AI detecting pneumonia in a second is impressive.
But grounding it in structured ontology, report-level reasoning, longitudinal context and validating across diverse populations beyond MIMIC-CXR, PadChest, CheXpert datasets is the real challenge. #medicalAI#HealthcareAI
A pulmonologist with 20 years of experience just made the most honest AI video I've seen.
He shows what he can do in seconds: "Right middle lobe pneumonia. Left upper lobe consolidation. Bilateral pneumonia. Patient is very sick."
Then: "Here comes AI. They pick it up in a second."
Then: "I'm going to be applying to McDonald's soon. I hope they have some openings." 😅
This isn't a tech bro making predictions. This is the prediction arriving, narrated by the person it's arriving for.
Interested in deployable SAM based multimodal medical image segmentation, using compression & PEFT for resource-constrained healthcare across India 🇮🇳
Currently working on this!!
#HealthcareSolution#IndiaAI
📢🇮🇳 Looking for interesting applications of Segment Anything (SAM) in India! It can be any model in the SAM series from @AIatMeta applied to any industry or domain, but specifically looking for India-focused use cases. If you are building with SAM in India or know a team that is, please tag them or DM me!
Constructive criticisms are fine!! But I love to see things go beyond traditional deep tech startups in India. At least those who can afford it; let them do their job!🙏
#DeepinderGoyal
Gentle reminder to all the concerned doctors and/or influencers
We haven’t made any public commercial announcements about Temple yet. We haven’t released any official device benchmarking data. A lot of the work is still underway; we’re months away from introducing preview devices to the public, if at all.
You are advising people not to buy an “unvalidated” device that isn’t even available to order or pre-order yet. That’s funny, tbh.
We will share all the science if and when we decide to sell Temple. You can judge and give all your advice at that moment. Until then, be curious, and cheer Indian startups? Your skepticism is valuable, but at the right time.
PhD Students – How to identify top researchers in your research area?
First, why it is important to know top researchers in your research area.
1️⃣ Help you identify top papers
2️⃣ Help you to collaborate with top researchers
3️⃣ Help you to learn from their work
4️⃣ Help you find your research ideals
🎯 Use @Bohrium_AI4S to identify the top researchers.
👉 Here is how it works?
1. Go to https://t.co/rNB7rdA0RT and log in.
2. From the left side menu, click Scholars.
3. In the search box, enter your research area.
4. For example, I entered cloud computing.
5. Bohrium will display the ranked list of top researchers.
6. This list is based on the number of citations for the researcher.
7. Then, click on the researcher’s name.
8. It will display the entire profile of the researcher.
9. This profile contains the work history of the researcher.
10. It contains the research areas of the researcher.
11. You will see the number of papers and citations.
12. You can sort the papers based on the latest/most cited.
13. You will also see the co-authors of the researcher.
Once explored, you can go back and explore another researcher.
This way you will know the top researchers in your research area.
Bohrium has a large database of 20 million active scholars
🎗️Try Bohrium to find top researchers
Bohrium Link: https://t.co/rNB7rdA0RT
❄️ Anything you'd like to add?
Today, we're announcing @episteme, a new type of R&D company that recruits exceptional scientists to pursue high-impact ideas.
Science isn’t bottlenecked by the availability of talent, but by places where they can do their best work.
Scientific progress has driven human flourishing: extending lifespans, lifting billions from poverty, and expanding our understanding of the universe.
But history is littered with transformational ideas that were overlooked in their time. That problem is still acute today: too much promising talent remains uncultivated, and remarkable ideas die in the lab or are filtered out by misaligned incentives.
Today, scientists face suboptimal paths for translating their research into impact: academia is famously risk-averse and incentivizes publications and winning grants vs. translational research. Industry is too often focused on short‑term incentives. And startups lack the substantial capital, expertise, and complex infrastructure needed to deliver long-term scientific progress.
On top of that, recent funding cuts in the US mean the overall supply of ideas is decreasing. Put together, the global scientific production system is operating at a fraction of its capacity.
