GPUs are unreliable at scale.
At @modal we've scaled to 20,000+ concurrent GPUs across AWS, GCP, Azure, and OCI, with 1M+ instances launched. Public-cloud GPUs fail in many ways, and we’ve seen most of them.
Here’s how we handle GPU reliability 👇
Two days since DFlash was released, and @_dcw02 (on @modal research) already shipped support for it in SGLang.
Why are we so excited about this?
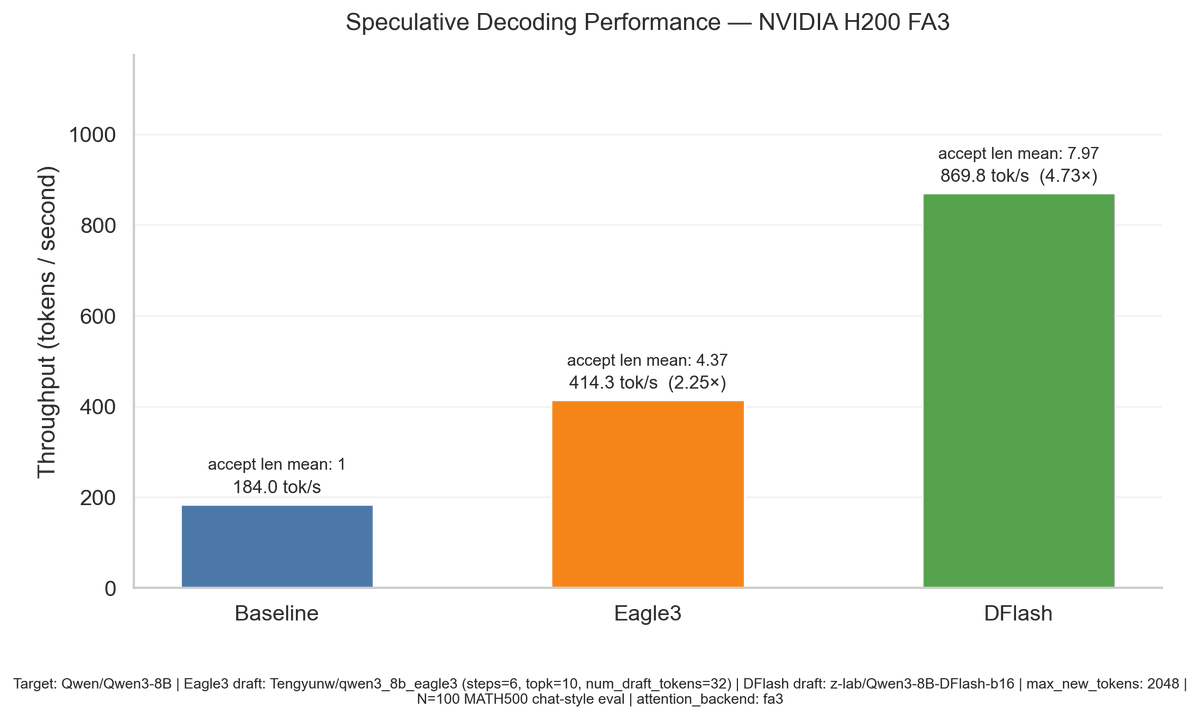
Diffusion speculators let us get *way* higher tok/s than auto-regressive models. E.g. we're seeing a 4.73x boost with H200s + FA3 already — with still more improvements to come!
Reach out to us if we can help you get this in prod today, and huge thanks to @zhijianliu_ and team for coming up with this technique.
Two days since DFlash was released, and @_dcw02 (on @modal research) already shipped support for it in SGLang.
Why are we so excited about this?
Diffusion speculators let us get *way* higher tok/s than auto-regressive models. E.g. we're seeing a 4.73x boost with H200s + FA3 already — with still more improvements to come!
Reach out to us if we can help you get this in prod today, and huge thanks to @zhijianliu_ and team for coming up with this technique.
Founding Beacon with @nilamg has been the most intense but also fulfilling time of my life. In just a year, we’ve grown to a team of 30+ and acquired dozens of mission-critical software businesses that quietly power everyday life, helping them bring AI to real-world industries.
We are deeply thankful to the entrepreneurs who have entrusted us with their life’s work and our partners at General Catalyst, Lightspeed, D1 Capital, MSD & BDT, and Sator Grove, along with our angels and advisors.
This $250M Series B fundraise enables us to increase the scale of our ambitions to build a generational AI holding company.
We are hiring across many roles! Check out our careers page.
Founding Beacon with @nilamg has been the most intense but also fulfilling time of my life. In just a year, we’ve grown to a team of 30+ and acquired dozens of mission-critical software businesses that quietly power everyday life, helping them bring AI to real-world industries.
We are deeply thankful to the entrepreneurs who have entrusted us with their life’s work and our partners at General Catalyst, Lightspeed, D1 Capital, MSD & BDT, and Sator Grove, along with our angels and advisors.
This $250M Series B fundraise enables us to increase the scale of our ambitions to build a generational AI holding company.
We are hiring across many roles! Check out our careers page.
Write deep learning code on your laptop and run it instantly on GPUs - that's every developer/reseachers dream
@thinkymachines offers this with Thinker
You can do something similar by just using @modal right now !!
I’ve written a blog + hands-on tutorial breaking down how you can train, fine-tune, and deploy LLMs/VLMs on GPUs in scalable manner without worrying much about infra
It's true – @modal has raised a $87M Series B at a $1.1B valuation to advance the future of AI infrastructure.
Thank you to @Lux_Capital, @Redpoint, @AmplifyPartners, and others.
Now more than ever, AI demands a complete reinvention of traditional compute infrastructure
We're thrilled to share Modal Notebooks: a new, powerful cloud-hosted GPU notebook. It has modern real-time collaborative editing and is backed by our AI infrastructure — swap GPUs in seconds.
Modal Notebooks are generally available, and you can start using them now. 🧵
I like making GPUs go brrt at @modal.
I wrote up what I've learned along the way in an extension to the GPU Glossary -- our "CUDA Docs for Humans".
Introducing: the GPU 𝔓𝔢𝔯𝔣𝔬𝔯𝔪𝔞𝔫𝔠𝔢 Glossary.
https://t.co/9IDfgGqVFX
At @modal we've built every layer of the AI infra stack from scratch — from filesystems and networking to our own async queues and multi-cloud GPU orchestration.
I sat down with @narayanarjun from @amplifypartners to go into depth on all of this, including the fun ways the Linux kernel has tried to stop us along the way: