JUST IN : TRADING IN SOUTH KOREA HAS BEEN HALTED AS THE COUNTRIES STOCK MARKET IS NOW DOWN NEARLY 9% TODAY
ABSOLUTE BLOODBATH IN THE KOREA AS SAMSUNG AND SK HYNIX LEAD THE DECLINE
Perplexity Comet is scary GOOD.
This agentic browser connects to your apps and does everything you want autonomously.
10 powerful use cases👇:
1. Summarize and provide me all the links of this video
Modern chickens grow 500-800% faster than they did in 1925.
What used to take 4 months now takes 6 weeks. Even "organic" chicken reaches the market in 8 weeks.
So what's making them explode in size? 🧵
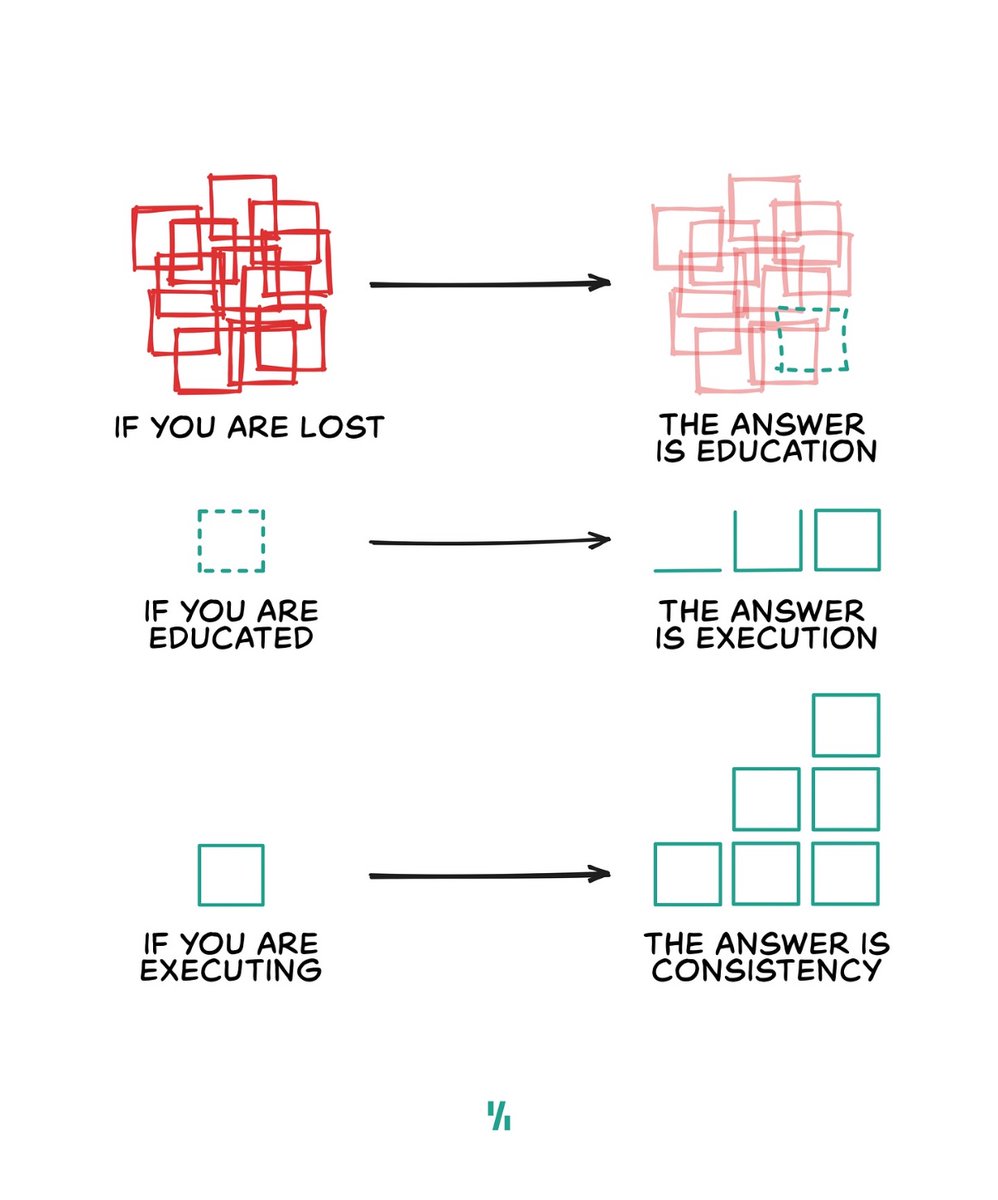
Reminder: Profit is a good thing.