How Episteme operates is different: we identify great scientists who can meaningfully benefit humanity, but who aren’t supported efficiently within traditional institutions today. Researcher by researcher, we work with them to determine the bespoke resources, operational support, and environmental conditions to execute on their research. We bring them together in-house, and provide those resources to ensure that their breakthroughs are deployed for real-world impact.
We’ve already assembled an amazing team of operators, ranging from the Gates Foundation, DeepMind, ARPAs, DoE – just to name a few – and researchers who are pursuing important problems across physics, biology, computing, and energy. Our team has spoken to hundreds of researchers across disciplines and geographies to understand the limitations they’re facing and what can be done better, and designed Episteme for them.
We’re backed by individuals like @sama, Masayoshi Son, and other long-term partners who share our mission of enabling ambitious science for tangible human impact.
About me: I started working as a researcher 9 years ago, on problems ranging from AI-driven drug discovery to developing brain-machine interfaces. It was that experience that led me to realize that so many scientists with great potential to change the world don’t have access to opportunities equal to their capacities.
@sama and I believe that much better science should happen for humanity, and that a new engine is needed to support that. We decided to cofound Episteme together, and I am incredibly grateful for Sam’s unwavering support as a thought partner and founding investor.
Our conviction is that by supporting the right people with the right incentives, we're set to generate breakthrough discoveries to benefit humanity. We cannot rely on the course of history to shape scientific progress; we need to proactively shape the system by supporting the most talented people with the right resources and incentives.
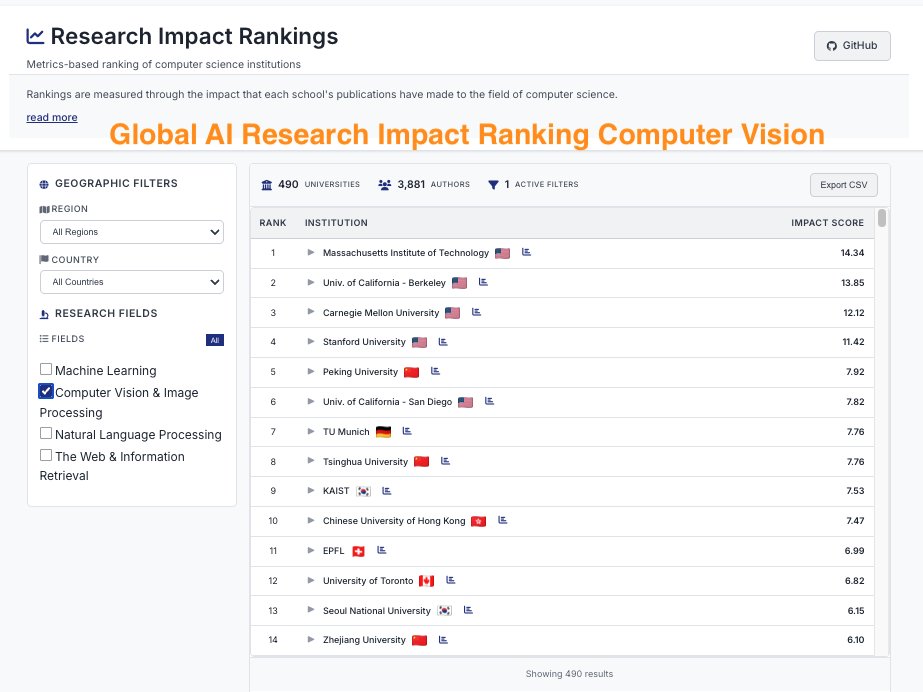
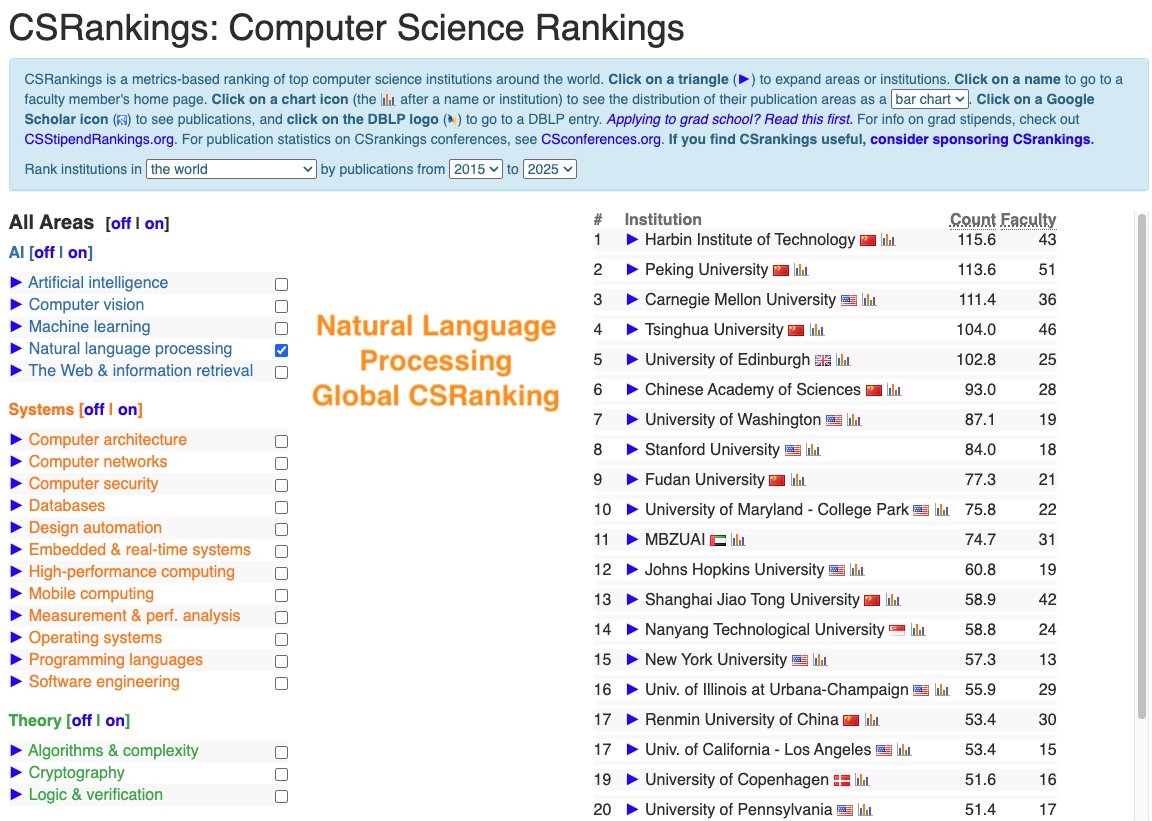
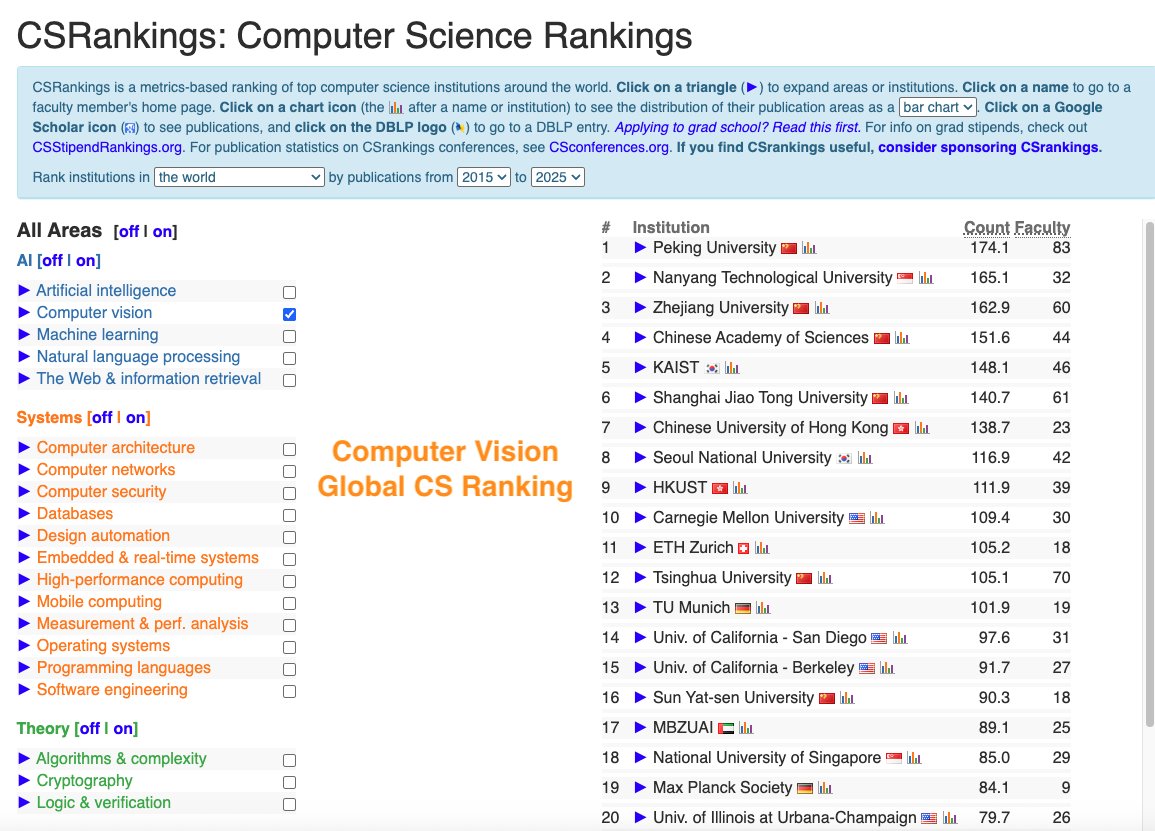
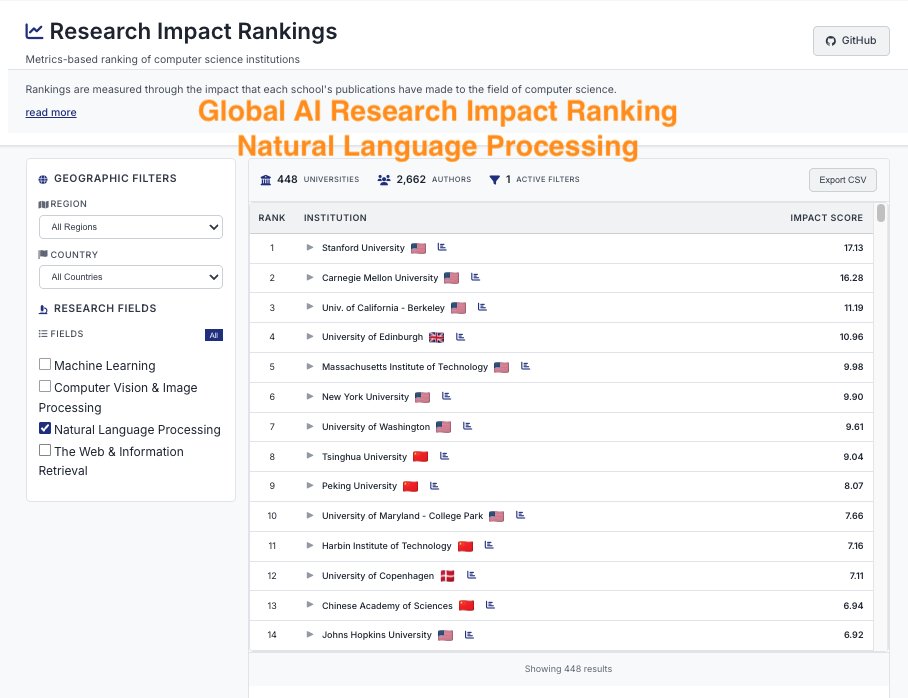
CSRankings counts publication in top conferences to rank professors/universities. But this encourages researchers to pursue quantity rather than quality.
