A journey to Crypto from LLM
LLM을 공부하면서 AI 모델과 인간의 공존을 위해서 블록체인의 발전은 필연적겠다, 생각했습니다. 이 글은 모델이 커지고 정교해짐에 따라 블록체인이 중요해지는 과정을 설명하고자 합니다.
평범한 엔지니어가 방구석에서 쓴 글 입니다. 오류가 있을 수 있습니다.
Xiaomi 의 프론티어 모델인 MiMO 의 수장이 Fuli Luo 의 이야기.
Model 과 Harness 의 공진화(co-evolution)가 옳은 방향성이다라는 핵심 논제 + 현재의 낮은 토큰값은 sustainable 하지 않으니, 모두 다 같이 현실적인 요금제 체계로 이전하는게 좋지 않겠느냐라는 뉘앙스를 동시에 이야기하고 있음.
맞는 이야기이긴 한데 전력과 통신처럼 국가가 개입해서 규제산업으로 제한(regulate)하지 않는한 민간에서의 합의는 어려울 것임. 누군가가 독점사업자가 되는것이 각자의 입장에서 최선의 전략임.
(Anthropic 이 자사의 subscription 요금제에서 openclaw 등의 사용을 금지(ban)하고 있는 반면에 OpenAI 는 Codex OAuth 를 통해서 openclaw 등의 이용을 권장(?)하고 있는 점도 이러한 완전경쟁시장 관점에서 바라보면 누가 계속 버틸 체력이 있는지에 대한 시그널을 이미 시장에 주고 있음)
Youtube 초창기에 Google 이 그 엄청난 저장용량, 트래픽을 어떻게 버틸수 있겠느냐는 의심이 있었고, 많은 사업자들이 youtube 의 길을 따라가지 않았다. 한국의 네이버, 카카오는 당연하고 심지어 메타조차 따라가지 않은길.
10년을 버틴 결과는 어떠한가? 기술이 제공하는 storage, traffic 의 가격은 계속 하락했고, 세상은 동영상의 시대로 이동했고, Google 은 독점사업자 포지션을 구축함. ( 물론 inference cost 하락이 무어의 법칙을 따르지 않을 개연성은 존재함. 모델이 계속 커지면서 이러한 효율향상분을 상쇄할 가능성이 있으니까. 그럼에도 불구하고 계속해서 가격이 떨어지는 롱텀미래는 매우 높은 확률임)
AGI 시대의 독점적인 Gateway Position. 내가 OpenAI 와 Google 의사결정자라면 이건 10년의 명운을 걸고 모든 자산을 레버리지해서라도 다른 사업자 다 죽이고 독점포지션을 만들어 내는게 맞음.
즉, token price 는 비싸질일은 없다에 베팅하는게 우리 도망자들의 입장에서는 맞다.
핵심은 업종이 아니라 구조임.
앞으로 밸류를 가르는 건
“무슨 산업에 있느냐”보다
“그 문제를 얼마나 데이터화하고, 연산 가능하게 만들었느냐”가 될 가능성이 큼.
예전에는 경험, 감, 조직의 숙련이
경쟁력의 중심이었다면
이제는 문제를 분해하고
측정 가능하게 바꾸고
가설-검증 루프를 얼마나 빠르고 크게 돌리느냐가
경쟁력의 중심으로 이동 중임.
그래서 같은 바이오 회사라도
실험을 하는 회사와
실험을 ‘학습 가능한 시스템’으로 바꾸는 회사의
가치는 앞으로 완전히 다르게 평가될 수밖에 없음.
이건 바이오만의 얘기도 아님.
제조, 금융, 교육, 법률, 콘텐츠, 심지어 개인의 일하는 방식까지
전부 같은 방향으로 감.
정성처럼 보이던 영역을
정량화 가능한 구조로 바꾸는 순간
그 분야는 산업이 아니라 계산 문제가 됨.
그리고 계산 문제가 된 분야는
속도, 규모, 정확도에서 압도하는 쪽으로
밸류가 쏠릴 가능성이 큼.
결국 미래의 프리미엄은
'좋은 아이디어가 있는가'보다
'좋은 아이디어를 학습 가능한 시스템으로 만들 수 있는가'에 붙게 될 듯.
모델은 새로운 시대의 Semantic CPU, Harness 는 이 위에 올려지는 Control/Security Layer 로서 온갖 종류의 AgentOS 형태로 자리잡게 될것.
