Launching our new paper on arXiv: we trained the largest multilingual food model ever built.
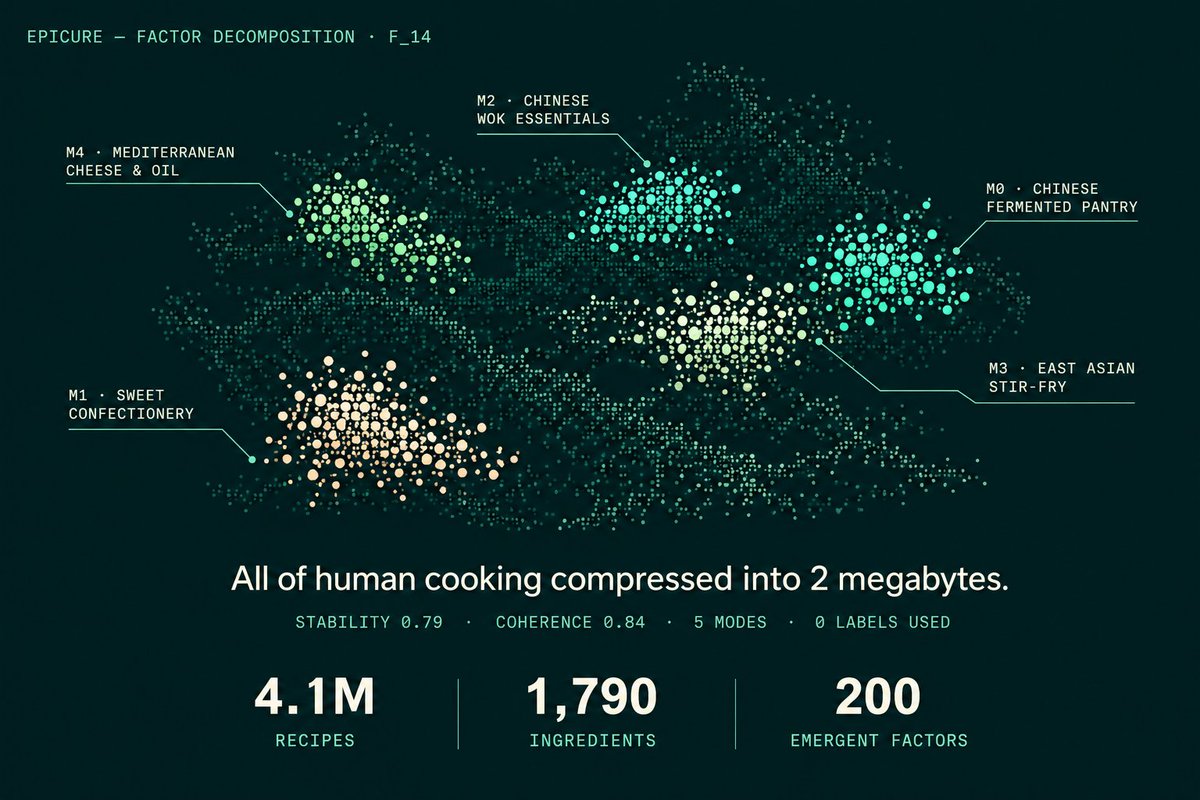
4.1M recipes. 7 languages. 1,790 ingredients. 300 dimensions.
All of human cooking compressed into 2 megabytes.
@alokbishoyi97 Fair points. Conclusions aside, it’s genuinely fascinating to see how these systems are ready to solve problems that matter to us.
Been following your work on evo! Thanks for the tip. Will dig deeper!
On a sufficiently well scoped task, one can conclude which model seems to do better.
Another angle is witnessing the progress by a machine alone.
A third angle is letting your imagination run loose on what's the limit for a human + machine collab?
Automating AI research is the next major step in AI
We let Claude Code (Opus 4.7) and Codex (GPT 5.5) run autonomously on the nanoGPT speedrun optimizer track using our idle compute. ~10k runs, ~14k H200 hours
Opus now holds the record at 2930 steps vs the 2990 human baseline
All resources are open source :)
Challenge: https://t.co/rlzodjD0T7
Data: https://t.co/zBKLn1c5Y6
Source Code: https://t.co/AExiXteRMk
Paper inside the repo. (3/3)
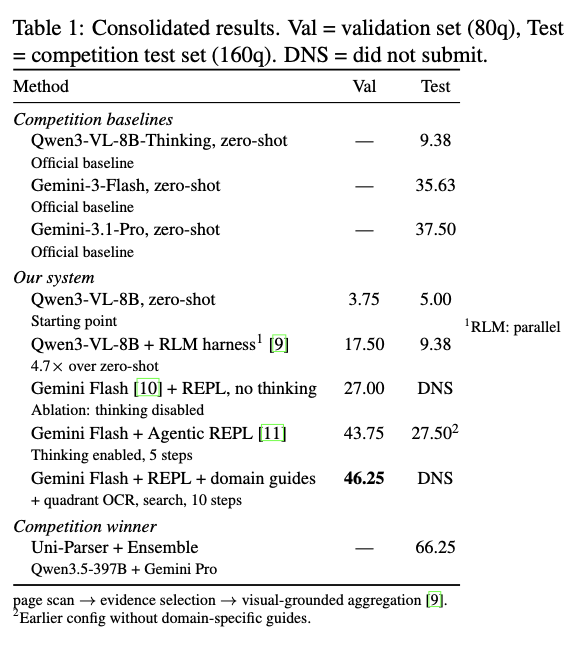
Harness Engineering for Document VQA!