We propose https://t.co/uDZLqYkD1g, a new university ranking system that tries to measure quality instead of quantity of publications.
How can we measure the quality of the publications? We believe that 1) The quality of research is best understood and evaluated by peers in the same research area;
2) With careful and informed use, LLMs can reveal the implicit quality judgments that peers convey through their citation practices and writing across large volumes of scholarly work.
Hence, we developed the new ranking system where we analyze research papers from major AI conferences with LLMs.
For each paper, we ask an LLM what are the 5 most important papers to this paper. In other words, the five works that most strongly influence the study. By doing this, we trace which papers and authors are consistently seen as inspirational and foundational to new discoveries in the field.
We ran the model on all papers from top conferences in machine learning, computer vision, natural language processing and information retrieval from 2020 - 2025, and filtered references to only have those from 2000 onwards.
Next, we map these influential authors to their affiliated universities using the CSRankings name–affiliation database. Each time a paper is recognized as one of the “top five references” in another work, its authors and their institutions receive credit. To keep the scoring fair, points are divided by the number of co-authors, ensuring balanced recognition across collaborations.
The result is a new kind of academic ranking: one that rewards universities not just for publishing often, but for producing research that endures, inspires, and drives the field forward. This approach highlights scholarly influence and provides students, researchers, and institutions with a clearer picture of where the most impactful work is happening.
Note that we believe that CSRankings had substantially improved university rankings in computer science by replacing subjective, reputation-based measures, such as those in US News, with more objective indicators, but the LLM era allows us to do something potentially better!
Due to computational resource limits, we were only able to run it with a small 7B language model. It is also a project primarily led by undergraduate and master students from Oregon State University and University of California Santa Cruz. As a result, the system is very much a work in progress and will inevitably contain errors and blind spots. We actively welcome community feedback, new collaborators and contributions of GPU compute so that we can run larger LLMs, obtain more reliable results and improve the methodology.
The creator of GPT doesn’t have a PhD.
The creator of PyTorch doesn’t have a PhD.
The research lead at Cursor dropped out of NEU.
You don’t need a PhD or a top school to become a great researcher or engineer.
You can just do things!
CSRankings counts publication in top conferences to rank professors/universities. But this encourages researchers to pursue quantity rather than quality.
We propose https://t.co/uDZLqYkD1g, a new university ranking system that tries to measure quality instead of quantity of publications.
How can we measure the quality of the publications? We believe that 1) The quality of research is best understood and evaluated by peers in the same research area;
2) With careful and informed use, LLMs can reveal the implicit quality judgments that peers convey through their citation practices and writing across large volumes of scholarly work.
Hence, we developed the new ranking system where we analyze research papers from major AI conferences with LLMs.
For each paper, we ask an LLM what are the 5 most important papers to this paper. In other words, the five works that most strongly influence the study. By doing this, we trace which papers and authors are consistently seen as inspirational and foundational to new discoveries in the field.
We ran the model on all papers from top conferences in machine learning, computer vision, natural language processing and information retrieval from 2020 - 2025, and filtered references to only have those from 2000 onwards.
Next, we map these influential authors to their affiliated universities using the CSRankings name–affiliation database. Each time a paper is recognized as one of the “top five references” in another work, its authors and their institutions receive credit. To keep the scoring fair, points are divided by the number of co-authors, ensuring balanced recognition across collaborations.
The result is a new kind of academic ranking: one that rewards universities not just for publishing often, but for producing research that endures, inspires, and drives the field forward. This approach highlights scholarly influence and provides students, researchers, and institutions with a clearer picture of where the most impactful work is happening.
Note that we believe that CSRankings had substantially improved university rankings in computer science by replacing subjective, reputation-based measures, such as those in US News, with more objective indicators, but the LLM era allows us to do something potentially better!
Due to computational resource limits, we were only able to run it with a small 7B language model. It is also a project primarily led by undergraduate and master students from Oregon State University and University of California Santa Cruz. As a result, the system is very much a work in progress and will inevitably contain errors and blind spots. We actively welcome community feedback, new collaborators and contributions of GPU compute so that we can run larger LLMs, obtain more reliable results and improve the methodology.
My first foray into pathology, we fully open-sourced training & eval of our foundation model OpenMidnight
Surprisingly achieved SOTA with only training on 1 public dataset
Now scaling up, adding architectural changes, upgrading DINOv2 -> v3, + building publicly in Discord—join us if you're interested (we are sharing compute with volunteers)
😅
all of this is true. i owe a bunch to my mentors as well.
my mentor at nyu was then phd student @psermanet, one of the kindest human beings i know
Yann LeCun gave me opportunity 2x when i didn't have another option forward in AI.
the person who pushed me to go to IIIT for my final year project and then go to cmu without a plan after my masters rejections was Praveen Garimella, gamechanging advice to not give up.
props to my dad Vithal Chintala and mom Rajani Chintala for letting me be crazy and going beyond their financial means to support me. i grew up squarely middle class with lots of debt in the household, even though my parents eventually became independently wealthy post-2010 -- so letting me pursue this path when there were safer choices always available is great parenting!
thanks @deedydas for spending time digging up the deets.
I'm sure everyone who's sitting upon success has many struggles, life doesn't come easy.
p.s.: i got rejected 3x from google and deepmind together, not just deepmind.
😅
all of this is true. i owe a bunch to my mentors as well.
my mentor at nyu was then phd student @psermanet, one of the kindest human beings i know
Yann LeCun gave me opportunity 2x when i didn't have another option forward in AI.
the person who pushed me to go to IIIT for my final year project and then go to cmu without a plan after my masters rejections was Praveen Garimella, gamechanging advice to not give up.
props to my dad Vithal Chintala and mom Rajani Chintala for letting me be crazy and going beyond their financial means to support me. i grew up squarely middle class with lots of debt in the household, even though my parents eventually became independently wealthy post-2010 -- so letting me pursue this path when there were safer choices always available is great parenting!
thanks @deedydas for spending time digging up the deets.
I'm sure everyone who's sitting upon success has many struggles, life doesn't come easy.
p.s.: i got rejected 3x from google and deepmind together, not just deepmind.
5 Lectures and keynotes defining AI right now
▪️ @karpathy: Software Is Changing (Again)
▪️ @RichardSSutton: The OaK Architecture: A Vision of SuperIntelligence from Experience
▪️ GTC March 2025 Keynote with NVIDIA CEO Jensen Huang
▪️ @ylecun "Mathematical Obstacles on the Way to Human-Level AI"
▪️ @AndrewYNg: State of AI Agents
Save this list and explore all the talks here: https://t.co/WfK3XcMchN
An excellent blog post by @SarvamAI! Amid all the chatter, it’s nice to see valuable steps toward building
Indian centric LLMs. “Patience and hard work are all we need”😉
Meanwhile some people keep waiting for instant miracles. #MadeInIndia#IndiaAI
https://t.co/HLel1M3lcD
An introductory talk by Christopher Manning @chrmanning on “Large Language Models in 2025 – How much understanding and intelligence?” at the Workshop on a Public AI Assistant to Worldwide Knowledge at @Stanford, covering 3 eras of LLMs, RAG, Agents, DeepSeek-R1, using LLMs, ….
Distillation has been on the news (!) due to @deepseek_ai. The paper https://t.co/fRbFdfoHT1 was actually rejected from NeurIPS 2014 due to lack of novelty 🧐 (true-ish), and lack of impact 🙃.
