We have many names to describe personal tools. Malleable software speaks to how it behaves. Home-cooked software speaks to who makes it. I wanted a name that speaks to something deeper: how it feels.
Perfect Software.
I mean “perfect” in the way I mean a “perfect coffee”.
BREAKING: Google is planning to release 32 million mosquitoes across Florida and California.
The company has asked the EPA for permission to proceed, with the public given until June 5 to respond.
The mosquitoes are infected with Wolbachia bacteria, which stops them from reproducing and slowly collapses the wild population from within.
Google's previous Debug Project trial in California's Central Valley nearly eliminated mosquitoes from three test sites entirely. A separate trial in Singapore cut dengue cases by 70% within 12 months.
Google has now released over 1 billion mosquitoes across four continents. This new proposal is the largest deployment in US history.
Another technique to make it harder for people to get out..
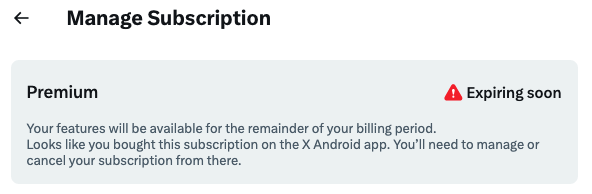
"Looks like you bought this subscription on the X Android app. You'll need to manage or cancel your subscription from there"
If a subscription system were to built like this in a system design interview, coupled with platforms, I'm pretty sure I'd fail on multiple counts of violation of best practices.
What seems sillier is that the two camps arguing as if it's an either/or, when both are true because people losing jobs and people getting jobs aren't exactly the same ones.
Not even because the other person is busy, but it has always felt disingenuous to me to start with small talk or wishes, when I clearly am reaching out for something else.
It has always felt right to open with what I'm reaching out for, ending with wishes or asking about them or family.
In emails, put the ask first and the well wishes at the end. Busy people mostly just want to know what you want from them and how they can help and want to know it as quickly as possible.
What in the world did we just see!
The 2 hour marathon barrier has been broken. Three guys went under the old world record...
Sabastian Sawe just ran 1:59:30 with crazy negative splits, closing the last half in 59:01....faster than the American Record in the half.
One of the most mind blowing performances we've seen. How did we get here?
Every breakthrough is a mixture of belief and progress.
It takes folks daring to see what's possible, surrounding themselves with a quality team and doing the work to give themselves a shot.
You've got to bet on yourself in a big way.
When asked whether he believed he could run a sub-2-hour marathon before the race, Sawe answered with one word:
"Yes."
Let's get the obvious out of the way. Performance enhancing drugs are the legitimate question mark to every breakthrough.
So Sawe did as much as he could about taking that off the table.
He and his team asked to be tested all the time. His sponsor put up 50K to the Athlete Integrity Unit. The tests are run independently, no advance notice. Over a 2 month stretch, he went through 25 drug tests.
There's always a doubt. There has to be given what we know. Hopefully there's transparency in the results. But hats off to Sawe for addressing it:
"I want to prove that I am clean when I set foot at the start line."
But how'd we actually get here where two guys went sub 2 in the same race?
1. Shoe tech
We've had a revolution in shoe technology that boosts running economy.
For years shoe companies said their shoe would make you faster and was mostly marketing. Until 2016, when it actually did.
Initial research showed a 3-4% saving in economy, while subsequent work has shown it's highly variable.
Now, it's a matching game. Find the perfect shoe for your form and you can get a big boost.
Normally, it takes years of lots of miles and strength training to boost economy.
But now we get that instant boost that not only helps boost performance but often leaves us feeling less beat up in the later stages of the marathon.
So we get a little bit less hitting of the wall...
2. The fuel
For a long time, fueling was limited by biology. You can only take in and process so much.
Then in the 2000s, researchers found if we mixed sugars, we can boost intake because they're processed differently.
Then recently, Maurten found if you use a hydrxogel, you boost utilization without GI distress anymore.
We've gone from pushing 60g/hr to 120g/hr in a few decades.
Again...less bonking.
3. Depth
A few decades ago, you spent your career racing on the track and then once your speed started to fade a bit you went to the marathon.
Now, many skip right to the marathon. That's where the money is.
And with the economy boost from the shoes, you can make that jump quickly.
More depth of talent means more competitors in their prime pushing barriers.
4. Belief
Even with the shoes and tech, a few years ago sub 2 hours seemed a long way off, until Kipchoge pushed that barrier in a series of time trials.
Yes, they weren't official races and had contrived pacing. But it absolutely shifted everyone's thinking on what is possible.
A generation of runners saw Kipchoge go for it.
Our prediction of what is possible changed.
It's mind blowing how far we've come in such a short time.
What once seemed decades away, just got smashed twice in the same race.
