Received a call from President Trump and had a useful exchange of views on the situation in West Asia. India supports de-escalation and restoration of peace at the earliest. Ensuring that the Strait of Hormuz remains open, secure and accessible is essential for the whole world. We agreed to stay in touch regarding efforts towards peace and stability.
@realDonaldTrump@POTUS
Looking at the market crash that happened today, it’s going to be a rough few weeks for the global economy. Once the emotions settle in we may again be at the beginning of the start of another Bull run.
Let’s watch.
❤️ We are partnering with @MiniMax_AI to give Ollama users free usage of MiniMax M2.5 for the next couple of days!
ollama run minimax-m2.5:cloud
Use MiniMax M2.5 with OpenCode, Claude Code, Codex, OpenClaw via ollama launch!
OpenCode:
ollama launch opencode --model minimax-m2.5:cloud
Claude:
ollama launch claude --model minimax-m2.5:cloud
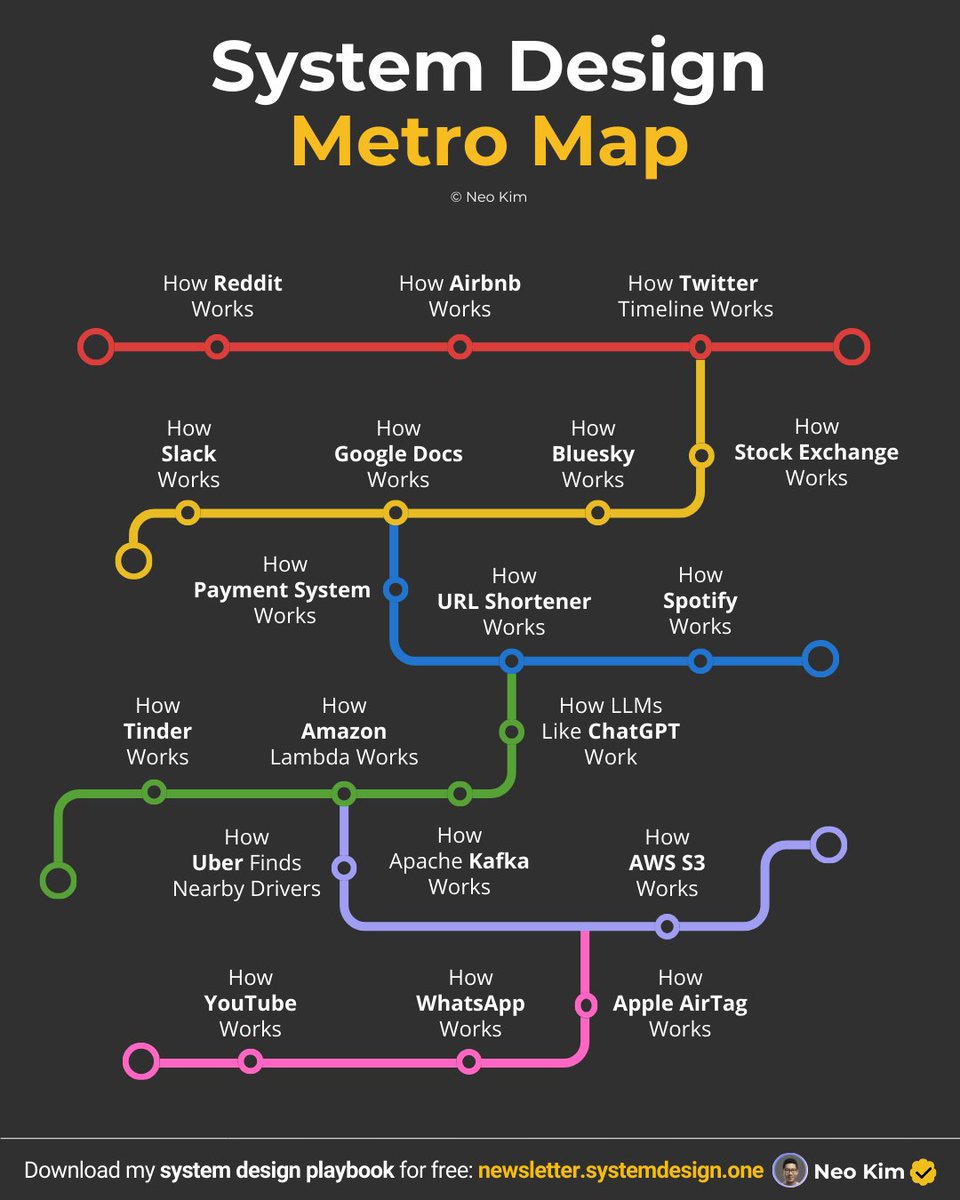
If you want to become good at system design, learn these 19 case studies (save this):
1 How Stock Exchange Works:
↳ https://t.co/iFNSX9TM9O
2 How Payment System Works:
↳ https://t.co/ARiLxGR43G
3 How YouTube Works:
↳ https://t.co/kHk3g6jz6t
4 How Google Docs Works:
↳ https://t.co/W57IkAjXpT
5 How Kafka Works:
↳ https://t.co/8rOy9KgCMo
6 How URL Shortener Works:
↳ https://t.co/tGndgdhH0V
7 How WhatsApp Works:
↳ https://t.co/VScq8QwHMr
8 How Airbnb Works:
↳ https://t.co/Bi5SAjfv5S
9 How Spotify Works:
↳ https://t.co/BxrH3oHIFS