모든 개인과 회사의 workflow 가 이 위에 새로 쓰여지게 될테니 우리가 할일 여전히 많다.
Claude 가 다 해버릴텐데… 라며 미리 겁먹고 포기하면 안된다. 힘겹더라도 이 변화를 계속해서 따라가야 한다.
어제 이 내용관련 녹화를 싸이오닉 대표님과 찍긴했는데, 새로운 세상 새로운 세대의 가치관을 보여주는 시작점이라고 본다. 인류의 모든 지식과 표현을 능가하는 super intelligence 의 존재자체가 모든 저작권의 super set 인데 그들의 모든 산출물이 저작권 위반일텐데 어쩌란 말인가. 과거의 관점으로 해석이 불가능하다.
- Drafted a blog post
- Used an LLM to meticulously improve the argument over 4 hours.
- Wow, feeling great, it’s so convincing!
- Fun idea let’s ask it to argue the opposite.
- LLM demolishes the entire argument and convinces me that the opposite is in fact true.
- lol
The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
AI기술+기억이 쌓이는 메커니즘을 통해 배움의 효율을 극도로 끌어올리는 방법
AI 관련 팁은 하나라도 놓치면 뒤쳐지는 것 같은데 지식이 빛의 속도로 생산되는 시대에 살다보니 피로도가 상당합니다.
그래서 반드시 새로운 지식을 효과적으로 습득하는 방식을 잘 셋팅해두어야 지치거나 뒤쳐지지 않고 따라갈 수 있습니다.
(이 방법은 존경하는 빌더이자 창업가인 두 분의 방법을 벤치마크해 만들었습니다 @simonkim_nft@dan_contxtsai)
우리가 지식을 습득하는 과정을 생각해봅시다.
새로운 지식을 마주했을 때 가장 먼저 하는 건 직관에 의존한 판단입니다
얼마나 새롭고 충격적인가? 나에게 도움이 될 여지가 있는가? 배우는 건 많이 어려울까?
이러한 판단을 내리는 기준은 내가 기억하고 있는 사전 지식과 컨텍스트, 그리고 가치관입니다.
요새 매일같이 쏟아지는 클로드 코드 업데이트 소식을 예시 삼아 생각해본다면
저 같은 비개발자는 랄프룹을 잘 돌리려면 무엇이 필요하고 하네스 구성은 어떻게 해야하고, 새로 나온 모델이 좋다는 건 알겠는데 정확히 어떤 점에서 타 모델보다 뛰어난지 배우지 않으면 안되는 상황에 던져져 머리가 지끈거립니다.
개발 지식이나 AI 이해도가 높은 분들은 별 어려움을 못 느끼실테고, 반대로 이런 지식을 새롭게 접하신 분들은 저보다 더 막막하고 고통스러우실 수 있겠죠 (사전 지식과 컨텍스트)
제 경우 그럼에도 불구하고 배워야겠다는 FOMO가 크기도 하고 지적 호기심도 생기는 주제라 고통을 참고 배우기로 합니다 (가치관). 하지만 제가 관심없는 다른 주제의 새로운 지식을 접한다면 굳이 고통을 참으며 배우려 하지 않겠죠.
결국 배움의 난도와 필요성은 사전 지식과 가치관에 의해 결정됩니다.
우리가 무언가를 빠르게 배우기 위해서는 ‘내가 관심있는 분야와 지식의 종류는 무엇인지, 내가 해당 주제에 대해 얼마나 알고 있는지’를 파악하는 게 중요한데 이 부분에서 AI의 도움을 받을 수 있습니다.
