People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
To train better open models, we need predictable scaling.
Delphi is Marin’s first step: we pretrained many small models with one recipe, then extrapolated 300× to predict a 25B-param / 600B-token run with just 0.2% error.
Getting there took some work 🧵
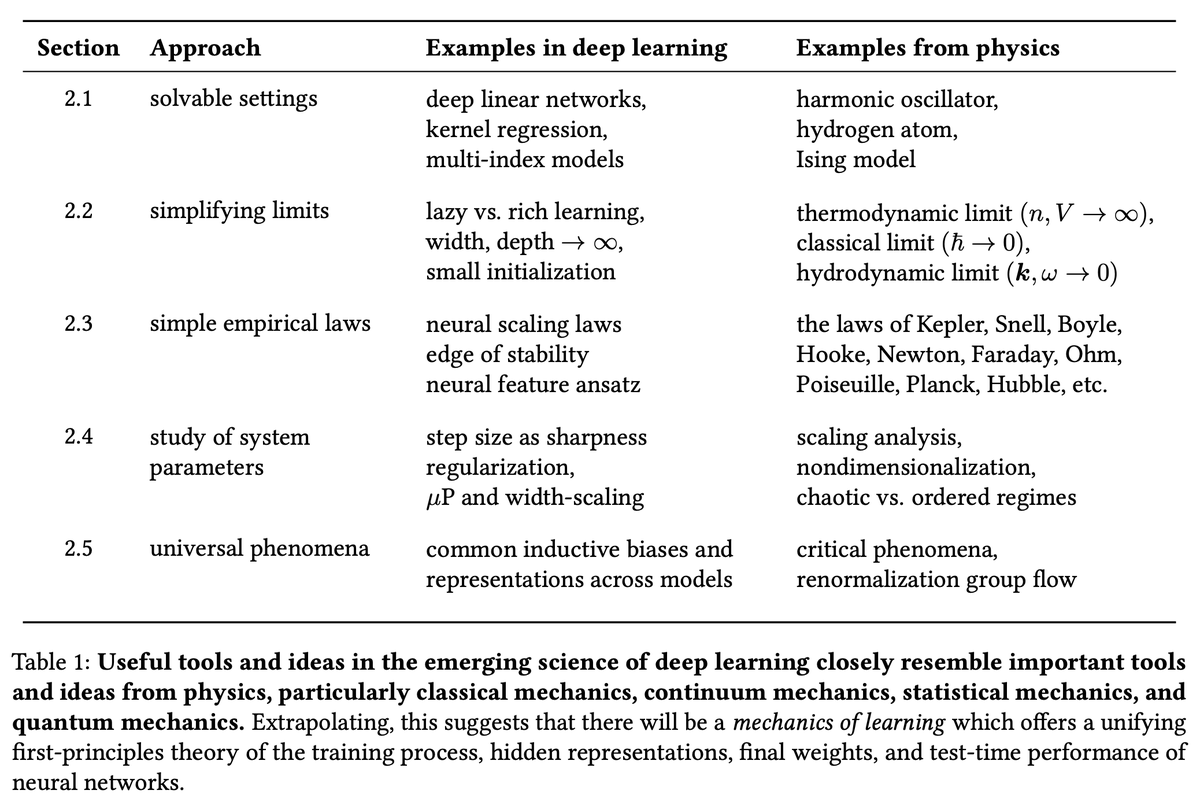
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 https://t.co/92nSIHameW 🔧
Model shaping is still a craft of a few. That's what AI agents are for: learning it and doing it for everyone else.
As a part of FrontierSWE benchmark we built a 20-hour post-training task on @tinkerapi and found the real bottleneck is research intuition.
@littewhite16806 most interesting part of this little project was writing a selenium verifier to 16personalities site and letting llm answer 5 scale questions haha
@littewhite16806 your work is totally unique and kind of opposite to mine! while you prune and prove personas already exist in your model (which sounds about right), i tried to train Lora’s that show composition of persona😄
🧵 Decomposing the Delta: What Do Models Actually Learn from Preference Pairs?
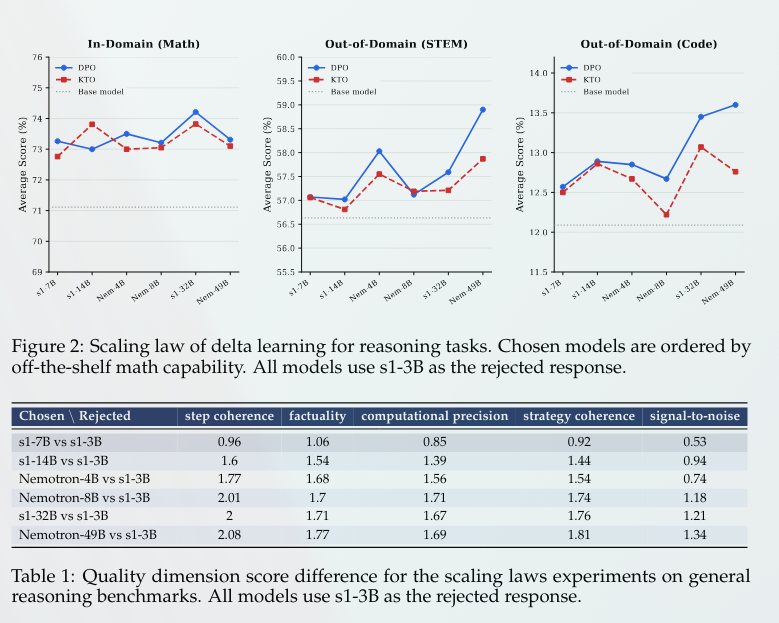
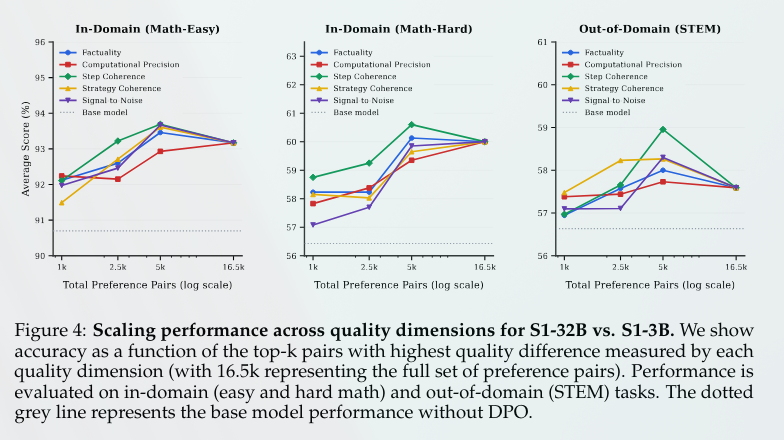
1/n 💡 Why do methods like DPO and KTO actually improve reasoning? In standard alignment, we use preference pairs, but we don't fully understand what properties of the data drive downstream gains.
We investigate two distinct notions of quality: Generator-level Delta - the capability gap between the models producing the chosen vs. rejected traces
Sample-level Delta - The fine-grained quality difference within a single pair (Factuality, Coherence, Precision)
👇
This paper digs into what actually makes delta learning work. The authors show that it’s not just about the chosen trajectory being correct relative to the rejected one. What drives the gains is the coherence of reasoning across the trajectory.
🔗https://t.co/TSEllrOdxN