10 How Slack Works:
↳ https://t.co/eIo29uOQOJ
11 How Reddit Works:
↳ https://t.co/o6Pw2hhj3T
12 How Bluesky Works:
↳ https://t.co/2rLYlRlky0
13 How Tinder Works:
↳ https://t.co/4E1zfgfvlw
14 How Twitter Timeline Works:
↳ https://t.co/pF2RYmPaIG
15 How Uber Finds Nearby Drivers:
↳ https://t.co/kJ2t8dtmch
16 How Amazon Lambda Works:
↳ https://t.co/lx0BjeSRZt
17 How Amazon S3 Works:
↳ https://t.co/iReWAEHwmj
18 How Do Apple AirTags Work:
↳ https://t.co/upWcgsXwKh
19 How LLMs Like ChatGPT Actually Work:
↳ https://t.co/5lCKxq2g4N
What else should make this list?
——
👋 PS - Want my System Design Playbook for FREE?
Join my newsletter with 200K+ software engineers right now:
→ https://t.co/ByOFTtOihX
———
💾 Save this for later & RT to help other software engineers ace system design.
👤 Follow @systemdesignone + turn on notifications.
New art project.
Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further.
https://t.co/HmiRrQugnP
For 38 years, computer scientists believed Dijkstra's algorithm was optimal for sparse graphs.
The logic seemed airtight:
Dijkstra sorts vertices by distance.
Sorting has a lower bound of O(n log n).
Therefore shortest paths can't be faster.
5 researchers proved the assumption wrong.
The trick: combine Dijkstra's priority queue with Bellman-Ford's dynamic programming. Divide and conquer on vertex sets. Shrink the frontier.
Result: O(m log^(2/3) n)
First improvement for directed graphs since Fibonacci heap in 1987.
Tsinghua. Stanford. Max Planck. 17 pages.
