I have the memory of a goldfish, which is not ideal when running many ML experiments in parallel that take hours or days.
I would launch an experiment with a clear reason, come back later, and have to reconstruct why I had run it in the first place.
So a month ago I created a /file skill for filing ML experiment results from claude into my repo.
The inspiration was partly @karpathy’s LLM Wiki idea and, behind that, Vannevar Bush’s memex: a personal research memory built around linked trails of evidence.
Every experiment runs with a pinned code ref, a pipeline ref, and an explicit hypothesis, and produces an HTML report in S3 with everything needed to understand and reproduce it: config, metrics, tables, visualizations, timing, and machine resource profiles.
Then I /file the report.
Claude fetches the most recent comparable reports, summarizes the code changes since the last run, evaluates the hypothesis, extracts key findings, and suggests the next experiment.
In parallel, I review the report myself and dictate notes: what surprised me, what I trust, what looks suspicious, and what I think we should try next.
Claude consolidates my findings with its own, opens a PR with a markdown summary, links to the full report, records the important diffs, and files tickets for follow-up experiments.
Now that I’m ~100 experiments deep, I can ask for:
* annotated timelines of key metrics
* roadmaps for improving velocity
* roadmaps for maximizing lift
* analyses of failures to find patterns
All of these become docs in the repo and provide context for myself and agents.
It feels like there is a kind of recursive knowledge growth happening alongside the code: each experiment improves the model, but it also improves the shared understanding of the research problem.
And, ultimately, it makes the research process more fun!
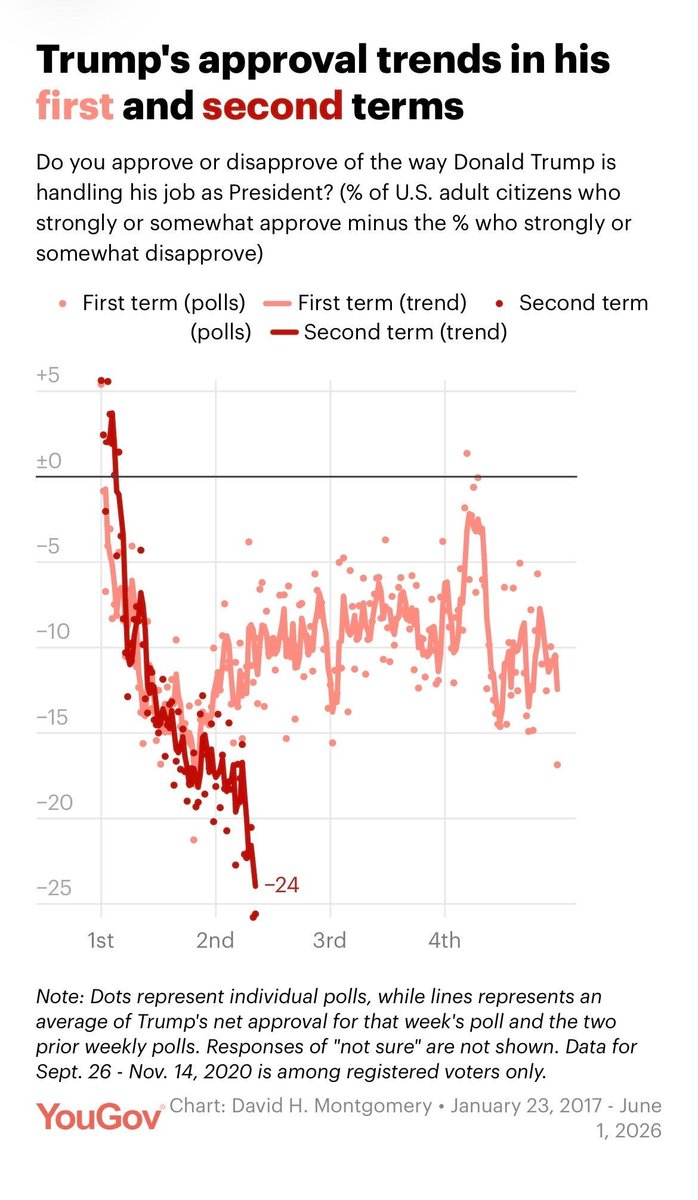
This chart from the latest YouGov/Economist poll result is really quite stunning. Trump’s net approval is not only deeply negative, but about 15(!!) points below what it was at this point in 2018, putting the GOP deeper in blue wave territory now vs then https://t.co/56dl8abnaL
Data from Strength In Numbers/Verasight
Support for initial military action against each adversary in the poll taken as close as possible to the day after the action
Afghanistan (2001)
Support 92%
🟥Republicans 96%
🟦Democrats 90%
—
Iraq (2003)
Support 72%
🟥Republicans 93%
🟦Democrats 59%
—
Iran (2026)
Support 34%
🟥Republicans 69%
🟦Democrats 10%
Link to article: https://t.co/3ky6YiGGzi
I love how the FDA statement on Tylenol looks like the top was written by RFK Jr and the bottom was written by very annoyed scientists overruling him
Top: Tylenol associated with increased risk of autism and ADHD
Bottom: By the way, the quality of evidence for this guidance is godawful and all other pain-relief medicines are terrible for the fetus!
