When deploying voice agents, users notice latency above 500ms. Above one second, they hang up. @rish_bhargava walks through the full pipeline at that level of specificity, including why 75ms of network latency adds 30% overhead and how colocating everything drops it to 5ms. https://t.co/s6yqpFpsaA
MiniMax-M3 from @MiniMax_AI is now available on Together AI.
It’s an open-weight native multimodal model with 1M context, MiniMax Sparse Attention, and thinking / non-thinking modes.
Together AI is MiniMax’s preferred cloud partner, with inference optimizations delivering up to 125% higher throughput across concurrency levels.
Frontier model performance on an open model, post-trained in under 24 hours. @trajectorylabs is showing what's possible when great open models meet the right training infrastructure. Proud to power the compute behind this work alongside @nvidia .
I asked 8 AI models (including Fable 5) for their world cup predictions.
Going to keep an updated leaderboard based on match results to see which AI model performed the best!
Launching tomorrow, right before the world cup kicks off!
As vertically integrated platforms start to dominate they lock out third party access to the most valuable portions of the platform.
Of course, Anthropic is has the right to implement whatever policy they want. But this is why open-weights are critical for human progress.
The best AI infrastructure shouldn't be reserved for the biggest companies. Together AI is partnering with @pax8 to bring powerful, cost-efficient AI and leading open-source models to small and mid-sized businesses worldwide.
https://t.co/fxib9K20DE
PSA: Just added a few thousand chips, including B200s and B300s to our Dedicated Model Inference (https://t.co/PiJhHYHVZh).
With Dedicated Model Inference, you can now on-click deploy our Blackwell optimized inference engine with auto-scale on frontier OSS models including Nemotron, Minimax, Kimi, DeepSeek, GLM and Qwen.
MiniMax-M3 combines 1M context, native multimodality, and MiniMax Sparse Attention.
The next layer is serving it efficiently: KV-block-major sparse attention, paged MSA decode, optimized index scoring, and multimodal preprocessing before the GPU worker.
Together’s Inference and Kernel teams improved throughput by 81–125% across common agentic-shape traffic.
We go deeper in this deep dive from @ywangfirstlean, @zhyncs42, @realDanFu and the team.
MiniMax M3 is live and Together AI is powering its inference 🚀
Tomorrow at 6pm PT we're going live on X Spaces with the teams behind the model and the infrastructure to give you a deep dive.
https://t.co/wPayfOWmNg
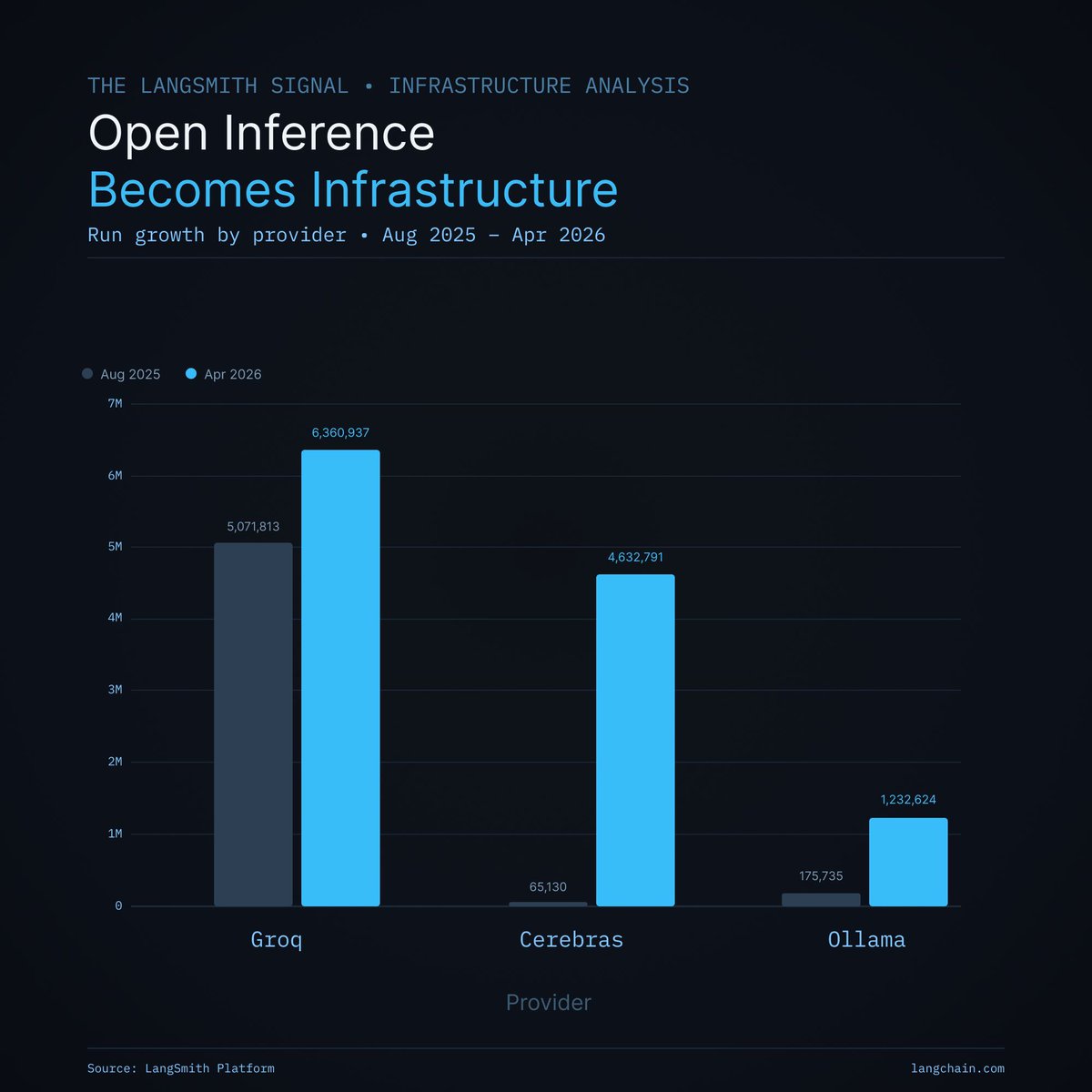