WTF DeepMind. 🤯
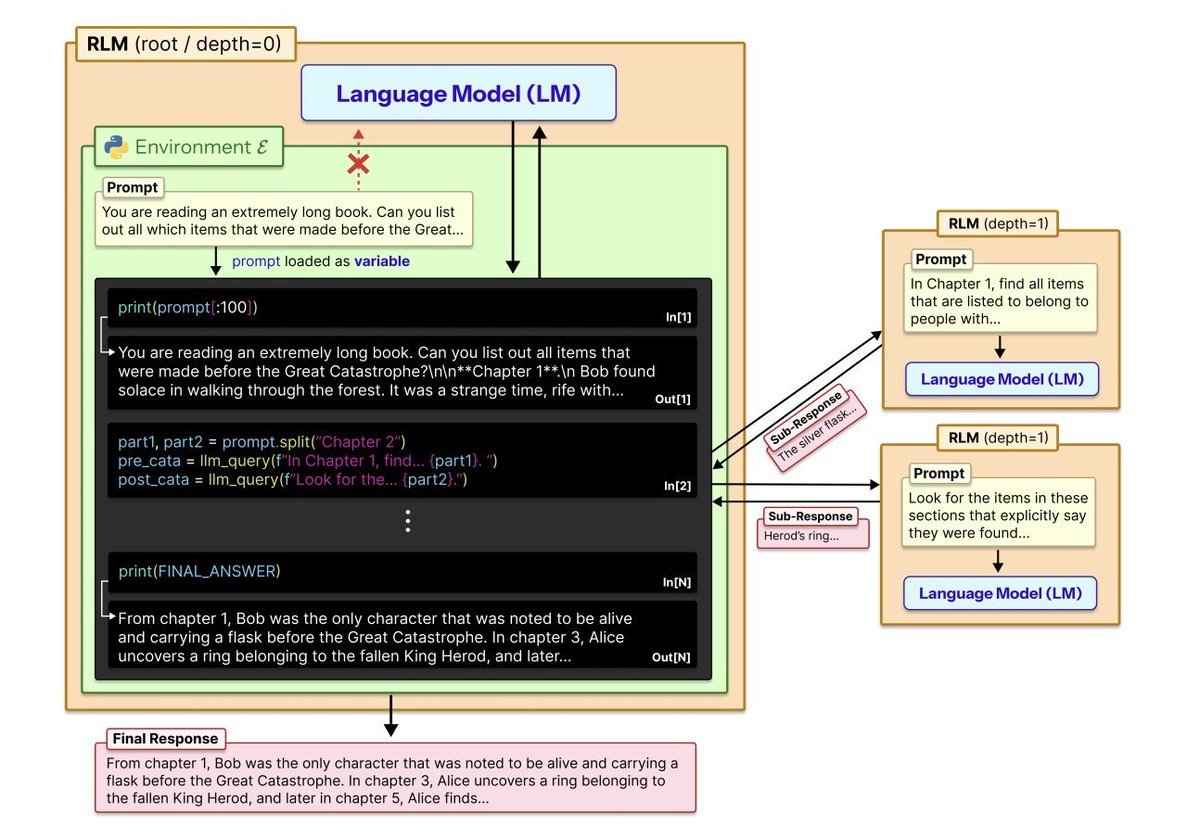
They built an AI that doesn't need RAG, and it has perfect memory of everything it's ever read.
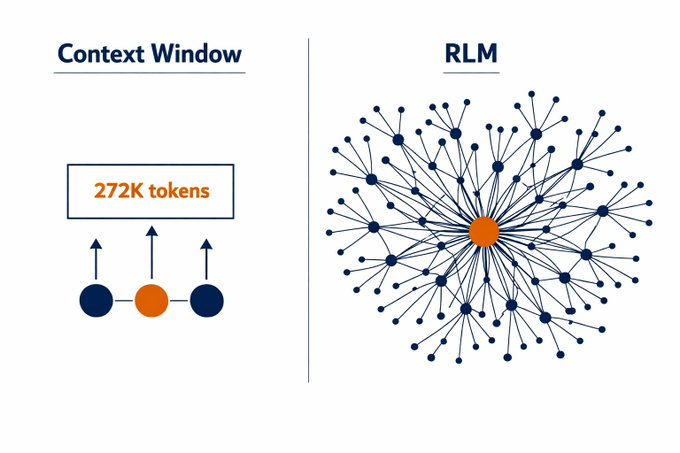
It's called Recursive Language Models, and it might mark the death of traditional context windows forever.
- Everyone's been obsessed with context windows like it's a dick-measuring contest.
We have 2M tokens! No, WE have 10M tokens!
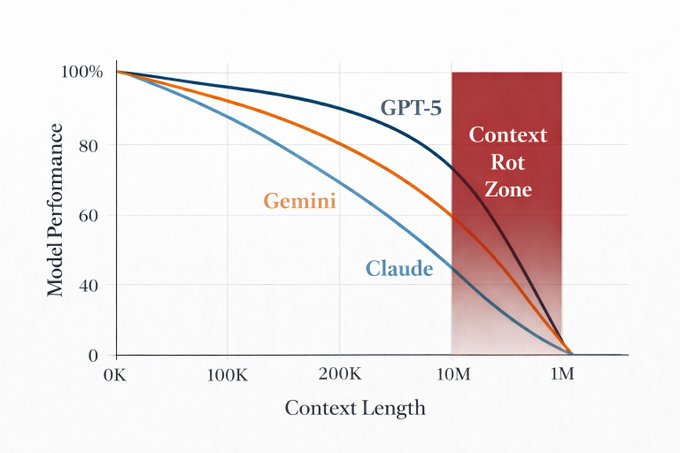
Cool. Your model still forgets everything past 100K. They call it "context rot" and every frontier model suffers from it.