This should be an obvious statement. But, since our youngest and most educated citizens keep voting for people like Zohran Mamdani and AOC, apparently it needs to be reiterated.
Profit is a good thing. It is critical for a progressive, flourishing society, and the ethical pursuit of it should be celebrated, not criticized.
What is profit?
Profit represents the financial gain that accrues to owners of a business when total revenue exceeds total costs. Put simply, it’s how much business owners get to keep when they’re able to sell things for more than it costs to create them.
Socialists commonly denigrate profit as “exploitative” or “parasitical”; if they’re trying to sound fancy, they’ll say things like “the surplus value of labor that the bourgeoisie capitalist class has extracted from the working class.”
They are wrong.
Profit serves two extremely valuable—and irreplaceable—roles in society, even for people who don’t own businesses:
1. Profit rewards risk and incentivizes growth. All economic ventures that create value for the wide range of stakeholders in our society—from financial parties, such as investors and lenders, to customers, suppliers, employees, governments, and community organizations—have financial outcomes that are inherently uncertain. This uncertainty is called risk, and, in varying levels, it is inherent to any project without a guaranteed and instantaneous payout.
Without profit, there would be no incentive for companies and their shareholders to assume these risks. Without profit, there would be no capital investments (e.g., equipment purchases, new factories), innovation (e.g., new technologies, pharmaceutical R&D), or entrepreneurship. Without profit, there would be new jobs created, no new restaurants to enjoy, no tax revenue to fund government benefits, national defense, public education, municipal parks.
Profit is the mechanism that makes progress possible, for business owners and employees alike.
2. Profit sends a signal to the rest of the economy that a certain product or service is valuable, and that someone should make the investments necessary to supply more of it. Economists refer to this as a price signal, and it’s virtually impossible to replicate outside of profit creation in a market-based economy.
When auto manufacturers are able to sell cars profitably, it sends a signal to the market for competitors to produce more of them (whether through greater capacity utilization at existing facilities or by constructing new factories). This leads to more cars being produced and sold, lower prices for customers, greater labor demand, and, over time, stronger wages for employees.
The same applies to plumbing companies, iron ore mining, wheat production, new medications, video games, coffee shops, and every last job in the labor market. Profit provides the signal that subtly directs every economic decision across our complex, wonderful, multifaceted society.
It sounds simple, right? But there are millions of variables here across millions of economic participants, all of them changing continuously. What looks seamless in a market-based economy becomes impossible to model in a centrally planned one. It’s laughable to even try.
Our modern-day capitalist society is nothing short of a miracle. It may not be perfect, but it’s vastly superior to any other economic system ever attempted or imagined.
Profit is a foundational pillar of that system, and it deserves respect as such. Keep that in mind next time you’re at work, checking out at the grocery store, or filling out your ballot in a voting booth.
