The fastest way to change your life is to rip yourself out of your (physical and digital) environment. Change everything overnight. The places you go, the accounts you follow, the info you consume, etc. It's difficult but it absolutely works.
She's 22 and a16z just led her $21M round. Her AI is live inside the Fortune 100.
"I work every waking second, 7 days a week, and I've never been happier."
17 minutes of an unreal story, from youngest hedge fund quant to funded founder in 2 years.
worth more than most of the startup advice on your feed.
watch it, then read the article below.
She's 22. Her AI runs inside the Fortune 100. a16z just led her $21M raise.
"Put up the most minimal fake version you probably can of something and then go sell it."
In 17 minutes, MIT grad Jessica Wu reveals the YC playbook that got her here in 24 months.
From youngest hedge fund quant to founder + the trick her batchmates missed + the Christmas Day deployment + the 10-year founder test
Worth more than a year of YC advice on your timeline
since a good bunch of discourse is going on around "how to do research", these pieces are quite worth a read.
https://t.co/pA0MkOMlKS
https://t.co/rw9uMiwlCj
https://t.co/H1AGvnb7LP
https://t.co/FTyAabr9Rx
Introducing Generative UI for Claude Code, Codex and Pi
Charts, forms, 3D, anything
Your agent renders real UI for users while it works in a sandbox
Powered by AI SDK's experimental HarnessAgent + json-render
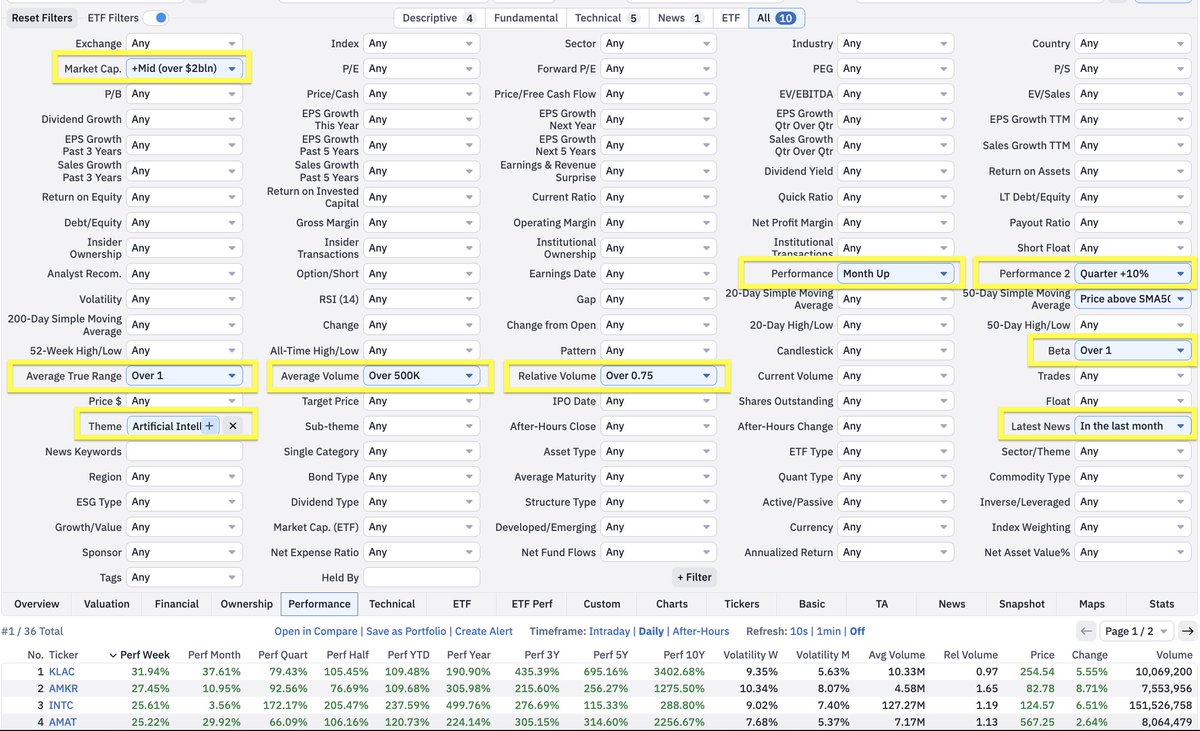
My high-level workflow for finding the strongest themes + scanning for which stocks to actually enter:
1)
- go to finviz, click maps in the nav bar
- click "themes" in the left panel
- select 1-week (or month) from the dropdown
- observe what's strongest/greenest
2)
- go back to the nav bar
- click screener
- click "theme" box
- scroll all the way down, click custom
- select the strongest themes from step 1
3)
- add supporting filters
- performance
- market cap
- relationship with moving avgs
-etc (see mine attached)
Super high level, but this should give you a good starting point.