The latest finding in the LangSmith Signal: Open Models are having a moment.
1 in 3 AI teams ran an open-weights model in April 2026, up from 1 in 5 nine months ago.
The overall number of teams using open weights grew 3x.
We’re seeing newer users choose open models at a higher rate than those who came before.
We took the Hot Wings Challenge to NVIDIA GTC 🌶️
@realDanFu (VP of Kernels) and @sarung (VP of Customer Success) answered some questions around AI, one spicy wing at a time.
Some people sweat. Some people talk. Watch to see who did both.
Together AI serves the two fastest STT models measured by @ArtificialAnlys
NVIDIA Parakeet-TDT 0.6B v3 can transcribe 20 hours of speech in under 10 seconds.
This deep dive shows the systems work behind the leaderboard: TensorRT profiles, conditional CUDA graphs, evented I/O, shared memory, and Python GC control.
The best research labs are building what comes after static models. Congrats to @trajectorylabs on the launch! Excited to have them training on the AI Native Cloud as they push the frontier on Continual Learning!
Our inference stack, optimized for Blackwells, with a novel attention kernel and many new optimizations has started rolling out!
It's already charting on Artificial Analysis, eg: #1 speed and latency for @Kimi_Moonshot Kimi 2.6. #1 on latency on @MiniMax_AI, and miles ahead of other GPU endpoints.
https://t.co/Yx6rIcZPyk
https://t.co/AdORQ3GLu9
Introducing Qwen3.7-Max from @Alibaba_Qwen, Qwen’s flagship model for the agent era with 1M context and leading performance across agentic coding, reasoning, and long-horizon autonomy.
AI natives can now use Qwen3.7-Max on Together Serverless Inference for production-scale agent workflows.
"One thing that we've been seeing recently is that inference benchmarks don't really match production workloads that well." - @realDanFu, VP of Kernels
When you're running dozens of concurrent coding agents — each with 45k–200k token contexts — the benchmarks that matter are the ones that stress KV cache, scheduler limits, and throughput under real load.
We ran those benchmarks. Our Inference Engine delivered:
→ 31% higher TPS than the next fastest OSS engine
→ 2× better time-to-first-token at saturation
→ 76% lower cost per request vs. Claude Opus 4.6
Read the full technical breakdown → https://t.co/KPUq4jYAFH
Congrats to the @cursor_ai team on Composer 2.5 — a huge milestone for agentic coding models.
Together AI, the AI Native Cloud, is proud to partner on this launch. Composer 2.5 is pushing the frontier for coding agents and turning heads for its speed and quality.
Excited to keep building with the Cursor team!