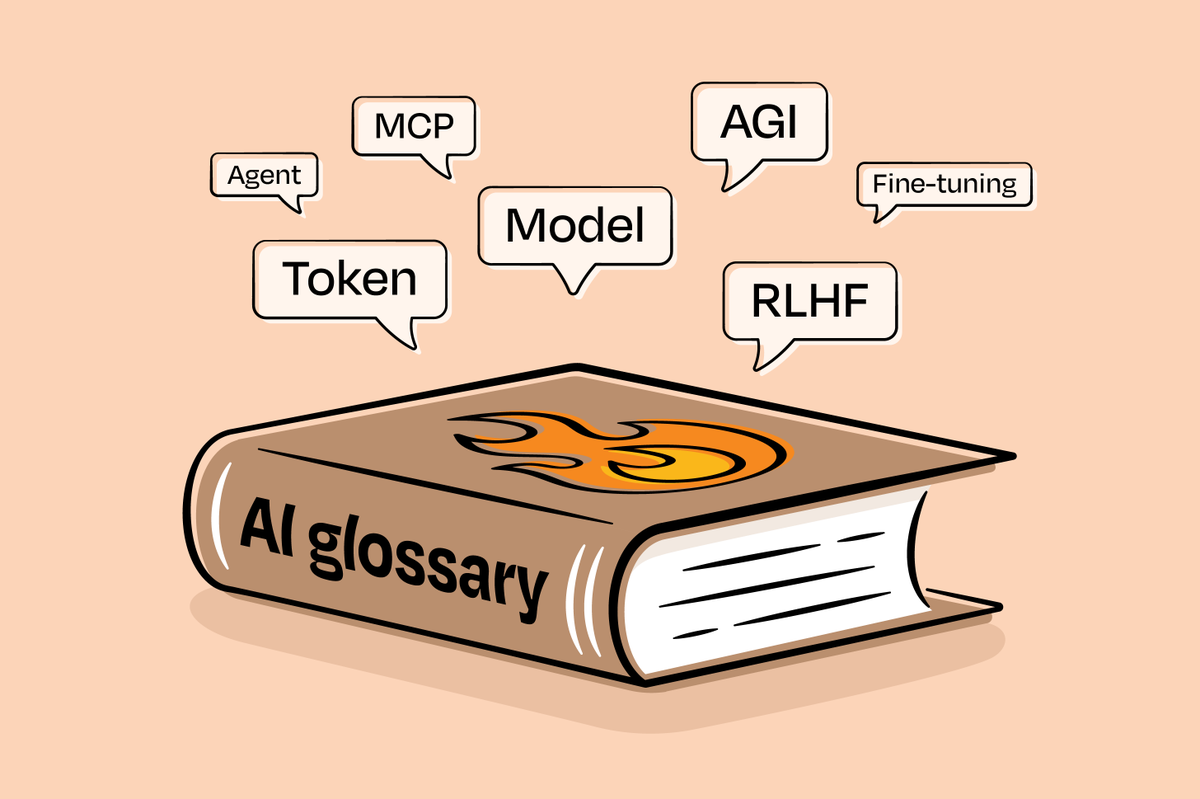
The 20+ most common AI terms explained, simply
1. Model
An AI model is a computer program that is built to work like a human brain. You give it some input (i.e. a prompt), it does some processing, and it generates a response.
Like a child, a model “learns” by being exposed to many examples of how people typically respond or behave in different situations. As it sees more and more examples, it begins to recognize patterns, understand language, and generate coherent responses.
There are many different types of AI models. Some, which focus on language—like ChatGPT o3, Claude Sonnet 4, Gemini 2.5 Pro, Meta Llama 4, Grok 3, DeepSeek, and Mistral—are known as large language models (LLMs). Others are built for video, like Google Veo 3, OpenAI Sora, and Runway Gen-4. Some models specialize in generating voice, such as ElevenLabs, Cartesia, and Suno. There are also more traditional types of AI models, such as classification models (used in tasks like fraud detection), ranking models (used in search engines, social media feeds, and ads), and regression models (used to make numerical predictions).
2. LLM (large language model)
LLMs are text-based models, designed to understand and generate human-readable text. That’s why the name includes the word “language.”
Recently, most LLMs have actually evolved into “multi-modal” models that can process and generate not just text but also images, audio, and other types of content within a single conversational interface. For example, all of the ChatGPT LLM models natively support text, images, and even voice. This started with GPT-4o, where “o” stands for “omni” (meaning it accepts any combination of text, audio, and image input).
Here’s a really good primer on how LLMs actually work by @every: https://t.co/6C4mYgtsDl
Also, this popular deep dive by @karpathy: https://t.co/h5UKWpocIS
3. Transformer
The transformer architecture, developed by Google researchers in 2017, is the algorithmic discovery that made modern AI (and LLMs in particular) possible.
