/DNN6KgJK9Z
#Huawei #Semiconductor #ChipDesign #AdvancedPackaging #EDA #AIInfrastructure #OpticalInterconnect #ChinaTech #TechLiberty
Do something different this weekend.
Become a PRO in AI Model Fine-tuning.
Paste this prompt in Codex/ChatGPT/Claude/Grok.
"You are an expert AI engineer and teacher.
Your job is to teach me modern LLM engineering and fine-tuning concepts from beginner to advanced level using very simple daily-life language.
Teach me step-by-step like a real mentor. Assume I am smart but new to the topic.
Foundations:
- LLM basics
- How AI models work
- Tokens
- Tokenization
- Context windows
- Embeddings
- Transformers
- Attention mechanism
- Parameters
- Training vs inference
- Open-source vs closed-source models
Datasets & Training:
- SFT datasets
- Instruction tuning
- Preference datasets
- Synthetic datasets
- Data curation
- Dataset cleaning
- Dataset formatting
- Fine-tuning basics
- Continued pretraining
- Hallucination reduction
Fine-Tuning:
- LoRA
- QLoRA
- DPO
- RLHF
- Quantization
- Model checkpoints
- Adapter tuning
- GGUF models
Inference & Optimization:
- KV cache
- Flash Attention
- Speculative decoding
- Inference optimization
- Model serving
- Batch inference
- GPU basics
- VRAM basics
- Latency vs quality tradeoffs
Local AI Ecosystem:
- llama.cpp
- Ollama
- vLLM
- MLX
- Hugging Face
- Unsloth
- Axolotl
- PEFT
- TRL library
RAG & Memory:
- RAG
- Vector databases
- Chunking
- Retrieval pipelines
- AI memory systems
- Semantic search
Agents & Workflows:
- Prompt engineering
- System prompts
- Tool calling
- Function calling
- AI agents
- Agentic workflows
- Multi-agent systems
- Browser agents
Model Types:
- VLMs
- SLMs
- Dense models
- MoE models
- Coding models
- Reasoning models
Deployment:
- Local inference
- On-device AI
- API serving
- Cloud GPUs
- Edge AI basics
Evaluation:
- AI benchmarks
- Human evals
- Cost-per-token analysis
- Speed benchmarking
- Quality benchmarking
Real-World Skills:
- Building chatbots
- Building AI copilots
- AI automation
- AI SaaS workflows
- AI coding workflows
- AI orchestration systems
- AI product thinking
Start from the absolute basics and gradually make me advanced.
Rules:
- Use simple English only
- Avoid academic jargon unless necessary
- Explain every difficult word in plain language
- Use real-world analogies and daily-life examples
- Use small code snippets when useful
- Show practical use cases
- Compare concepts side-by-side when helpful
- Teach from fundamentals first, then advanced concepts
- At the end of each topic:
- give a short summary
- give a simple mental model
- give beginner mistakes to avoid
- give a small exercise/project
I want deep understanding, not memorization."
Thank me later.
Added a DeepSeek Sparse Attention (DSA) from-scratch implementation to my LLMs-from-scratch repo thanks to an awesome new reader contrib.
With motivation, overview, and GPT-style model reference implementation as standalone example code: https://t.co/o2PMhjF0TN
Everyone is fine-tuning LLMs.
Almost nobody understands what is actually being updated inside the model.
Here are 5 techniques that change how you think about model adaptation, and what each one is actually doing to the weights:
1./ LoRA - Learn the update, not the weights
The pretrained weight W is frozen. Completely untouched.
Instead of updating W directly, two small matrices are trained =>
A ∈ ℝʳˣᵈ and B ∈ ℝᵈˣʳ, where r ≪ d
The weight update is: ΔW = BA Effective weight: W' = W + BA
The entire adaptation happens in a tiny low-rank space. W never changes.
2./ LoRA-FA - What if we freeze even more?
Same structure as LoRA. One change.
A is frozen alongside W. Only B is trained. Effective weight: W' = W + BA (A is fixed)
Half the trainable matrices of LoRA. Same core idea. Fewer parameters.
3./ VeRA - What if the matrices don't need to be learned at all?
This is where it gets interesting.
A and B are both frozen, and randomly initialized. What gets trained are just two tiny scaling vectors =>
b ∈ ℝʳ and d ∈ ℝʳ
Instead of learning the low-rank matrices themselves, VeRA keeps them frozen and learns small scaling vectors that modulate their contribution.
Initialization => b = 0, d = 1
You're not learning matrices. You're learning how to scale them.
One of the most parameter-efficient techniques on this list.
4./ Delta-LoRA - What if W itself learns from the low-rank updates?
This one is fundamentally different.
Unlike standard LoRA, the base weight W is not fully frozen. It is updated through low-rank delta propagation at every step =>
W^(t+1) = W^t + c(B_(t+1)A_(t+1) − B_t A_t)
Where c is a scaling factor.
A and B are trainable. W evolves, but guided entirely by low-rank changes.
5./ LoRA+ - Same structure. Smarter learning rates.
Identical to LoRA, freeze W, train A and B.
One change => B is assigned a larger learning rate than A. η_B > η_A
A ← A − η_A · ∂J/∂A B ← B − η_B · ∂J/∂B
A small optimization change that can make LoRA training more effective.
The core idea running through all five:
You do not always need full fine-tuning to adapt a model.
LoRA updates two matrices.
LoRA-FA updates one.
LoRA+ updates two at different speeds.
Delta-LoRA lets W evolve - guided by low-rank deltas. VeRA updates two vectors.
Same goal. Five different answers to the same question:
=> What is the minimum we actually need to learn?
That is the core idea behind parameter-efficient fine-tuning.
And now you know what is actually happening inside the model.