- RAG was supposed to save us.
Just retrieve the relevant chunks, stuff them in the prompt, problem solved.
Except RAG is fundamentally broken for anything that actually matters.
It can't handle tasks where you need to look at multiple parts of a document simultaneously.
- Recursive Language Models flip the entire script.
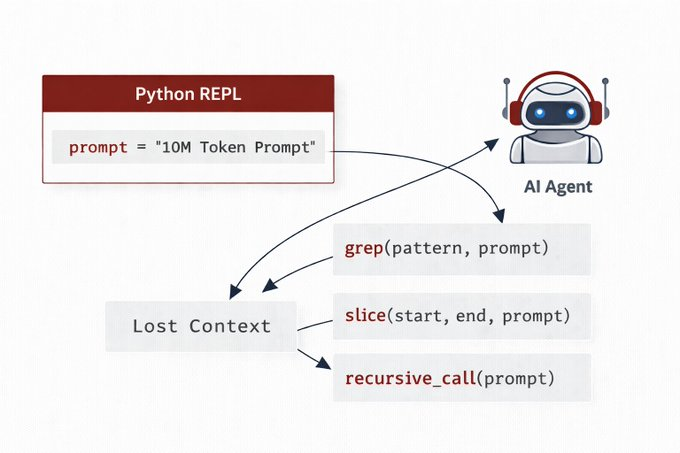
Instead of shoving 10M tokens directly into the model, you load the prompt as a variable in a Python REPL.
The model writes code to search, slice, and recursively call itself on relevant snippets.
It's so obvious in hindsight.
- RLMs let AI do exactly that.
The prompt isn't processed linearly it's an environment the model navigates programmatically.
- The results are absolutely disgusting:
GPT-5 base model on multi-document research: 0% (literally couldn't fit it)
GPT-5 with RLM: 91%
On information-dense reasoning:
Base: 0.04%
RLM: 58%
That's not incremental improvement.
That's a different capability emerging.
- What's wild is the models figured out their own strategies without being trained for this.
They started using regex to filter context without reading it all. Breaking tasks into recursive sub-calls. Verifying answers by querying themselves again.
Zero special training.
Just emergent behavior.
- The cost situation is actually better than you'd think.
Yeah, some trajectories get expensive because the model keeps recursing.
But the median RLM run is cheaper than the base model.
Why? Because it only reads what it needs instead of ingesting 10M tokens upfront.
- This completely changes what's possible:
- Analyzing entire legal codebases
- Understanding million-line repositories
- Synthesizing hundreds of research papers
- Processing years of medical records
All of these were theoretically possible but practically broken. Not anymore.
- The researchers tested on GPT-5 and Qwen3-Coder with zero modification.
No fine-tuning.
No special training.
Just give them a REPL environment and recursive access.
That means you can use this approach right now with existing models.
- Here's the kicker: current models are terrible at this compared to what's possible.
They make dumb decisions. Repeat work. Sometimes compute the right answer and then... ignore it.
Imagine explicitly training models to think recursively. We're still at the starting line.
- Everyone's been focused on the wrong problem.
The question isn't "how do we cram more tokens into context windows"
It's "how do we let AI intelligently navigate unbounded information."
RLMs just proved you don't need bigger windows.
You need smarter navigation.
paper : https://t.co/8mcm19V2E1
Vector search is not always the answer.
A 30-year-old algorithm with zero training, zero embeddings, and zero fine-tuning still powers Elasticsearch, OpenSearch, and most production search systems today.
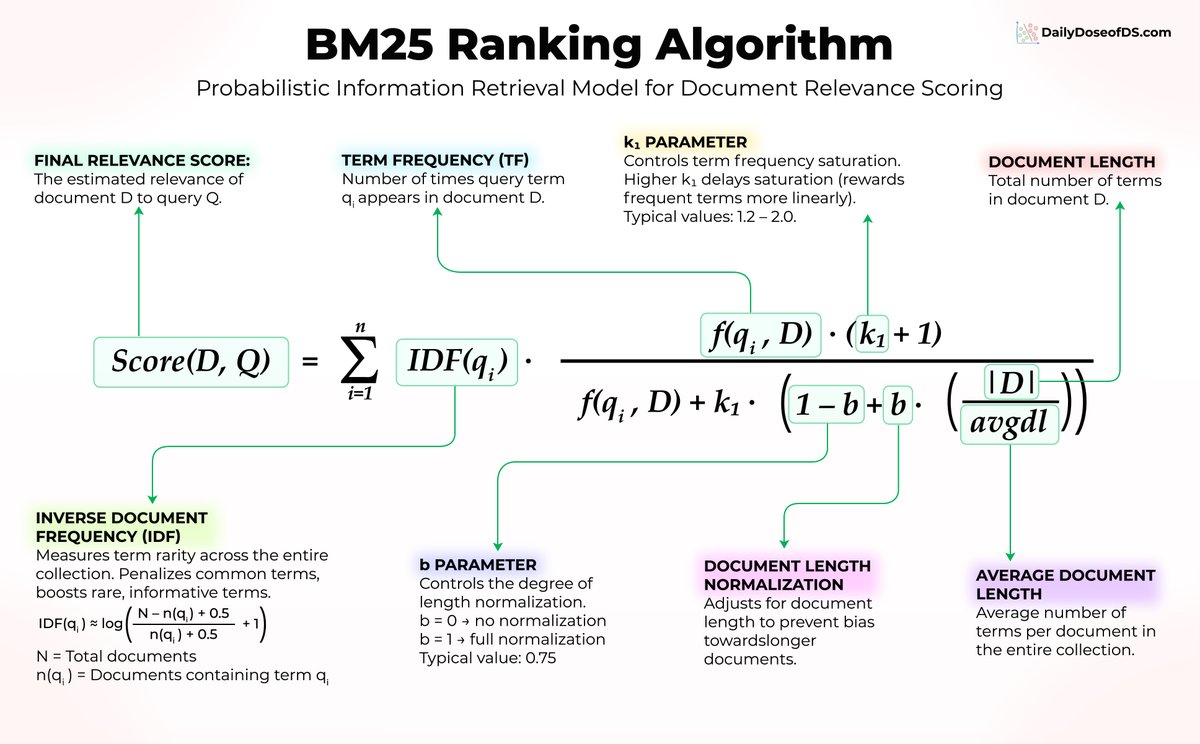
It's called BM25, and it's worth understanding why it refuses to die.
Let's say you're searching for "transformer attention mechanism" in a library of ML papers.
BM25 scores documents using three core ideas:
1) Word rarity matters more than word frequency
Every paper contains "the" and "is" so those words carry no signal.
But "transformer" is specific and informative, so BM25 gives it a much higher weight. In the formula, this is captured by IDF(qᵢ).
2) Repetition helps, but with diminishing returns
If "attention" appears 10 times in a paper, that's a strong relevance signal. But the jump from 10 to 100 occurrences barely moves the score.
BM25 applies a saturation curve controlled by f(qᵢ, D) and the parameter k₁, preventing keyword stuffing from gaming the results.
3) Document length gets normalized
A 50-page paper will naturally contain more keyword hits than a 5-page paper.
BM25 adjusts for this using |D|/avgdl, controlled by parameter b, so longer documents don't dominate the rankings just because they have more text.
Three ideas. No neural networks. No training data. Just elegant math that has stood the test of time.
Here's the part most people overlook: BM25 excels at exact keyword matching, which is something embeddings genuinely struggle with.
When a user searches for "error code 5012" vector search might return semantically similar error codes. BM25 will surface the exact match every time.
This is exactly why hybrid search has become the default in top RAG systems.
Combining BM25 with vector search gives you semantic understanding AND precise keyword matching in a single pipeline.
So before you throw GPUs at every search problem, consider that BM25 might already solve it, or at the very least, make your semantic search significantly better when the two are combined.
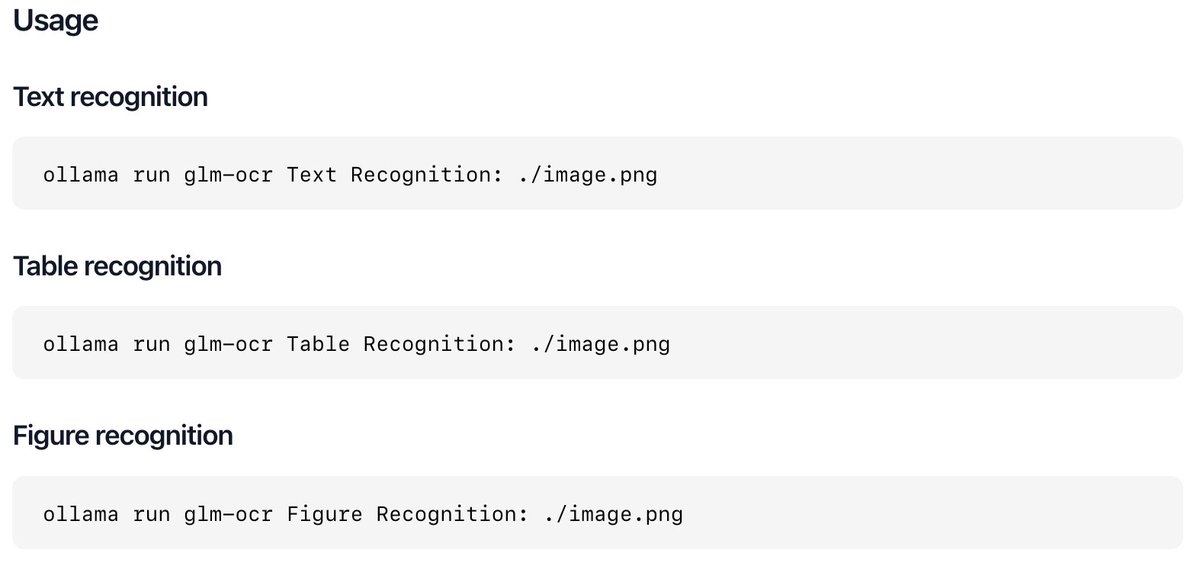
ollama pull glm-ocr
All local. You own your data.
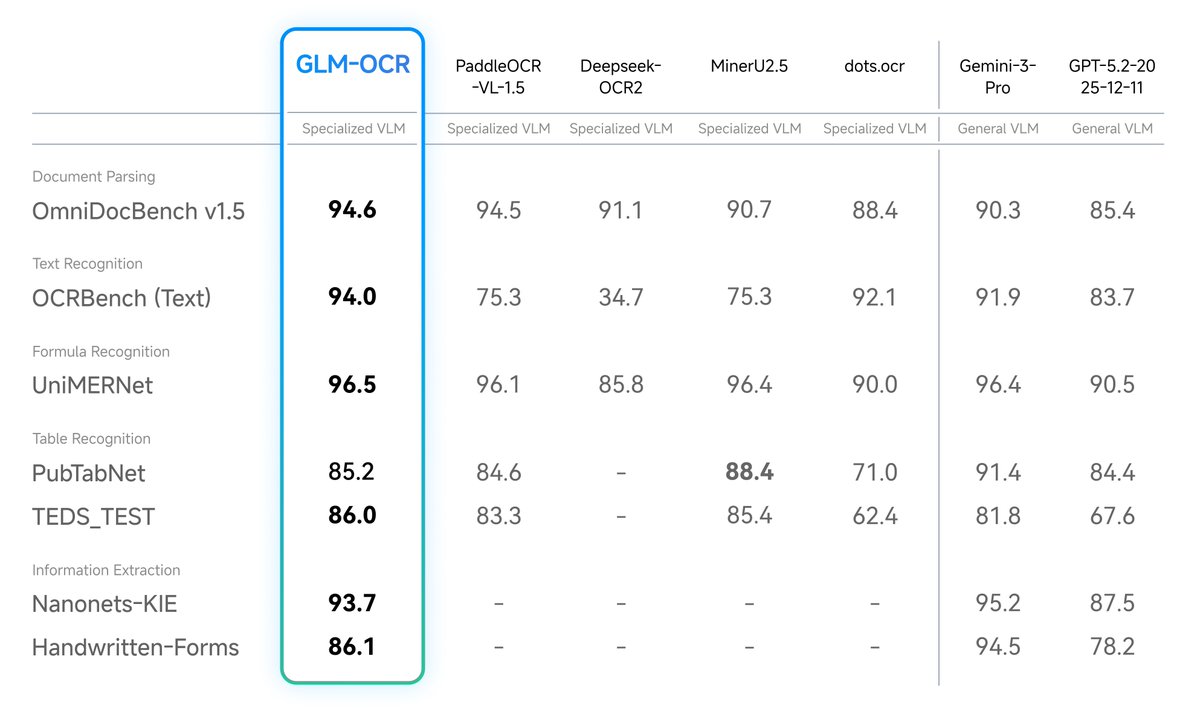
GLM-OCR delivers state-of-the-art performance for document understanding.