- Luc
why you should create specific open and closed Hermes agent profiles
a profile is its own agent, with its own config, skills, memory, and model.
most users run everything through one default agent and set it up again each session.
so I build two kinds of profiles, open and closed. they work in opposite ways, explained here:
the open profile
this is your research agent, the one you open when you don't know what you'll need yet.
> lots of tools: web search, scrapers, transcription, doc parsing, and access to your past research
> research skills on top, like a /last30days that runs a whole sequence with one command
> output in whatever you need: markdown for briefs, json to feed other agents, html to read
its built to move fast and go down paths you didn't plan for.
the catch is cost, give it real room to explore and it burns a lot of tokens, and if the goal is loose it just makes slop fast. use it for one-off work, not for jobs that repeat.
the closed profile
this is the opposite, one job, kept narrow, run over and over. a good one has the same things you'd give a person doing that job:
> the context and data the job runs on
> what good looks like, and why
> the tools it can use, and what it must not touch
> a check at each step, and a human sign-off before anything ships
> memory, so each run makes the next one sharper
it runs on a schedule and on a normal budget, because the path is tight. and it gets better each run, because every pass feeds the next.
the depth comes from running the exact same setup over and over, and that only happens if you save it as a profile instead of rebuilding it each week.
one example I run watches around 15 accounts in my niche. it pulls the week's posts, finds the angles getting traction, and drops a report into the content brain. same setup every time, sharper every week.
once you have a few, they stop being separate tools. an orchestrator passes work between them, you manage them one by one or from a kanban board, and the whole set starts to run like an agent company.
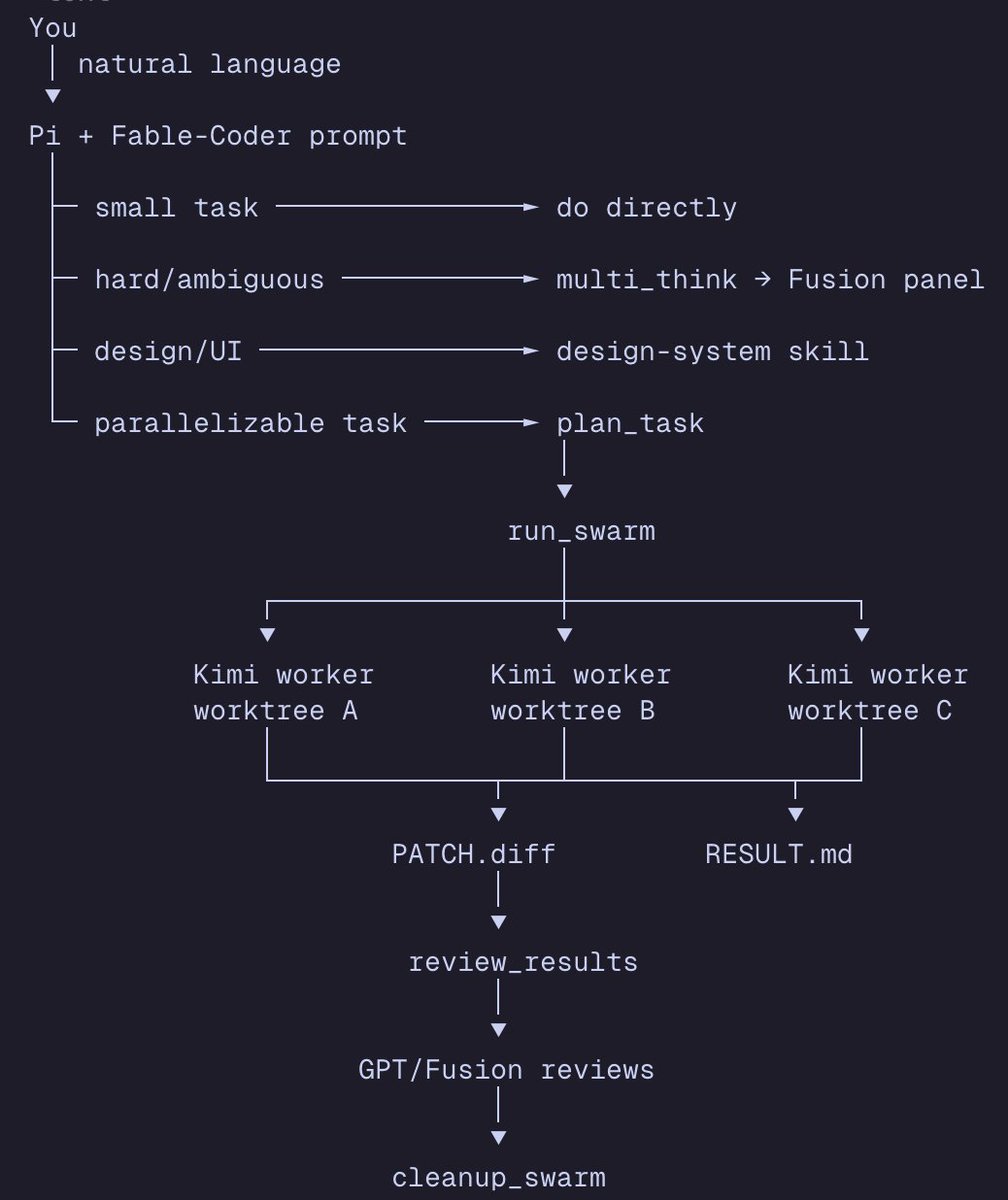
if you want Fable level performance NOW, the answer is to build your own coding harness
here's how I'm doing it
(in a lightweight Pi-native way rather than a heavy Superpowers/Compound clone)
first, I think we're going to see PERSONAL HARNESSES that derisk single model reliance, help users save money, and squeeze top frontier performance out of homegrown systems
The best engineers I know already do this...
1) Use Pi, the open source coding harness that you can make your own and access any model from
2) Set 5.5 codex as your default model
3) Deeply analyze publicly available system prompts (guess which model I looked at?)
4) Feed Codex context on Loop Engineering and other engineering skill repos
5) As it to improve efficiency as a lot of engineering repos are super heavy and bloated/slow
6) Ask it to use FUSION via Openrouter for planning, logic, and review tasks
7) Ask it to use Kimi k2.7 code for subagents/execution
8) Have it dog food the harness until it's dialed in then unleash it on a repo for a deep analysis
Here's the part that blew my mind:
In a real use case, you can start with ChatGPT, and switch the model to Claude midway.
As you can see in the demo below, I started with ChatGPT to ask about content creation, and in the middle I switched to Claude so I could get a proper answer without losing the context.
## On Loopcraft
One might argue the entire game of the next century is to be able to stack loops as effectively as possible.
In the early days of each phase, it will be valuable to know when to go **DOWN** a loop when things go wrong (for reliability)…
but it will probably be more valuable to know how to go **UP** a loop as models improve (for leverage).
If you don’t figure out how to do this, don’t be salty when you lose to those that do.
Anthropic's Claude Code engineer Sid Bidasaria:
"Stop babysitting your agents. If you're watching Claude work, you've already lost the leverage."
In 37 minutes, he shows how to set up agents that run without supervision, and the config below takes it to your phone.
Watch the talk, then grab the full setup below👇
Used @mattpocockuk /teach skill and gave it access to a chess engine and an API to fetch all of my recent games.
It now will fetch hundreds of my recent games, analyze them, then build custom lessons with visuals to help teach me mental models to improve the weakest points of my games. Interactive visuals, custom chess puzzles from my actual games, quizzes.
This is the new way to learn things.
“don’t train your own model” is common ai advice. it's wrong. your token bill's the proof.
today, we’re excited to launch castform into open preview. castform is the easiest way for you to train your own model, on your own data.
open-weights models are performant and much cheaper. when trained on your task & proprietary data, they beat closed models. the thing standing between you and that was weeks of plumbing & years of ml expertise.
with castform, model training is as simple as prompt engineering. @castformai
bring your agent traces or raw corpora. castform turns it into training data, picks the right algorithmic recipes, manages gpus, and gives you an ide to watch and chat with your model as it learns.
see what you can build with castform👇
luckily bookmark rot is an easy problem to fix now
here's how to turn every X bookmark you've ever saved into a second brain your agent has full context on:
1. export your bookmarks. i use twitter-web-exporter (free userscript) or the BookmarkSave extension. you get one file with every bookmark + the full text + the author + the link
2. drop that file into a folder. if you already run an llm wiki / obsidian vault, drop it straight in so your bookmarks join the rest of your knowledge
3. point your agent at the folder (claude code, codex, hermes, whatever you run) and tell it: "read this export and turn every bookmark into its own markdown note with the original link and a couple of topic tags"
that's it, your agent has read all of it.
now you can ask "what have i saved about pricing" or "pull everything i bookmarked on claude code" and it answers across the whole pile
takes maybe 10 minutes
after that they actually get used, and every new bookmark folds into the same brain instead of rotting in a tab you never open again