Transformers introduced a mechanism called “attention,” where instead of only being able to read text word‑by‑word, sequentially, the model is able to look at all the words at once. This helps the models understand how words relate to each other, making them far better at capturing meaning, context, and nuance than earlier techniques.
Another big advantage of the transformer architecture is that it’s highly parallelizable—it can process many parts of a sequence at the same time. This makes it possible to train much bigger and smarter models simply by scaling up the data and compute power. This breakthrough is why we suddenly went from basic chatbots to sophisticated AI assistants. Almost every major AI model today, including ChatGPT and Claude, is built on top of the transformer architecture.
This is the best explanation of transformers I’ve seen: https://t.co/gEGYoE45zy
Here’s also a more technical and visual deep dive: https://t.co/HuHw8jIixm
4. Training/Pre-training
Training is the process by which an AI model learns by analyzing massive amounts of data. This data might include large portions of the internet, every book ever published, audio recordings, movies, video games, etc. Training state-of-the-art models can take weeks or months, require processing terabytes of data, and cost hundreds of millions of dollars.
For LLMs, the core training method is called “next-word prediction.” The model is shown billions of text sequences with the last word hidden, and it learns to predict what word should come next.
As it trains, the model adjusts millions of internal settings called “weights.” These are similar to how neurons in the human brain strengthen or weaken their connections based on experience. When the model makes a correct prediction, those weights are reinforced. When it makes an incorrect one, they’re adjusted. Over time, this process helps the model improve its understanding of facts, grammar, reasoning, and how language works in different contexts. Here’s a quick visual explanation: https://t.co/pRz66pD3ug
If you’re skeptical of next-word prediction generating novel insights and super-intelligent AI systems, here’s @ilyasut (co-founder of OpenAI) explaining why it’s deceptively powerful: https://t.co/bKsmQkZw3F
5. Supervised learning
Supervised learning refers to when a model is trained on “labeled” data—meaning the correct answers are provided. For example, the model might be given thousands of emails labeled “spam” or “not spam” and, from that, learn to spot the patterns that distinguish spam from non-spam. Once trained, the model can then classify new emails it’s never seen before.
Most modern language models, including ChatGPT, use a subtype called “self-supervised learning.” Instead of relying on human-labeled data, the model creates its own labels, generally by hiding the last word of a sentence and learning to predict it. This allows it to learn from massive amounts of raw text without manual annotation.
6. Unsupervised learning
Unsupervised learning is the opposite: the model is given data without any labels or answers. Its job is to discover patterns or structure on its own, like grouping similar news articles together or detecting unusual patterns in a dataset. This method is often used for tasks like anomaly detection, clustering, and topic modeling, where the goal is to explore and organize information rather than make specific predictions.
7. Post-training
Post-training refers to all of the additional steps taken after training is complete to make the model even more useful. This includes steps like “fine-tuning” and “RLHF.”
7. Fine-tuning
Fine-tuning is a post-training technique where you take a trained model and do additional training on specific data that’s tailored to what you want the model to be especially good at. For example, you would fine-tune a model on your company’s customer service conversations to make it respond in your brand’s specific style, or on medical literature to make it better at answering healthcare questions, or on educational content for specific grade levels to create a tutoring assistant that explains concepts in age-appropriate ways.
This additional training tweaks the model’s internal weights to specialize its responses for your specific use case, while preserving the general knowledge it learned during pre-training.
Here’s an awesome technical deep dive into how fine-tuning works: https://t.co/7VGs67vmAS
8. RLHF (reinforcement learning from human feedback)
RLHF is a post-training technique that goes beyond next-word prediction and fine-tuning by teaching AI models to behave the way humans want them to—making them safer, more helpful, and aligned with our intentions. RLHF is the key method used for what’s referred to as “alignment.”
This process works in two stages: First, human evaluators compare pairs of outputs and choose which is better, training a “reward model” that learns to predict human preferences. Then, the AI model learns through reinforcement learning—a trial-and-error process where it receives “rewards” from the reward model (not directly from humans) for generating responses the reward model predicts humans would prefer. In this second stage, the model is essentially trying to “game” the reward model to get higher scores.
