Now in press at @bbsjournal, a new paper co-authored with @nicolasporot and @Ericmandelbaum.
We provide a sustained defense of the Language of Thought Hypothesis (LoTH).
1/26
https://t.co/NraClhou1M
A new preprint, co-authored with
@blamlab:
The Deliberation Taboo
Cognitive science is, nominally, the science of thinking. We argue that the field has no theory of what thinking is and, even worse, that the topic has largely dropped out of focus. 1/
@byrd_nick this is the topic of the paper so i would point you to the arguments we make about how that literature handles deliberation - have you read it, or just looked at the references?
We point to some threads, including the role of negation, compression of information, symbolic structures as a scaffold, and individual differences. But these are educated guesses. Our goal is to encourage the field to see deliberation as an enormous outstanding problem. 10/10
New paper coming out in PPR: "Consciousness doesn't do that". I explain why I believe that animal sentience research is in large part built on sand. In my opinion, we should be skeptical of many of the claims made in this field. https://t.co/56aqaLFkBq
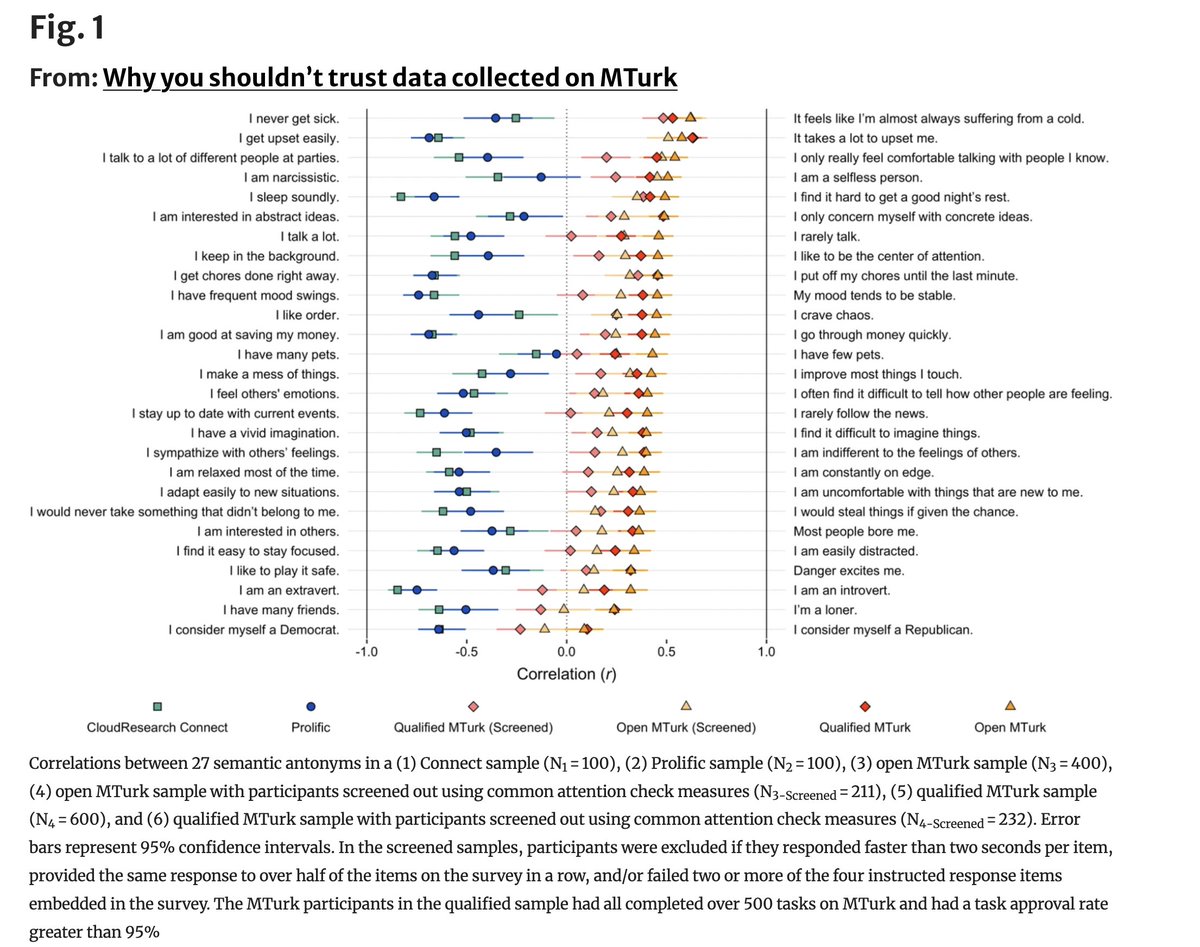
“These findings provide clear evidence that data collected on MTurk simply cannot be trusted.”