Hats off to Sawe, especially for addressing the scourge of doping and showing folks what is possible with a lot of hard work, some crazy belief, and some fortuitous advances.
THE FIRST MAN IN HISTORY TO BREAK 2 HOURS IN A MARATHON!!!🤯🤯🤯
Sabastian Sawe 🇰🇪 has just shattered the World Record at the London Marathon, running 1:59:30!!!
He makes history as the first man to officially break 2 hours in the marathon.
Yomif Kejelcha 🇪🇹 in his debut ran 1:59:41 to become 2nd fastest alltime, while Jacob Kiplimo 🇺🇬 finished in 2:00:28.
All under the previous World Record.
My thoughts on "Your harness, your memory" from the LangChain Blog
The post argues that memory is a critical part of the harness, so anyone selling harness without memory baked into it is creating a lock-in that's not visible just yet. It works today because memory is not as well-understood widely and most current interactions with LLMs are stateless. But as agent personality, personalization and long-term memory become more important, it's important that people/organizations own their memory, own their harness.
The dominant players, Anthropic, Google, OpenAI, will want to own the memory/harness - that's what you get from features like Claude Managed Agents. Not only is the model a blackbox but so is the entire persisted state that makes a model useful.
It reminds me of the same problem at the semantic layer: most cloud data warehouses, BI tools have had their own semantic layers, which is what makes analytics tick. Vendors would want it to be on their stack. LookML is a good example and is the most attractive layer of Looker. OSI, Open Semantic Interchange, is looking to change that. So you can take the semantic layer with you to any warehouse/BI tool vendor you wanna use, at least that's the promise.
But memory and agent harness are a tighter form of lock-in than the semantic layer. Semantic layer was largely static and defined by humans, updated occasionally. Memory is deeply dynamic in nature. It's seeded by you, but takes a life of its own over time.
Deep Agents is LangChain's answer - an open-source agent harness, that works with other open-source projects like LangChain and LangGraph. It's "model-agnostic," which is better than the closed ecosystems of the bigger players, but it's not as open as the author makes it sound. Deep Agents is built on Lang*(Chain/Graph) stack, which although open-source, is all owned by the same company. It's not a true interoperable solution - it's an emergent moat, where the lock-in is organically formed, rather than planned, as the agent performance is increasingly tied to whoever controls the "frameworks, runtimes, and harnesses", as Harrison himself makes a distinction of their offerings.
How it'll likely play out: You use a model provider with Deep Agents. You wanna switch models tomorrow - you can keep the harness, switch the models. Good. But your agent harness is only as good as LangChain and LangGraph, which define the primitives and the persistence/memory layer respectively. Memory also encompasses the logs generated from agent behavior, making it dependent on LangSmith, LangChain's commercial observability product. Over time, the harness works - or works better - only with Lang ecosystem, which creates harness lock-in. You can switch model providers, but can't switch your harness ecosystem. How the agent summarizes, compacts information, what it remembers or discard - are all at the mercy of the Lang stack.
Although it always comes with the promise of self-hosting and customization for your needs, most organizations will not or cannot do it. This has always been true for critical infrastructure, but is especially true in the LLM ecosystem given the novelty, the limited understanding most organizations have of how agents work under the hood, and the speed at which this space is evolving.
Managed solutions are likely the end-game.
So the play here seems to be to start from open-source - rather than closed-source like the dominant players - to gain market share, and convert that into structural lock-in, after significant customer adoption.
When I think about my writing as something that I'd like my kids to read when they grow up, suddenly the stakes become much higher. The topics I write about, what I want to say, how I write it, how much time I spend on each - the whole mindset changes.
Surprisingly, it also helps shift focus from thinking/worrying about what works on the Internet to what, if anything meaningful, I have to say.
As I interact more with Claude, I'm learning a few phrases in English that are good, novel to me, sound deep, but have an AI smell. "Worth sitting with" is one of those. "That insight is worth sitting with" .. "That tension is worth sitting with."
I hadn't encountered them much before LLMs, so their prevalence in my conversations now probably speaks to the kind of topics I read/learn about now, those that have gotten easier to do with LLMs - philosophy, sociology, anthropology, neuroscience, biology, psychology, and research papers.
@itsolelehmann Obsidian just makes it easy to work with markdown files.
At the end of the day, you need files over app, as @kepano calls it, and @obsdmd is an embodiment of that philosophy.
@stevemagness When you say most adults can't sprint, what do you mean exactly? I'm sure they are trying to run as fast as they can, even if they are relatively slow, but what exactly makes it a Sprint? Genuinely want to know..
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
@vasantshetty81 The mass layoffs are because of AI, yes, but not because of the capabilities of the models, or that AI can do what those people could.
It's more to make a budget for spending on AI.