Here’s a great guide: https://t.co/uCGz44Z3Ob
Also, this technical deep dive into RLHF: https://t.co/ug3TJ1u0gL
9. Prompt engineering
Prompt engineering is the art and science of crafting questions (i.e. “prompts”) for AI models that result in better and more useful responses. Like when you’re talking to a person, the way you phrase your question can lead to dramatically different responses. The same AI model will give very different responses based on how you craft your prompt.
There are two categories of prompts:
1. Conversational prompts: What you send ChatGPT/Claude/Gemini when you’re having a conversation with it
2. System/product prompts: The behind-the-scenes instructions that developers bake into products to shape how the AI product behaves
Here’s a podcast episode from just last week where we cover this and much more: https://t.co/nudf9aCGfy
10. RAG (retrieval-augmented generation)
RAG is a technique that gives models access to additional information at run-time that they weren’t trained on. It’s like giving the model an open-book test instead of having it answer from memory.
When you ask a question like “How do this month’s sales compare to last month?” a retrieval system is able to search through your databases, documents, and knowledge repos to find pertinent information. This retrieved data is then added as context to your original prompt, creating an enriched prompt that the model then processes. This leads to a much better, more accurate answer.
If you don’t give the model the context it needs to answer your question through RAG, this is when “hallucinations” happen (see more below).
Broadly, to summarize:
- Pre-training: Teaches the model general knowledge (and language)
- Fine-tuning: Specializes the model for specific tasks
- RLHF: Aligns the model with human preferences
- Prompt engineering: The skills of crafting better inputs to guide the model toward the most useful outputs
- RAG: A technique that retrieves additional relevant information from external sources at run-time to give the model up-to-date or task-specific context it wasn’t trained on
For more (including MCP, agent, token, vibe coding, synthetic data, AGI), check out today's post: https://t.co/w7RT1t2bzU
some days, I write PRDs, strategy docs, and whatever else is needed before lunch and feel unstoppable.
other days, I stare at a blank document for three hours, and my only achievement is finishing my coffee.