Long context document VQA is interesting due to messy and diverse docs & immediate real-world impact.
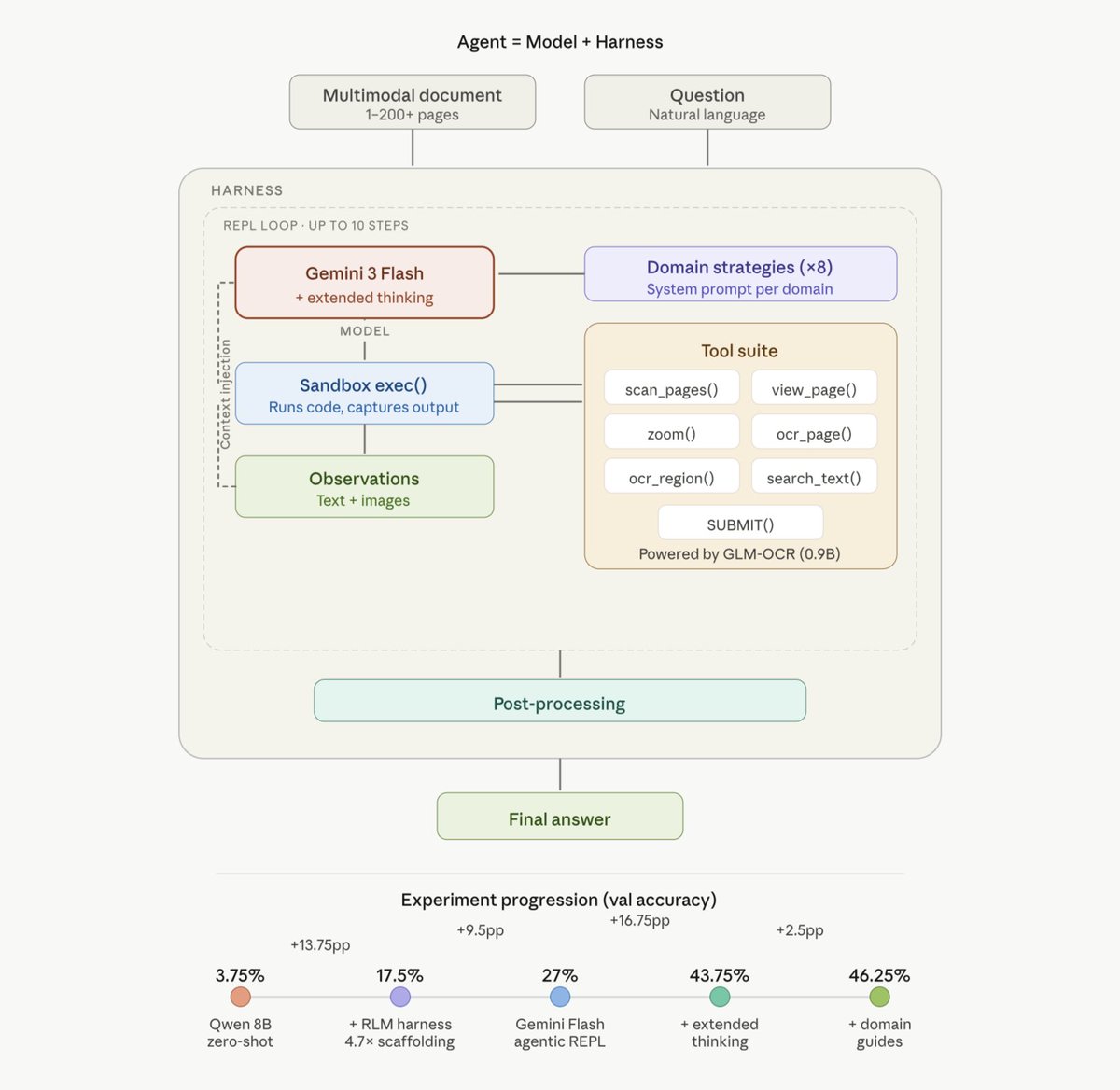
Built a coding agent with RLMs. Reasoning helps perf. Harness & tool design >> prompt engineering for task performance.
