NEW: malware developers added nuclear & biological weapons text to to their spyware.
Goal? To trigger LLM safety refusals... so that their spyware wouldn't be analyzed by an AI security scanner.
Cleanest practical example I can think of for why over-indexing on first order safety alignment is risky.
When closed (and open) models ship with aggressive refusals, they will be sprinkled with second-order blindspots that attackers will discover...and exploit.
We are only in the earliest days of attackers leveraging these features, and it wouldn't surprise me if users systems that need to handle complex cybersecurity issues demand that models be less safety-blunted.
In the weeds: @SocketSecurity's post also shows why intention matters in how you design a malware analysis pipeline to avoid prompt manipulation.
H/T to colleagues that shared this with me https://t.co/f3Aj9TYxU4
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
🚨 THE ENTIRE AI BOOM MIGHT BE BUILT ON FAKE REVENUE.
Latest corporate filings show that OpenAI and Anthropic alone make up over half of the entire $2 trillion future cloud backlog held by Microsoft, Oracle, Google, and Amazon.
This massive pipeline is actually being created through a circular accounting trick called a round trip revenue loop.
But how it works ?
A tech giant gives billions of dollars to an AI startup as an "investment". But hidden in the contract is a strict rule forcing the startup to hand that exact same money straight back to the tech giant to rent their computer servers.
Look at the documented case of Microsoft and OpenAI.
When Microsoft invested $13 billion into OpenAI, it didn't just give them cash; it gave them "cloud credits" to use Microsoft servers. OpenAI used those exact credits to train its AI models, and Microsoft then turned around and recorded that server usage as brand new "cloud revenue" from a customer.
The tech giant is literally paying itself with its own money and calling it a sale.
This is why OpenAI’s annual cloud bill has ballooned to over $60 billion, double its actual revenue of $25 billion, kept alive solely by this recycled funding loop.
Anthropic runs the exact same play, spending $2.66 billion on Amazon Web Services in just nine months, which was basically 100% of all the money it earned at the time.
This manufactured demand triggers a second accounting trick where tech giants book massive paper profits. Every time a startup gets a higher value from a new funding round, the tech giant updates the value of its investment on its books and counts that unearned paper gain as direct profit.
In Q1 2026, Alphabet reported a record $62.6 billion profit, but $28.7 billion nearly half, was just a paper markup on its Anthropic investment. In the same quarter, Amazon reported $30.3 billion in profit, but $16.8 billion of it was just an Anthropic paper gain.
While Amazon reported record profits, its actual free cash flow collapsed 95% to just $1.2 billion because it had to spend $44.2 billion in real cash to build physical data centers.
This has created a massive danger where these giant companies rely heavily on just one or two unstable startups. Microsoft has 49% of its $627 billion future backlog tied to OpenAI, while Oracle has an incredible 54% of its entire $553 billion pipeline relying on OpenAI alone.
This perfectly mirrors the 2001 dot-com crash when Global Crossing and Qwest Communications swapped identical fiber-optic network capacity with each other just to book fake sales.
Qwest had to erase $1.4 billion in fake income, and Global Crossing went completely bankrupt.
The only difference is that the dot-com swaps were illegal, but today's AI loop is fully legal under current accounting rules.
This legal loop inflates tech company stock prices, forcing automatic retirement accounts and index funds to buy even more of these tech stocks. It is a self feeding loop where investments, sales, and stock prices all go up on paper without the AI technology ever making real cash profits.
SpaceX is such a bad ass company. In their IPO filing, they wrote this:
• The first private company to develop and launch a liquid-fuel rocket to reach orbit (2008)
• The first private company to successfully dock a private spacecraft with the International Space Station (2012)
• The first to successfully propulsively land (2015) and refly orbital-class rocket boosters (2017)
• The first to begin deploying a large-scale LEO broadband satellite constellation (2019);
• The first private company to transport astronauts to orbit, returning America's ability to fly astronauts to and from the International Space Station (2020)
• The first to manufacture consumer-grade phased-array user terminals at scale (2022);
The first to deploy a large-scale LEO satellite-to-mobile constellation (2025)
• The first to build a gigawatt-scale Al training cluster and largest coherent supercomputer (2026)
• The first gigawatt-scale Megapack battery installation (2026); and
• The only company capable of building orbital AI compute at scale.
BOOM.
Chinese students are buying GPT-5.4/5.5 and Claude API access from Xianyu/Taobao proxy sellers for almost 96-97% cheaper
People are apparently burning 100M+ tokens a day for like $1 and vibecoding nonstop.
Whether it’s existing consulting firms, new ones that emerge, FDEs from agent vendors, or new internal agent engineering roles, the amount of work that is going to be created to implement agents in enterprises will exceed anything we imagine today.
The complexity of implementing agents in any existing organizations is very real. When I talk to large enterprises, as you move from a chat paradigm to agents that participate in meaningful workflows, there are a number of things they need to do.
First, you have to get agents to be able to talk to your data securely across your systems. In many cases, enterprises have decades of legacy infrastructure that contain the valuable context for AI agents. That’s going to take a ton of work to go modernize and move to systems that work well with agents.
Then, you need to ensure that you’ve implemented agents with the right access controls and entitlements, the right scopes to be safely used, and have ways of monitoring, logging, and securing the work that they do.
Next, you need to actually document the processes in the organization in a way that agents can utilize for doing the work. You also need to figure out what the new workflow looks like when agents and people are working together on a process, and who steps in where. Just replicating the old workflow will mute the gains. Oh and you likely need to create evals for your top new end-state processes.
Finally, you have to keep up with a rapidly changing set of best practices and architectural shifts happening in the agent space. While it’s fun for people to change their personal productivity tools on a dime, it’s 100X harder to do this in a business process. The speed of change is a blessing and a curse right now for anyone trying to keep a stable system design.
All of this means that individuals and companies that develop expertise on the above set of components (and more) are going to be needed to help organizations actually implement agents at scale. This is also the rationale for vertical AI agents right now that can go in deep on a business domain and help bring automation to it.
This is a huge opportunity right now whether you’re doing this internally or as an external business provider.
Almost every SaaS app inside Vercel has now been replaced with a generated app or agent interface, deployed on Vercel.
Support, sales, marketing, PM, HR, dataviz, even design and video workflows. It’s shocking.
The SaaSpocalypse is both understated and overstated. Over because the key systems of record and storage are still there (Salesforce, Snowflake, etc.)
Understated because the software we are generating is more beautiful, personalized, and crucially, fits our business problems better.
We struggled for years to represent the health of a Vercel customer properly inside Salesforce. Too much data (trillions of consumption data points), the ontology of Vercel was a mismatch to the built-in assumptions, and the resulting UI was bizarre. We generated what we needed instead. When you don’t need a UI, you just ask an agent with natural language.
We’ve also been moving off legacy systems with poor, slow, outdated, and inconsistent APIs, as well as just dropping abstraction down to more traditional databases. UI is a function 𝑓 of data (always has been), and that 𝑓 is increasingly becoming the LLM.
Tonight, we reached an agreement with the Department of War to deploy our models in their classified network.
In all of our interactions, the DoW displayed a deep respect for safety and a desire to partner to achieve the best possible outcome.
AI safety and wide distribution of benefits are the core of our mission. Two of our most important safety principles are prohibitions on domestic mass surveillance and human responsibility for the use of force, including for autonomous weapon systems. The DoW agrees with these principles, reflects them in law and policy, and we put them into our agreement.
We also will build technical safeguards to ensure our models behave as they should, which the DoW also wanted. We will deploy FDEs to help with our models and to ensure their safety, we will deploy on cloud networks only.
We are asking the DoW to offer these same terms to all AI companies, which in our opinion we think everyone should be willing to accept. We have expressed our strong desire to see things de-escalate away from legal and governmental actions and towards reasonable agreements.
We remain committed to serve all of humanity as best we can. The world is a complicated, messy, and sometimes dangerous place.