Use it for recognizing text, tables, and figures, or output to a specific JSON format.
Drag and drop images into the terminal, script it or access via Ollama's API.
Introducing GLM-OCR: SOTA performance, optimized for complex document understanding.
With only 0.9B parameters, GLM-OCR delivers state-of-the-art results across major document understanding benchmarks, including formula recognition, table recognition, and information extraction.
Weights: https://t.co/vqIBgBCXYi
Try it: https://t.co/Ld7H8Pasls
API: https://t.co/xVLNG0XSfP
As a Backend Engineer in 2026 aiming for Staff, please learn:
1. One language deeply (Go/Rust/Java)
Not “I can write APIs”, but runtime model, memory, concurrency, profiling, GC behavior (if any), and how to read stack traces like a native.
2. Data modeling and storage fundamentals
Relational modeling, constraints, isolation levels, indexes, query plans, locks, deadlocks, migrations, backup/restore, partitioning. Most “scaling” problems are schema + query shape problems.
3. Distributed systems basics that actually show up in prod
Consistency vs availability, timeouts, retries, idempotency, backpressure, message ordering, leader election, clock skew, eventual consistency, and what happens during partial failures.
4. API design and contracts
Versioning, pagination, filtering, error models, idempotency keys, rate limits, backwards compatibility, and how to avoid breaking mobile clients for months.
5. Performance and capacity engineering
Latency budgets (p50/p95/p99), tail latency causes, load testing, queueing theory intuition, connection pools, CPU vs IO bound, and capacity planning with real numbers.
6. Reliability engineering
SLOs/SLIs, incident response, postmortems, alerting that does not spam, error budgets, graceful degradation, feature flags, circuit breakers, bulkheads.
7. Observability like a pro
Structured logs, metrics, tracing, correlation ids, RED/USE metrics, sampling strategies, and how to debug “it is slow sometimes” without just guessing.
8. Security fundamentals
AuthN/AuthZ, least privilege, secrets management, token expiry, OWASP basics, SSRF, injection, secure defaults, audit logs, threat modeling for your own services.
9. Messaging and async systems
Kafka/Rabbit/SQS semantics, at-least-once vs exactly-once (and why “exactly once” is mostly a marketing term), consumer groups, retries, DLQs, replay, dedupe.
10. Caching with correctness
Cache invalidation strategies, TTLs, stampede protection, read-through/write-through, negative caching, and when caching makes bugs harder than latency.
11. Infrastructure literacy
Linux basics, networking (DNS, TCP, TLS), containers, k8s concepts, autoscaling, deployment strategies (blue/green, canary), and what your cloud bill is really paying for.
12. System design, but with tradeoffs
Designing is picking pain. Learn to write down constraints, failure modes, data growth, and operational cost. Staff is judged on tradeoffs, not diagrams.
13. Codebase leadership
Design docs, RFCs, review quality, mentorship, aligning teams, reducing complexity, owning a subsystem end-to-end, making boring systems that do not wake people at 2am.
14. Pick ONE domain to go deep
Payments, search, streaming, identity, infra, data platform, etc. Staff engineers are “the person for a hard area”, not generic API writers.
Stop hopping stacks every month. Pick a lane, build proof of reliability, and become the person people call when prod is on fire. That is Staff.