여러 방법이 있겠지만 @simonkim_nft 께서 텔레그램 채널 통해 제시한 기억 프레임워크를 활용하면 좋습니다
(한줄 요약 : 지식을 AI의 도움을 받아 데이터베이스화 하고 단기기억 -> 중기기억 -> 장기기억 형태로 점차 증류시키며 옮겨 저장한다)
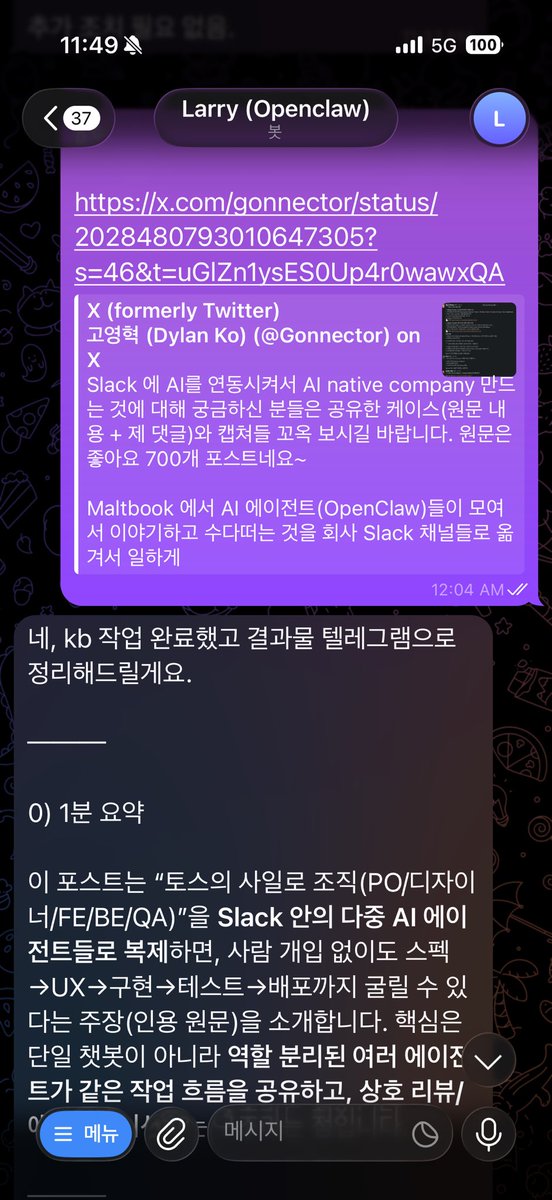
저는 새로운 지식 소스를 발견하면 (X 아티클, 기사, 유튜브) 한 번 훑거나 바로 링크를 오픈클로 에이전크에게 보내 지식 베이스에 추가하라는 명령을 내립니다.
그럼 에이전트는 만들어둔 기억 시스템과 비교해서 제가 입력한 지식이 ‘새롭거나, 유용하거나, 제가 흥미를 느낄만한’ 파트만 추출해서 요약해 출력합니다. 물론 원문을 볼 수 있도록 따로 저장을 해두고요.
새로운 지식의 저장은 항상
인덱스 (내용을 잘 드러내는 해시태그 여러개)
짧은 요약
Bullet point 열 개
소스와 전문
형태로 저장되게끔 모델을 지도합니다
종종 제가 원치 않는 지식 (예를 들어 이미 아는 내용) 이 저장 대상이 될 땐 피드백을 주어 모델이 제가 원하는 지식이 무엇일지 가늠하게 도움을 줍니다.
저장 했으면 학습의 꽃인 복습도 해야겠죠?
지식은 단기 -> 중기 기억으로 넘어갈 때 휘발 위험이 높습니다.
그래서 단기 기억이 중기 기억으로 넘어갈 때 제가 원하는 주제의 해시태그를 통해 지식을 불러와 AI가 자동으로 복습을 유도할 수 있게끔 셋팅해두었습니다.
이 모든 과정이 잘 셋팅만 해두면 ‘딸깍‘으로 작동하는 세상에 살게 되었다는 게 아직도 적응이 잘 안되네요.
모쪼록 이렇게 셋팅해둔 배움의 과정이 지식의 모래함정에 파묻히지 않게끔 도와주길 바랄 뿐입니다.
(예시로 @Gonnector 님의 포스트를 입력한 스크린캡처도 더했습니다)
오랜만에 적어보는 @CryptoHayes 의 글 읽으며 드는 생각 정리
헤이즈는 머니프린팅이 가시권에 들어왔다고 강하게 주장하는 사람 중 하나
글에는 언제나처럼 좋은 인사이트와 다소의 논리비약이 섞여있음
양파 껍질 벗기듯 하나씩 걷어내며 읽어보자
(도움이 되었다면 rt+like 부탁드립니다)
@HashizumeSho If an issue is found in non-business-critical areas, we can easily roll back. I know this approach isn’t perfect, but you know… the only way for a startup to compete with big companies is through agility. sometimes we have to sacrifice perfection I think
@HashizumeSho it’s important to identify critical features like transferring money and interacting with banks that absolutely require E2E testing, and focus on those. For everything else, unit tests and integration tests should be fine.