I think this is right. What's more useful than creating a "Democratic Rogan" is just Democrats being more chill about shit, everything else flows from there!
https://t.co/o0IMk613Tw
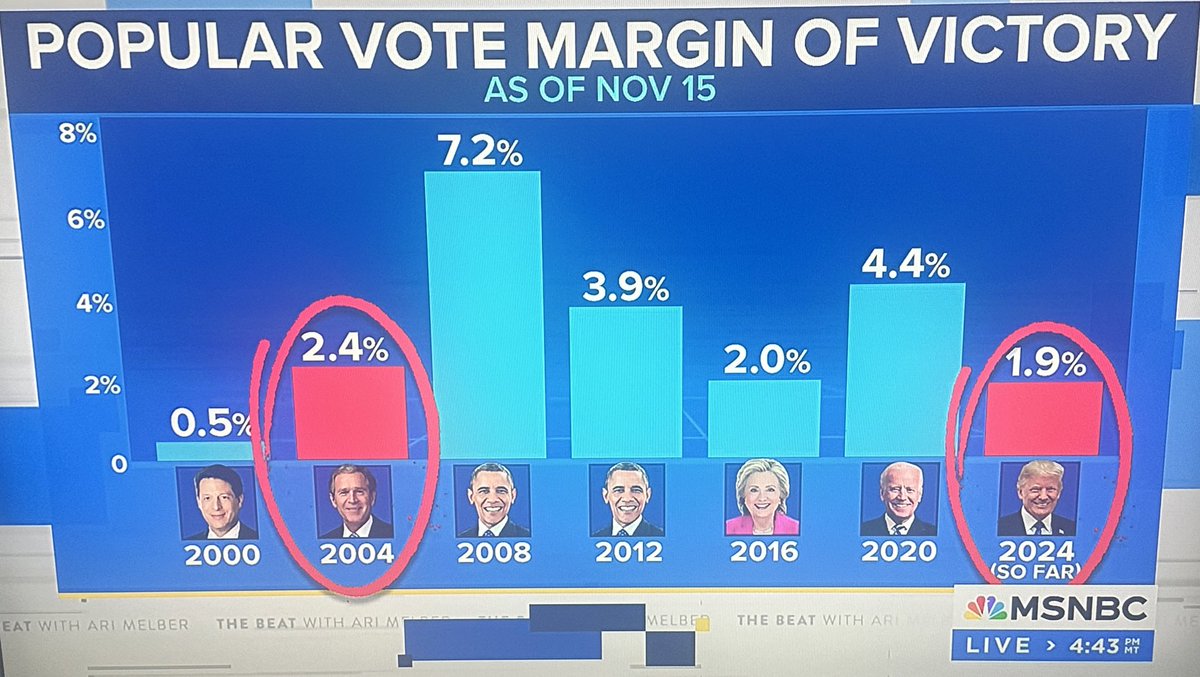
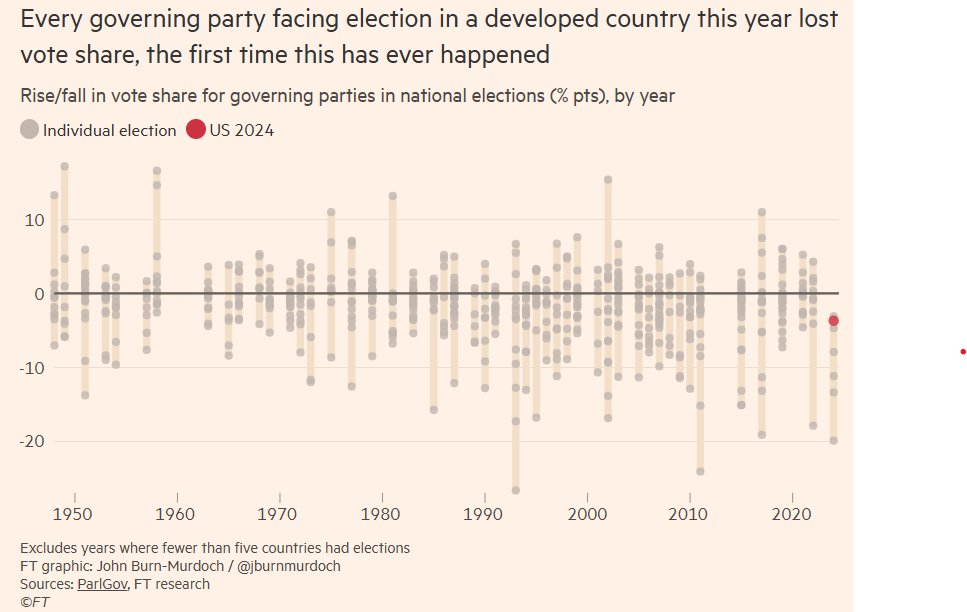
Lots of post-mortems today & questioning of what Biden/Harris did wrong, but this is the key chart for me, from the brilliant @jburnmurdoch. It's a uniquely terrible year for incumbents everywhere. https://t.co/r5SRUpYn2x