Thanks reviewer#2 (literally), and thanks for @arxiv!
@geoffreyhinton@JeffDean
DeepSeek [1] uses elements of the 2015 reinforcement learning prompt engineer [2] and its 2018 refinement [3] which collapses the RL machine and world model of [2] into a single net through the neural net distillation procedure of 1991 [4]: a distilled chain of thought system.
REFERENCES (easy to find on the web):
[1] #DeepSeekR1 (2025): Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2501.12948
[2] J. Schmidhuber (JS, 2015). On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models. arXiv 1210.0118. Sec. 5.3 describes the reinforcement learning (RL) prompt engineer which learns to actively and iteratively query its model for abstract reasoning and planning and decision making.
[3] JS (2018). One Big Net For Everything. arXiv 1802.08864. See also US11853886B2. This paper collapses the reinforcement learner and the world model of [2] (e.g., a foundation model) into a single network, using the neural network distillation procedure of 1991 [4]. Essentially what's now called an RL "Chain of Thought" system, where subsequent improvements are continually distilled into a single net. See also [5].
[4] JS (1991). Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991. First working deep learner based on a deep recurrent neural net hierarchy (with different self-organising time scales), overcoming the vanishing gradient problem through unsupervised pre-training (the P in CHatGPT) and predictive coding. Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills - such approaches are now widely used. See also [6].
[5] JS (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990, introducing high-dimensional reward signals and the GAN principle). Contains summaries of [2][3] above.
[6] JS (AI Blog, 2021). 30-year anniversary: First very deep learning with unsupervised pre-training (1991) [4]. Unsupervised hierarchical predictive coding finds compact internal representations of sequential data to facilitate downstream learning. The hierarchy can be distilled [4] into a single deep neural network. 1993: solving problems of depth >1000.
























![SchmidhuberAI's tweet photo. DeepSeek [1] uses elements of the 2015 reinforcement learning prompt engineer [2] and its 2018 refinement [3] which collapses the RL machine and world model of [2] into a single net through the neural net distillation procedure of 1991 [4]: a distilled chain of thought system.
REFERENCES (easy to find on the web):
[1] #DeepSeekR1 (2025): Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2501.12948
[2] J. Schmidhuber (JS, 2015). On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models. arXiv 1210.0118. Sec. 5.3 describes the reinforcement learning (RL) prompt engineer which learns to actively and iteratively query its model for abstract reasoning and planning and decision making.
[3] JS (2018). One Big Net For Everything. arXiv 1802.08864. See also US11853886B2. This paper collapses the reinforcement learner and the world model of [2] (e.g., a foundation model) into a single network, using the neural network distillation procedure of 1991 [4]. Essentially what's now called an RL "Chain of Thought" system, where subsequent improvements are continually distilled into a single net. See also [5].
[4] JS (1991). Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on TR FKI-148-91, TUM, 1991. First working deep learner based on a deep recurrent neural net hierarchy (with different self-organising time scales), overcoming the vanishing gradient problem through unsupervised pre-training (the P in CHatGPT) and predictive coding. Also: compressing or distilling a teacher net (the chunker) into a student net (the automatizer) that does not forget its old skills - such approaches are now widely used. See also [6].
[5] JS (AI Blog, 2020). 30-year anniversary of planning & reinforcement learning with recurrent world models and artificial curiosity (1990, introducing high-dimensional reward signals and the GAN principle). Contains summaries of [2][3] above.
[6] JS (AI Blog, 2021). 30-year anniversary: First very deep learning with unsupervised pre-training (1991) [4]. Unsupervised hierarchical predictive coding finds compact internal representations of sequential data to facilitate downstream learning. The hierarchy can be distilled [4] into a single deep neural network. 1993: solving problems of depth >1000.](https://pbs.twimg.com/media/Gioh8G8X0AAOdx8.jpg)
