Fun project (1/3)
@natolambert Congrats on the launch! Been following the open model movement and hopefully these resources will spur more activity in the open model landscape :)
If you take a single, you eliminate the possibility of a regular time loss. So then it's a 50% chance to go to a super over, and a 50% chance that you win.
And if it goes to a super over, then there is again a 50% chance you could win.
So if you take a single there is 25% chance of losing after a super over and a 75% chance of winning either outright or after the super over.
Now if you do not take the single, there is a 33.33% chance you win, 33.33% chance you go to a super over, and a 33% chance you lose. If you add the odds of the super over, it is a pure 50-50 chance.
Granted, this does not bring the skill of the batter into the picture and that of the non-striker and their current form. But if you played the odds, the single was the most logical choice.
@AnjneyMidha Fwiw, Claude models on the Cursor agent interface are good at uninterrupted long running sessions for ML research and experimentation tasks.
The cursor harness seems pretty smooth imo.
What most people think happened: engineering got easier because AI agents can handle much of the coding.
What actually happened: we are shipping a lot more, a lot faster, and engineers need to build robust systems to ensure nothing breaks.
From what I'm seeing, engineering has become much more intense with AI, not less.
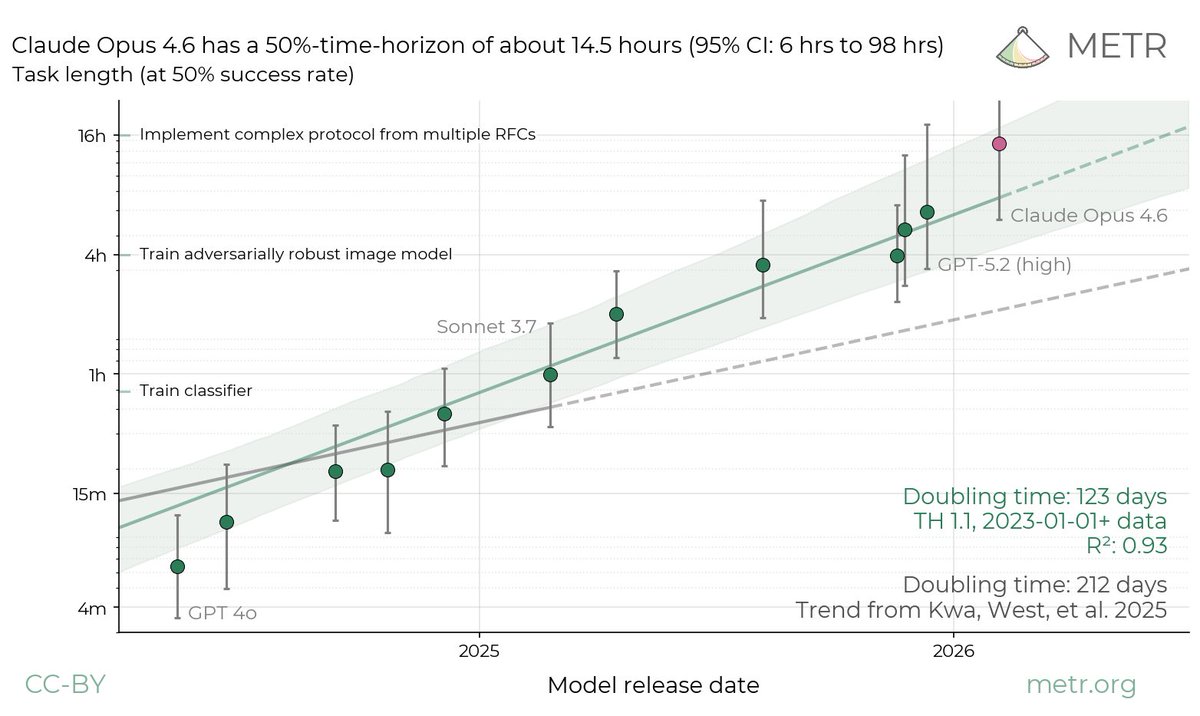
We estimate that Claude Opus 4.6 has a 50%-time-horizon of around 14.5 hours (95% CI of 6 hrs to 98 hrs) on software tasks. While this is the highest point estimate we’ve reported, this measurement is extremely noisy because our current task suite is nearly saturated.
Sufficiently advanced agentic coding is essentially machine learning: the engineer sets up the optimization goal as well as some constraints on the search space (the spec and its tests), then an optimization process (coding agents) iterates until the goal is reached.
The result is a blackbox model (the generated codebase): an artifact that performs the task, that you deploy without ever inspecting its internal logic, just as we ignore individual weights in a neural network.
This implies that all classic issues encountered in ML will soon become problems for agentic coding: overfitting to the spec, Clever Hans shortcuts that don't generalize outside the tests, data leakage, concept drift, etc.
I would also ask: what will be the Keras of agentic coding? What will be the optimal set of high-level abstractions that allow humans to steer codebase 'training' with minimal cognitive overhead?