I think it'll be more like:
You chat to your LLM app and it'll just spin up an app with a UI if it feels the need
Like you want to book a holiday apartment, it spins up a fancy Airbnb-like interface and books it for you
You want to edit your photo, it spins up a simple but advanced easy-to-use photo editor
The idea is that interfaces and apps become ephemeral to help you achieve whatever you want in a moment
Stripe is shipping all PRs with robots and people will still say that AI can't make complex stuff 🤣
I see this mainly on other socials.
People are absolutely clueless what Codex can do right now.
🇪🇺 @steipete on why Europe was unable to retain him as talent:
"In the US, most people are enthusiastic.
In Europe, I get insulted, people scream REGULATION and RESPONSIBILITY.
And if I really build a company here, then I get to struggle with things like investment protection laws, employee rights, and paralyzing labor regulations.
At OpenAI, most people work 6-7 days a week and get paid accordingly.
In Europe, that's illegal."
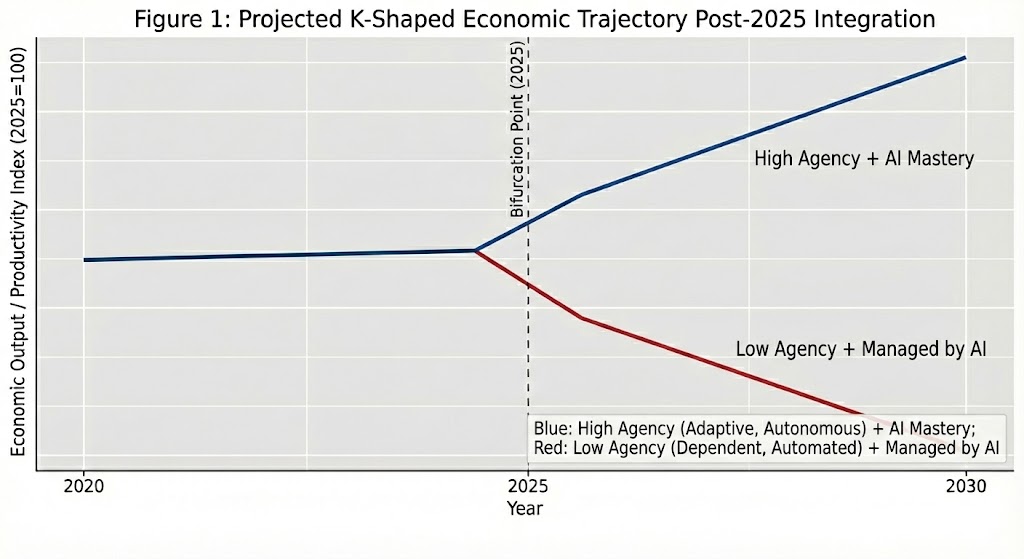
The singularities are here, plural.
So many different curves are going to the moon or the ground at the same time, across tech, culture, commodities, and politics.
The solar singularity is just one of them:
In 10 years, there will be two classes of people.
Economists call it the "K-shaped economy" - and the next 2-3 years will decide which line you're on.
• An overclass that uses AI as a lever to build wealth, automate income, and make decisions at a speed no human can compete with alone.
• And an underclass that gets managed by it.
This isn't just "coming". It's already happening.
Some mind-blowing stats:
• Workers with AI skills earn 56% more than the same job without them. That premium doubled in a single year.
• Industries adopting AI are seeing 3x the revenue growth per employee.
• Meanwhile, 90% of workers haven't taken a single hour of AI training.
• Goldman Sachs estimates 300 million jobs will be affected by AI by 2028. That's 24 months from now.
If you're reading this now and you haven't built systems with AI - haven't automated a single workflow, haven't used it to create anything that makes you money or makes you irreplaceable - you are currently on the wrong line.
That's not an insult. You have the agency to change your trajectory right now.
But six months from now, the gap will be twice as wide. And a year from now, it may not be crossable.
Spotify revealed that its top engineers haven’t written a single line of code since December, thanks to an internal AI system called “Honk” powered by Claude.
The company shipped 50+ new features in 2025 alone, with AI now enabling real-time bug fixes and feature deployments straight from a phone during a commute, dramatically accelerating product velocity