both are normal.
Such a great video on understanding LLMs! Thanks @karpathy for the gem and such a great overview.
Deep Dive into LLMs like ChatGPT https://t.co/henCAJ5aYr
As a product manager, building products that integrate Large Language Models (LLMs) 🤖 can be a challenging task.
To help navigate this landscape, here is quick at a glance glossary of some important technical terms with examples that can assist.
Check them out below 👇
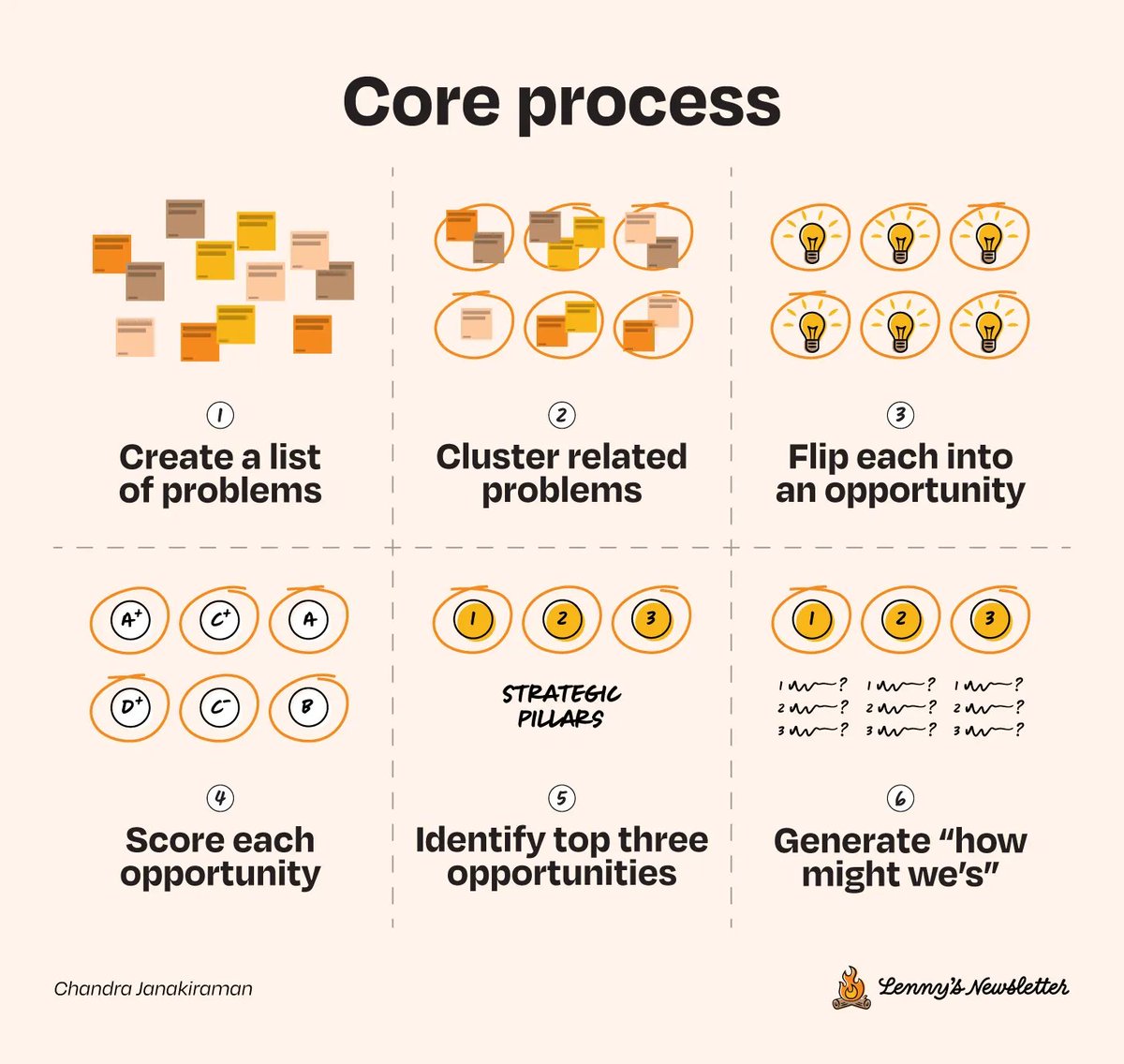
Most prioritization frameworks look great in blog posts...
But fall apart in real organizations.
I’ve spent years testing so many of them, getting stuck in analysis paralysis.
Here’s what actually works for prioritizing your roadmap at a mid-sized company (in 2 minutes): 👇
WTF is product strategy
Product strategy sits in between the mission/vision and the plan, either at the company level or at the team level.
At the company level, the mission and vision are typically articulated by the founders/CEO and tend to be durable over time.
The plan (i.e. roadmap) is an ordered list of projects based on some notion of prioritization and sequence of delivery.
There is a steep drop in elevation between the mission/vision and the plan, and strategy occupies this large void.
Strategy exists to force a disciplined choice to deploy scarce resources for maximum impact. Regardless of the size of a company, the resource pool and capacity to get work done is always constrained relative to the universe of work that could be done—making this choice a critical decision in every single context.
A good strategy articulation typically includes three components:
1. 3 to 5 areas for the company or the team to focus on, which we will henceforth refer to as strategic pillars
2. Several areas that should explicitly not be the focus
3. A clear set of explanations for why these choices were made
Here's a step-by-step guide to crafting the two types of product strategy:
1. A 2-year strategy, which is typically focused on solving problems with the current product, i.e. small “s” strategy
2. A 3/5/10-year strategy focused on aspirational futures. i.e., big “S” strategy
Bookmark this for the next time you're working on a strategy: https://t.co/UL7z8SBpZs
Goodbye ChatGPT
It’s only been 5 days since Deepseek R1 dropped, and the World is already blown away by its potential.
13 examples that will blow your mind (Don't miss the 5th one):