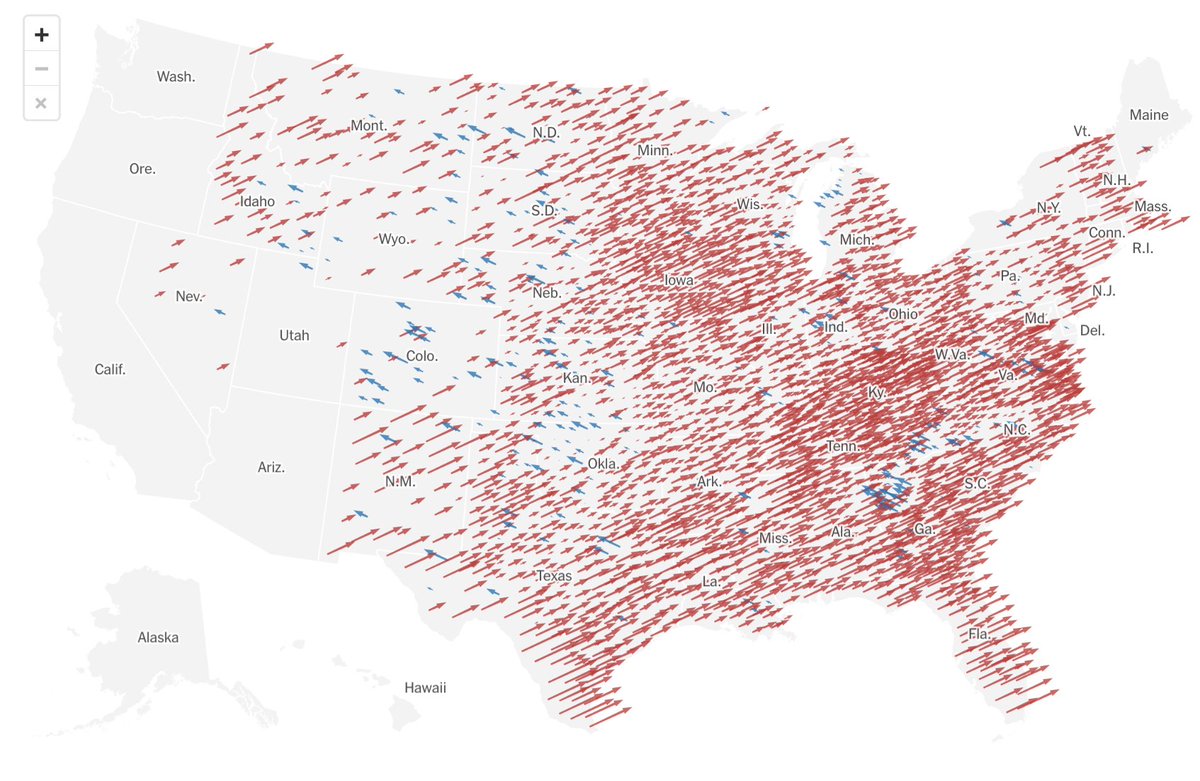
My initial take on Trump's win:
https://t.co/OagyPxsFFg
His gains were widespread, so explanations should start with the broadest factors -- not with bespoke stories about states, cities, counties, and groups.
The simplest explanation: party of unpopular incumbent loses.
1/2
NHC Advisory 1 for Tropical Depression 14 had landfall only 12 miles north of where Milton eventually made landfall, at a 4-day lead time. One might say they're pretty good at their jobs.