Researchers have long argued about whether Amazon Mechanical Turk (MTurk) survey data can be trusted.
This paper takes a simple approach to evaluating the quality of data currently produced by MTurk.
The author gives respondents pairs of questions that are obviously contradictory.
For example:
"I talk a lot" and "I rarely talk."
Or:
"I like order" and "I crave chaos."
If people are paying attention, agreeing with one should mean disagreeing with the other. At minimum, the two answers shouldn’t move together.
The same exact survey is fielded on three platforms: Prolific, CloudResearch Connect, and MTurk.
On Prolific and Connect, things behave normally: most contradictory items are negatively correlated, just as common sense predicts.
On MTurk, however, the results are the opposite.
Over 96% of these clearly opposite item pairs are positively correlated. In other words, many respondents give similar answers to statements that literally contradict each other.
The authors then try what most researchers would do next:
-restrict the sample to "high-reputation" MTurk workers
-apply standard attention checks
-drop fast responders and straight-liners
None of it fixes the problem. Even after aggressive screening, many contradictory items remain positively correlated on MTurk.
The implication is severe: careless responding on MTurk isn’t rare noise; it’s systematic enough to flip the sign of relationships and generate results that are the opposite of what they really are.
Wow; this is damning.
This paper from Harvard and MIT quietly answers the most important AI question nobody benchmarks properly:
Can LLMs actually discover science, or are they just good at talking about it?
The paper is called “Evaluating Large Language Models in Scientific Discovery”, and instead of asking models trivia questions, it tests something much harder:
Can models form hypotheses, design experiments, interpret results, and update beliefs like real scientists?
Here’s what the authors did differently 👇
• They evaluate LLMs across the full discovery loop hypothesis → experiment → observation → revision
• Tasks span biology, chemistry, and physics, not toy puzzles
• Models must work with incomplete data, noisy results, and false leads
• Success is measured by scientific progress, not fluency or confidence
What they found is sobering.
LLMs are decent at suggesting hypotheses, but brittle at everything that follows.
✓ They overfit to surface patterns
✓ They struggle to abandon bad hypotheses even when evidence contradicts them
✓ They confuse correlation for causation
✓ They hallucinate explanations when experiments fail
✓ They optimize for plausibility, not truth
Most striking result:
`High benchmark scores do not correlate with scientific discovery ability.`
Some top models that dominate standard reasoning tests completely fail when forced to run iterative experiments and update theories.
Why this matters:
Real science is not one-shot reasoning.
It’s feedback, failure, revision, and restraint.
LLMs today:
• Talk like scientists
• Write like scientists
• But don’t think like scientists yet
The paper’s core takeaway:
Scientific intelligence is not language intelligence.
It requires memory, hypothesis tracking, causal reasoning, and the ability to say “I was wrong.”
Until models can reliably do that, claims about “AI scientists” are mostly premature.
This paper doesn’t hype AI. It defines the gap we still need to close.
And that’s exactly why it’s important.
This is an excellent interview/discussion for those who want to know more about our current moment with AI, the economy, and energy. https://t.co/zMpFP3y6dV